

更新时间:2025-12-17 GMT+08:00
使用Ray进行小模型推理
场景描述
小模型推理通常指的是在相对较小的机器学习模型上进行推理的过程。这些模型可能由于模型复杂度较低、参数量较少等原因,在单个计算节点上就能高效运行。然而,当需要处理的数据量非常大时,即使是小模型也可能面临性能瓶颈。此时,使用Ray进行并行和分布式推理能帮助您提升推理性能。
在DataArts Fabric上使用全托管Ray服务进行小模型推理时,您只需要将您的小模型推理过程定义为Ray可执行的任务,同时在DataArts Fabric中创建推理Job并运行,即可开启推理任务。
前提条件
步骤一:准备代码脚本
以下面Python代码脚本为例,创建一个推理作业,做简单的线性回归模型推理,再使用Ray的分布式调度能力计算出推理结果。您可以参照以下示例创建自己的脚本用于后续的推理任务。
- simple_model.py模型定义及启动模型脚本。脚本定义了一个线性回归的模型SimpleModel,并定义了模型部署serve。
# simple_model.py from sklearn.linear_model import LinearRegression import numpy as np import pickle import ray from ray import serve from fastapi import FastAPI, Request from ray.serve.handle import DeploymentHandle app = FastAPI() class SimpleModel: def __init__(self): self.model = LinearRegression() X = np.array([[1, 1], [1, 2], [2, 2], [2, 3]]) y = np.dot(X, np.array([1, 2])) + 3 self.model.fit(X, y) def predict(self, X): return self.model.predict(X).tolist() model_instance = SimpleModel() @serve.deployment(name="simple_model_deployment", ray_actor_options={"num_cpus": 1}) @serve.ingress(app) class SimpleModelDeployment: def __init__(self, model: DeploymentHandle): self.model = model @app.post("/predict") async def predict(self, request: Request): request_data = await request.json() input_data = np.array(request_data).reshape(-1, 2) prediction = self.model.predict(input_data) return {"prediction": prediction} deployment_instance = SimpleModelDeployment.bind(model=model_instance) serve.run(deployment_instance) - infer_client.py客户端调用主入口脚本。主要流程为调用模型脚本部署模型,然后将数据输入模型进行推理,最后将推理结果上传至OBS。脚本中需要传入必选的-ak、-sk、-ep、-dp参数。
- -ak是OBS的AK,详情请参见OBS的AK/SK。
- -sk是OBS的SK,详情请参见OBS的AK/SK。
- -ep是OBS Endpoint,详情请参见OBS Endpoint。
- -dp是推理输出文件存储在OBS的路径及文件名。
# client.py import requests import numpy as np from obs import ObsClient from urllib.parse import urlparse import argparse from dataclasses import dataclass import os from ray import serve import subprocess import multiprocessing import time import ray input_file_path = './input.txt' output_file_path = './output.txt' def run_model(): # serve run simple_model:deployment_instance subprocess.run(['python3', './simple_model.py']) @dataclass(frozen=True) class ParsedObsPath: bucket_id: str key_id: str def do_inference(): input_data = [] with open(input_file_path, 'r') as f: for line in f: parts = line.strip().split() input_data.append([float(parts[0]), float(parts[1])]) input_data_array = np.array(input_data).tolist() print(f"input_data_array={input_data_array}") response = requests.post("http://localhost:8000/predict", json=input_data_array) print(f"response: {response}") predictions = response.json()["prediction"] with open(output_file_path, 'w') as f: for prediction in predictions: f.write(f"{prediction}\n") print(f"result save in: {output_file_path}") def parse_obs_uri(path: str) -> ParsedObsPath: if not path.startswith('obs://'): raise Exception(f'OBS path format incorrect: "{path}"') parsed = urlparse(path) return ParsedObsPath(bucket_id=parsed.netloc, key_id=parsed.path[1:]) def upload_file_to_obs(obs_client: ObsClient, obs_path: str, source_path: str): if not os.path.exists(source_path): raise Exception( f'Source file is not exist: source_path={source_path}') uri = parse_obs_uri(obs_path) # ObsClient.putFile(bucketName, objectKey, file_path, metadata, headers, progressCallback) print(f"bucket_id={uri.bucket_id}, key_id={uri.key_id}, source_path={source_path}") result = obs_client.putFile( bucketName=uri.bucket_id, objectKey=uri.key_id, file_path=source_path ) return result def main(): parser = argparse.ArgumentParser() parser.add_argument("-ak", "--access_key_id", help="OBS access key", type=str, required=True) parser.add_argument("-sk", "--secret_access_key", help="OBS secret key", type=str, required=True) parser.add_argument("-st", "--security_token", help="OBS security token", type=str, required=False) parser.add_argument("-ep", "--endpoint", help="OBS entrypoint", type=str, required=True) parser.add_argument("-dp", "--dst_path", help="Local filesystem destination path", type=str, required=True) args = parser.parse_args() obs_client = ObsClient( access_key_id=args.access_key_id, secret_access_key=args.secret_access_key, security_token=args.security_token, server=args.endpoint, signature='obs' ) # run model print("start run model") background_process = multiprocessing.Process(target=run_model) background_process.start() # wait ray serve ready time.sleep(20) # do inference print("start do inference") do_inference() # upload infer result to obs print("start upload result to obs") upload_result = upload_file_to_obs( obs_client=obs_client, obs_path=args.dst_path, source_path=output_file_path ) print(f"upload result={upload_result}") if not upload_result.status < 300: raise Exception('Error while uploading to OBS.' f' upload status: {upload_result.status}') ray.shutdown() if __name__ == "__main__": main() - input.txt推理输入。
3.0 5.0 1.0 2.0 4.0 6.0 2.0 3.0
步骤二:将代码脚本上传至OBS桶
- 登录华为云控制台,在页面左上角单击
 ,选择“存储 > 对象存储服务 OBS”,进入OBS服务。
,选择“存储 > 对象存储服务 OBS”,进入OBS服务。 - 将步骤一创建的代码脚本上传至OBS桶,详情请参见使用OBS桶上传对象。
- 脚本上传成功后,可在OBS桶中查看到已上传的脚本。后续在创建Ray作业时可以选择脚本使用。
例如,将Job脚本上传至obs://fabric-job-test/rayJob/ray-job/RayInferDemo2目录下。
图1 OBS桶上传脚本成功示例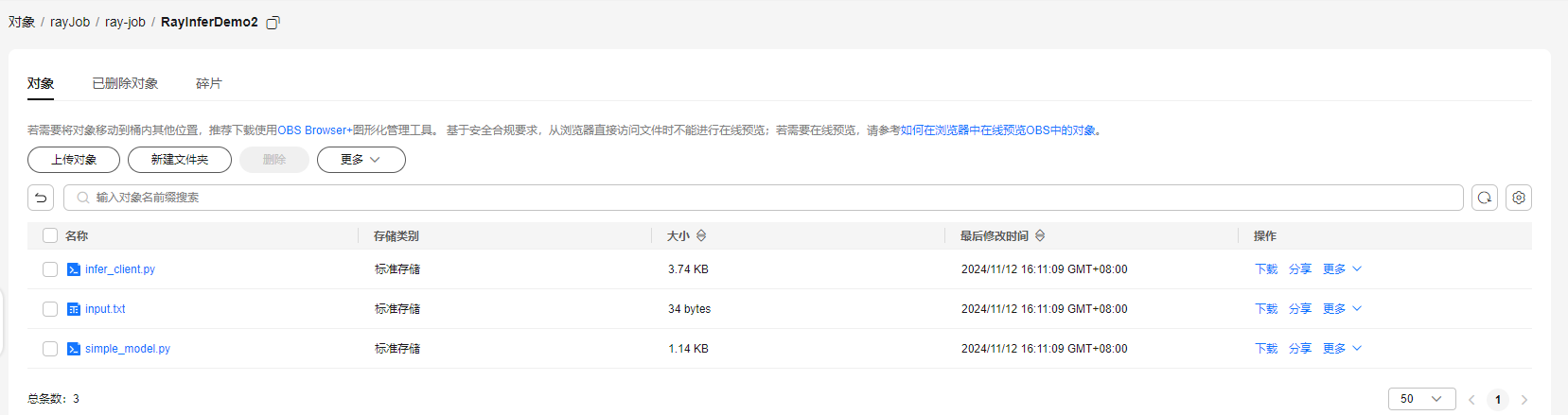
步骤三:创建一个推理的Job
- 登录DataArts Fabric工作空间管理台,选择已创建的工作空间,单击“进入工作空间”。
- 在左侧导航栏,单击“Job定义”,然后在右上角单击“创建作业”。具体操作,请参见创建Job。
表1 配置说明 配置项
说明
代码目录
选择步骤二:将代码脚本上传至OBS桶中上传的路径,例如obs://fabric-job-test/rayJob/ray-job/RayInferDemo2 。
Ray主文件
选择整个Job的主入口脚本,例如infer_client.py。
Ray作业参数
填写主入口脚本所需参数。ak/sk获取请参考OBS的AK/SK,ep获取请参考OBS Endpoint。示例如下:
-ak XXXXXXXXXXXXXXX -sk xxxxxxxxxxxxxxxx -ep obs.cn-north-7.huawei.com -dp obs://fabric-job-test/test_output/output.txt
依赖库
填写依赖及版本。多个依赖需要换行填写。示例如下:
scikit-learn==1.5.2 numpy==1.19.5
图2 创建Job配置示例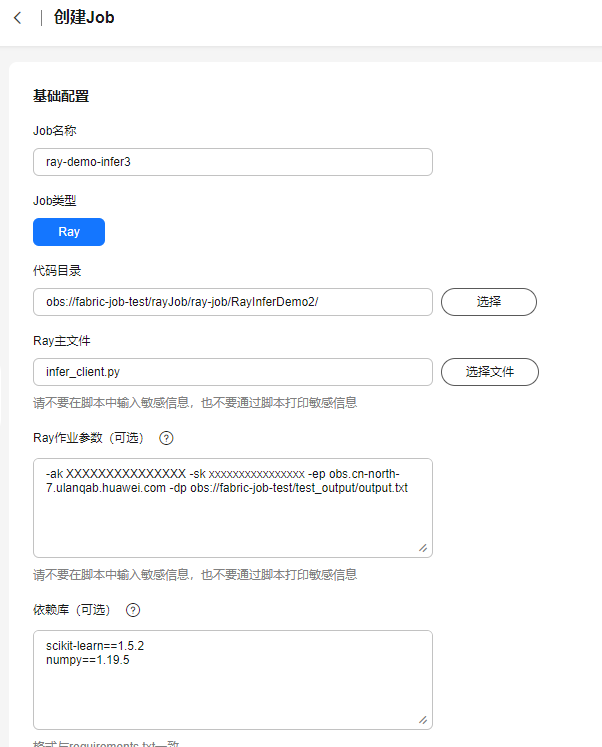
步骤四:运行Job
- Job定义完后,确认Job已选择可用的Ray集群,在“Job定义”的“操作”列,单击目标Job对应的“启动”。 图3 启动Job

- 在“Job定义”的“操作”列,单击目标Job对应的“运行详情”,然后单击“运行”页签,查看Job运行状态。 您可以在运行参数中指定的输出OBS桶路径中查看输出。图4 在OBS桶路径中查看输出





