

选择并配置模型
在Versatile中,创建智能体后配置模型是构建和优化智能应用的关键操作,用户可以通过可视化配置页面选择和集成多种大语言模型,如盘古、DeepSeek、千问等。通过灵活选择和配置不同大语言模型,确保智能体能够根据业务需求高效、稳定地提供强大的AI能力。
前提条件
Versatile已接入模型。接入模型服务详见接入模型服务。
选择模型
您可以在智能体的编排页面为智能体选择一个合适的大模型。选择模型并完成智能体的技能、知识等设置后,你也可以切换成不同的模型,测评各个模型在同一个智能体中的效果,选择最合适的模型。
- 登录Versatile智能体平台,在左侧导航栏“个人空间”区域,选择目标空间。
- 在左侧导航栏中选择。
- 在“单智能体应用”页面选择已创建的单智能体。
- 在智能体页面右上角,单击模型模块下拉框,选择模型。
图1 选择模型
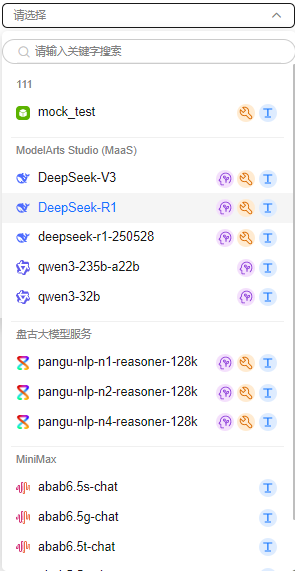

模型的标签展示顺序从左到右依次是用户自定义标签、接入模型时的“选择标签”、“模型类型”。
- 接入模型时的“选择标签”:
 联网:表示该大模型具备联网搜索能力。
联网:表示该大模型具备联网搜索能力。 思考:表示该大模型具备思维推理能力。
思考:表示该大模型具备思维推理能力。 工具:表示该大模型支持应用调用外部工具,例如,MCP服务、插件、知识库等。
工具:表示该大模型支持应用调用外部工具,例如,MCP服务、插件、知识库等。- default-import:表示该大模型是系统默认模型。
- 免费:表示该平台预置大模型可免费使用。
- 体验:表示该平台预置大模型可以体验,会话轮数最大为20次。
- “模型类型”包含:
 文本:表示该大模型是文本对话类型。
文本:表示该大模型是文本对话类型。 视觉:表示该大模型是图像理解类型。
视觉:表示该大模型是图像理解类型。 嵌入:表示该大模型是文本向量化类型。
嵌入:表示该大模型是文本向量化类型。 排序:表示该大模型是文本排序类型。
排序:表示该大模型是文本排序类型。
- 模型状态:
- 未验证:表示该大模型未检验鉴权信息,不可使用。
- 成功:表示该大模型鉴权信息校验成功,可以使用。
- 失败:表示该大模型鉴权信息校验失败,不可使用。
- 接入模型时的“选择标签”:
调整模型生成倾向
可以从多个维度调整不同模型在生成内容时的随机性和多样性。平台提供以下预置的模式供您选择,每个模式的模型参数取值不同。
- 精确的:严格遵循指令要求生成内容,适合正式文档、代码等。
- 平衡的:模型生成内容处于严谨和创意的平衡,适合大多数场景。
- 创意性的:生成内容偏向创意独特,适合头脑风暴、创作场景。
- 自定义:你也可以根据需求,选择“自定义设置”,修改每个模式下的具体参数值。建议不要同时调整生成温度和核采样,以免在多参数的影响下难以判断每个参数的调整效果。
|
配置项 |
说明 |
|---|---|
|
温度 |
单击“模式选择”后的下拉箭头可展示温度参数。 即temperature,用于控制结果的随机性。 调高温度会使得模型的输出更多样性和创新性,反之,降低温度会使输出内容更加遵循指令要求但减少多样性。建议不要与核采样同时调整。 |
|
核采样 |
单击“模式选择”后的下拉箭头可展示核采样参数。 模型在输出时会从概率最高的词汇开始选择,直到这些词汇的总概率累积达到核采样值,这样可以限制模型选择这些高概率的词汇,从而控制输出内容的多样性。建议不要与温度同时调整。 |
|
深度思考 |
显示该参数有以下两个场景:
该参数支持以下操作:
注意:
在模型使用过程中,“深度思考”开关生效的情况如下:
|
|
历史对话轮数 |
设置带入模型上下文的对话历史轮数,轮数越多相关性越高。参数取值1~20。 |
|
最大回复长度 |
用于控制聊天回复的长度和质量。一般来说,最大回复长度值设置较大,生成较长和较完整的回复,同时会增加生成无关或重复内容的风险。较小的最大回复长度值可以生成较短和较简洁的回复,但可能导致生成不完整或不连贯的内容。因此,需要根据不同的场景和需求来选择合适的最大回复长度值。 |
|
重复语句惩罚 |
用于阻止模型频繁使用相同的词汇和短语,取值范围为-2~2。
|
|
模型高级配置 |
当配置智能体调度模式选择为“工具优先”时,可配置“模型高级配置”。
|




