

加速原理与安装AITurbo SDK
背景
当前,大模型训练往往使用成百上千加速卡训练几周到几个月不等。在训练过程中,故障导致训练中断经常发生。训练程序一般采用周期 checkpoint方案来将训练状态持久化到存储,当发生故障时,训练程序能恢复到故障之前的模型和优化器的状态继续训练。原生Pytorch系框架在保存checkpoint时均直接持久化到存储系统,耗时与模型大小、存储的IO性能等密切相关,往往需要几分钟到几十分钟不等,为了保证训练状态的一致性,保存checkpoint时训练必须暂停,保存时间影响了训练过程的整体效率。当发生故障,训练程序从已有checkpoint恢复时,每张卡都需要从持久化存储中加载,在训练集群规模较大,存储带宽较低的场景下,加载耗时可能会达到小时级,严重影响训练恢复。因此,我们在AITurbo SDK中提供了快速保存和加载checkpoint的功能,当前流行的两种大模型训练框架Megatron和DeepSpeed进行很简单地适配便可使用。
加速保存checkpoint
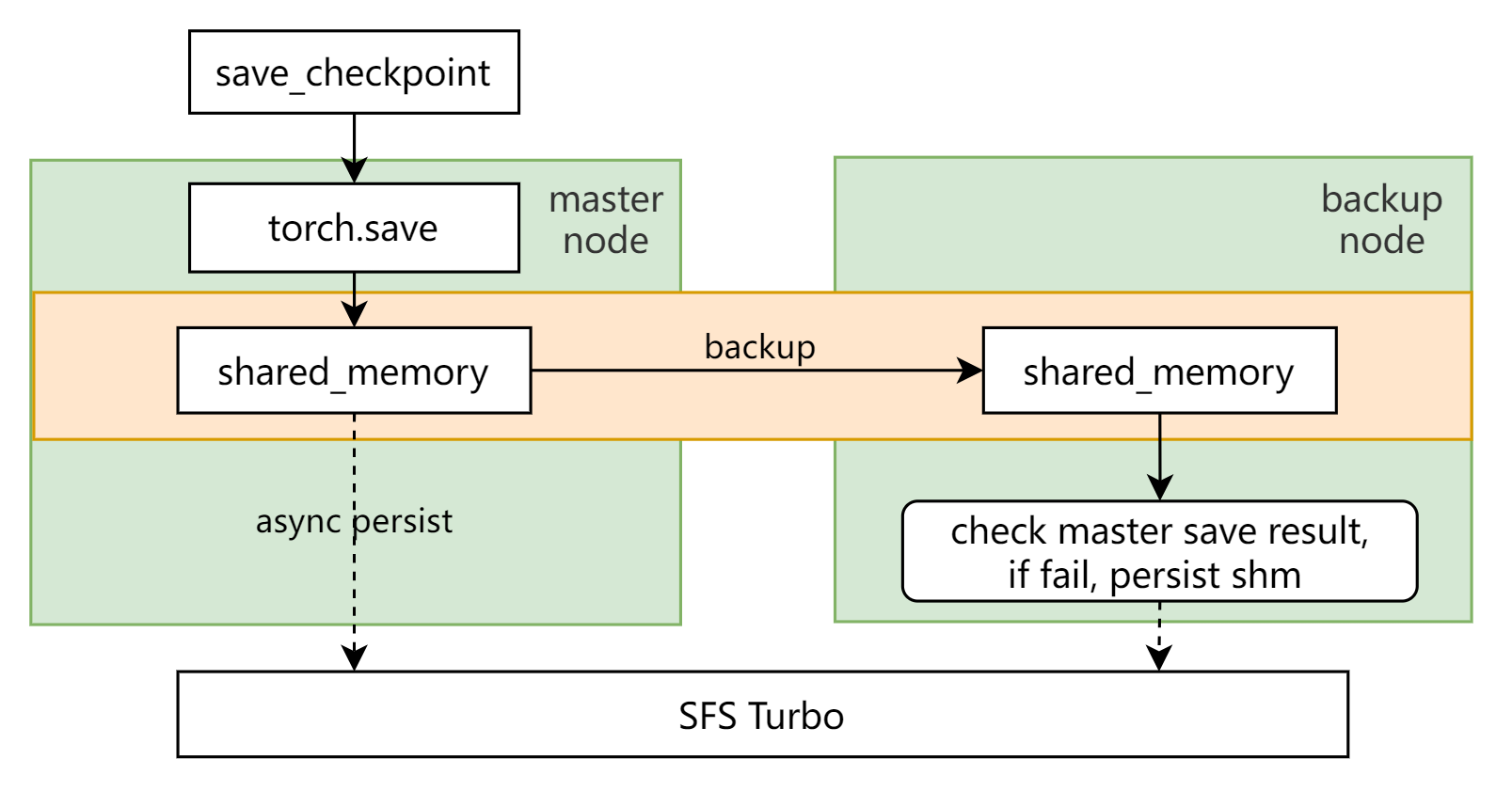
在保存checkpoint的时候,利用两阶段写、内存副本、异步持久化等技术保证checkpoint的快速、高可靠存储。具体地,第一阶段,各个节点将自己的checkpoint高速同步写入HOST侧的内存缓存中,同时写入配置好的backup节点内存缓存中,backup的内存副本可以在主节点进程异常退出时不会丢失内存checkpoint;第二阶段,拥有相同checkpoint的节点会选择代表节点异步写一份完整的checkpoint到SFS Turbo服务端进行持久化存储,通过异步方式最大程度隐藏了checkpoint持久化到远端存储的耗时,实现checkpoint秒级同步保存,避免训练任务长时间阻塞,异步保存阶段,主节点持久化过程中,内存中写入了相同检查点的备节点会持续监听主节点的保存结果。保存失败之后,备节点会接管主节点的持久化操作,代替主节点将检查点持久化下去,保证可靠性。
加速加载checkpoint
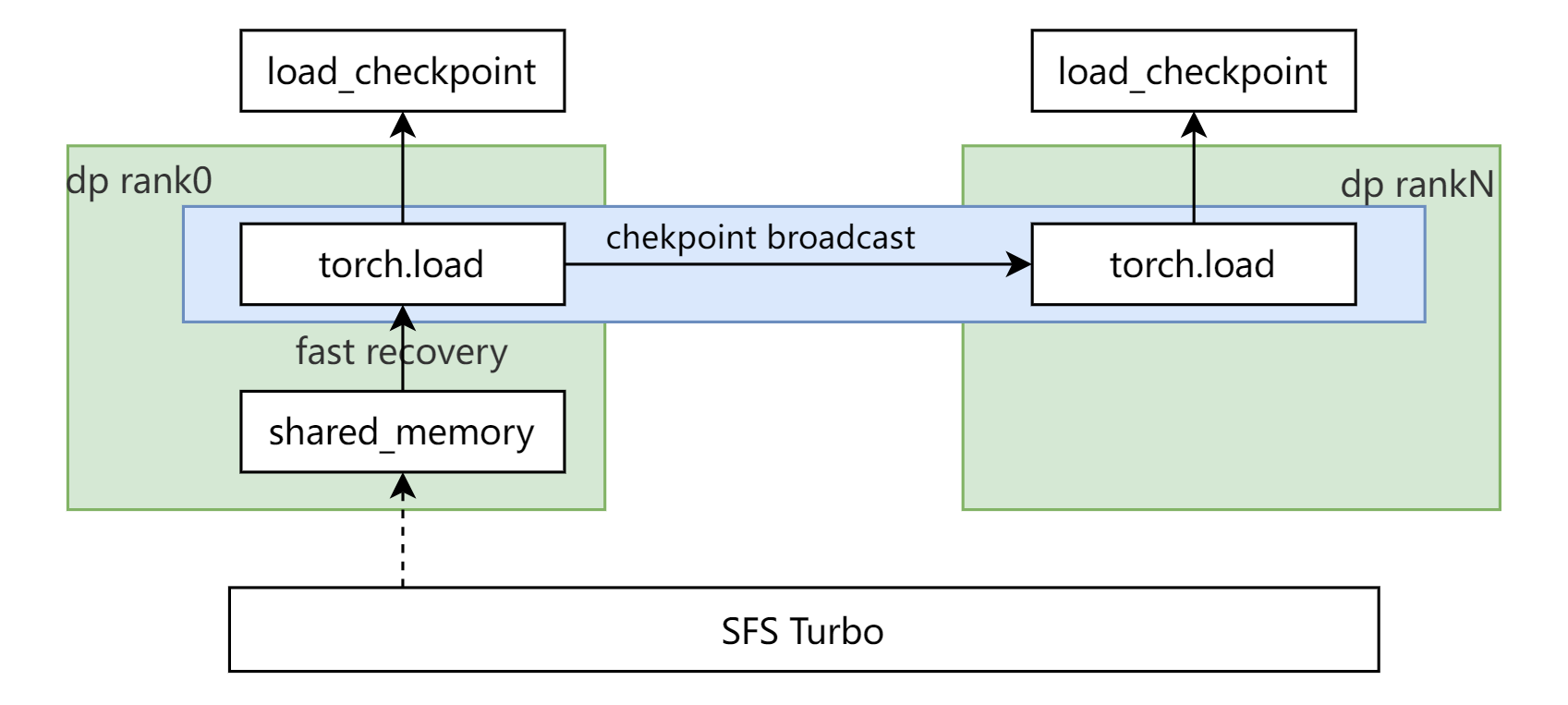
在加载checkpoint的时候,利用内存快恢、checkpoint广播等技术,大大减少后端存储的带宽压力,提升加载效率。具体地,对于训练中进程级故障、硬件仍然健康的故障场景,主机侧客户端内存缓存仍会保留,本机缓存中的checkpoint仍可正常访问,此时可从主机侧客户端内存中直接加载checkpoint进行原地秒级快速恢复;为避免所有GPU/NPU卡同时从存储中加载checkpoint致使存储带宽成为拥塞瓶颈,在具有相同checkpoint的冗余组内,采用部分代表节点先从远端存储加载checkpoint并将checkpoint广播到剩余其他节点的恢复机制,这种策略显著降低大规模训练集群故障恢复过程对远端存储带宽的需求,加速大规模训练集群checkpoint快速恢复。
安装AITurbo SDK
- 安装AITurbo SDK依赖包。
AITurbo SDK依赖rpyc,setproctitle,PyYAML,pathlib2等三方库,安装方式如下:
pip install rpyc setproctitle pathlib2 PyYAML
- 安装AITurbo SDK,checkpoint的保存和加载优化依赖于AITurbo SDK,安装包的下载地址请提交工单获取。





