

更新时间:2024-11-26 GMT+08:00
模型长文本摘要能力应用开发(Python SDK)
应用介绍
切割长文本,利用大模型逐步总结,如对会议/报告/文章等总结概述。涉及长文本分割、摘要等相关特性。
环境准备
- python3.9 及以上版本。
- 安装依赖的组件包, pip install pangu_kits_app_dev_py gradio python-docx。
- 盘古大语言模型。
开发实现
- 创建配置文件llm.properties, 正确配置iam和pangu配置项。信息收集请参考盘古应用开发SDK使用前准备。
# # Copyright (c) Huawei Technologies Co., Ltd. 2023-2023. All rights reserved. # ################################ GENERIC CONFIG ############################### ## If necessary, you can specify the http proxy configuration. # sdk.proxy.enabled=true # sdk.proxy.url= # sdk.proxy.user= # sdk.proxy.password= ## Generic IAM info. This config is used when the specified IAM is not configured. ## Either user password authentication or AK/SK authentication. # sdk.iam.url= sdk.iam.domain= sdk.iam.user= sdk.iam.password= sdk.iam.project= ## Pangu # Examples: https://{endPoint}/v1/{projectId}/deployments/{deploymentId} ; # sdk.llm.pangu.url=
- 创建代码文件(doc_summary.py),示例如下:
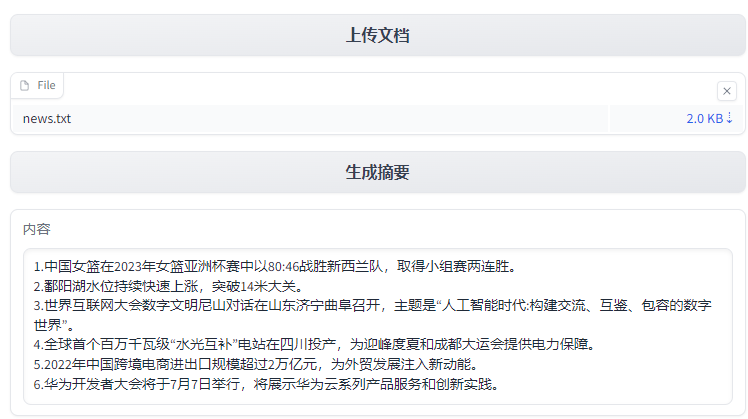
import os import gradio as gr import docx import time from pangukitsappdev.skill.doc.summary import DocSummaryMapReduceSkill from pangukitsappdev.api.llms.factory import LLMs # 设置SDK使用的配置文件 os.environ["SDK_CONFIG_PATH"] = "./llm.properties" # 初始化文档问答Skill doc_skill = DocSummaryMapReduceSkill(LLMs.of("pangu")) # 合并长度过小的段落,不超过maxLength def merge_docs(docs, maxLength, separator): result = [] current = [] length = 0 for doc in docs: if (length + len(doc) > maxLength): if current: result.append(separator.join(current)) current = [doc] length = len(doc) else: current.append(doc) length = length + len(doc) if current: result.append(separator.join(current)) return result # 加载文档,支持word和txt文本文件 def load_file(name): docs = [] if (name.endswith("doc") or name.endswith("docx")): doc = docx.Document(name) for grah in doc.paragraphs: docs.append(grah.text) else: data = "" with open(name, 'r', encoding='utf-8') as f: data = f.read() docs = data.split("\n") return docs def summary(files): sum_texts = [] for file in files: docs = load_file(file.name) # print(docs) docs_merge = merge_docs(docs, 1000, "\n") # 大模型对文档做摘要 sum_texts.append(doc_skill.execute_with_texts(docs_merge)) # 设置延时,避免访问太频繁 time.sleep(10) return sum_texts[0] if len(sum_texts) == 1 else doc_skill.execute_with_texts(sum_texts) def upload_file(files): file_paths = [file.name for file in files] return file_paths with gr.Blocks() as demo: upload_bt = gr.UploadButton("选择文档", file_types=["text"], file_count="multiple") file_output = gr.Files() upload_bt.upload(upload_file, upload_bt, file_output) greet_btn = gr.Button("生成摘要") output = gr.Textbox(label="输出") greet_btn.click(fn=summary, inputs=file_output, outputs=output, api_name="summary") demo.launch() - 终端命令行下执行python3 doc_summary.py运行应用,效果如下。
父主题: 盘古应用开发SDK实践





