

更新时间:2024-10-16 GMT+08:00
创建一个训练数据集
训练数据集是用于模型训练的实际数据集。通常,通过创建一个新的数据集步骤,可以生成包含某个特定场景数据的数据集。例如,这个数据集可能只包含用于训练摘要提取功能的数据。然而,在实际模型训练中,通常需要结合多种任务类型的数据,而不仅限于单一场景的数据。因此,实际的训练会混合不同类型的数据。例如,为防止模型在训练后出现通用问答能力下降,会混入一定的通用数据。
创建训练数据集的常见业务场景包括:
- 当用户的数据集较小时,可以将多个数据集组合起来进行训练。
- 需要进行模型的综合训练时,会组合多样的数据集,以提升模型处理不同类型数据的能力。例如,通过组合数据集,NLP模型在训练后可以同时具备文本生成、情感分析等多种能力。

- 在准备自监督训练数据和有监督微调数据时,除行业数据外,建议混入一定比例的通用数据,防止模型在经过训练后出现通用问答能力下降的情况。
- 行业数据 : 通用数据的比例按业内经验有1 : 1、1 : 5。实际训练过程中,行业数据和通用数据和的配比需要根据具体情况进行权衡,需要通过多次训练进行调整,既要考虑模型的通用能力,也要考虑模型在特定领域的性能。
创建一个训练数据集
- 登录盘古大模型套件平台。
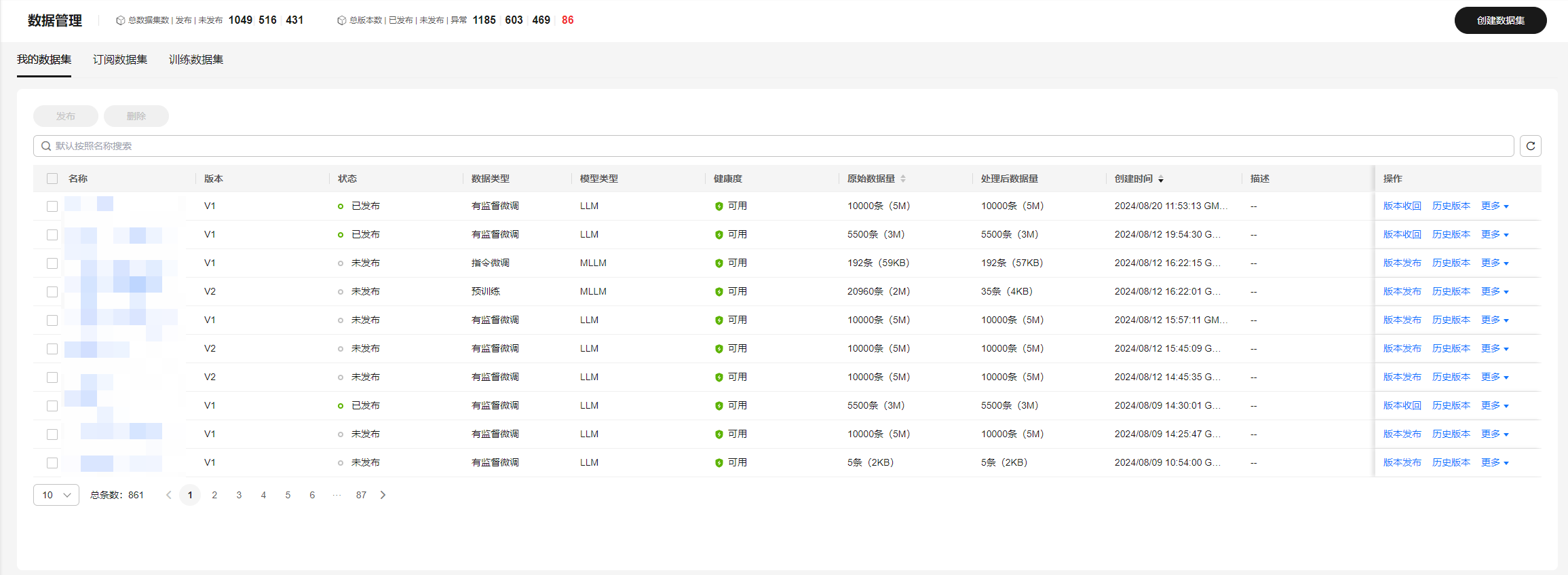
- 在左侧导航栏中选择“数据工程 > 数据管理”,单击界面右上角“创建数据集”。
图1 数据管理
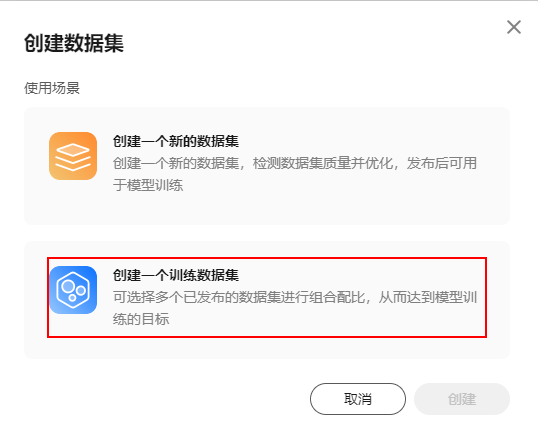
- 在创建数据集弹出框中选择“创建一个训练数据集”,单击“创建”。
图2 创建训练数据集
- 进入训练数据集页面后,需要进行训练配置、数据配置和基本配置。
- 训练配置
- 数据配置
选择训练数据集和配比类型,设置训练数据集配比,详情请参考数据配比功能介绍。
在训练数据集配比完成后,在单击“创建”或后续修改保存时,会对数据集的有效数据进行统计,确保满足模型训练的要求。
图3 数据配置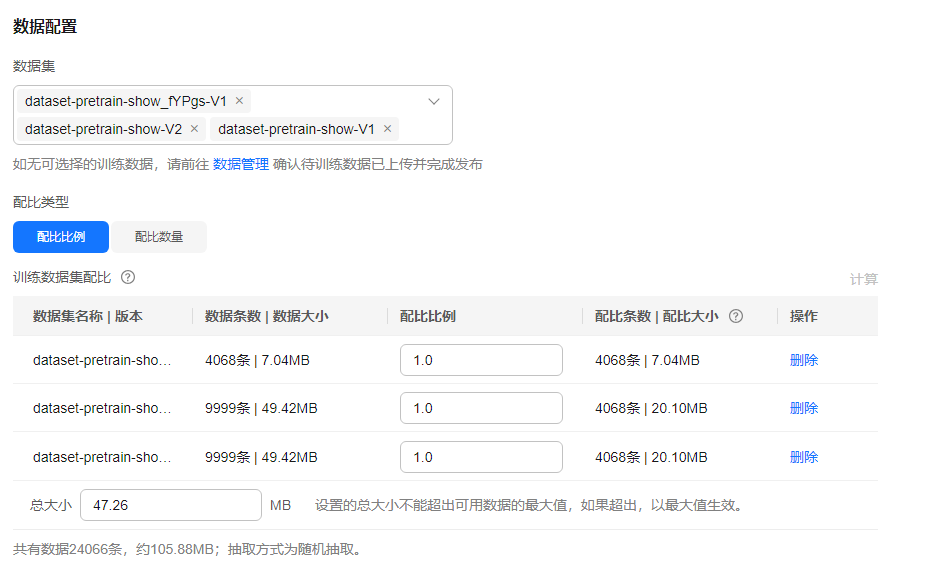
- 基本配置
- 参数填选完成后,单击“立即创建”。
数据配比功能介绍
用户针对业务场景,可以通过数据配比功能,自由组合多个数据集,并控制数据占比。
- 数据集来源:用户自己创建并且已经发布的数据集。
- 数据集组合:选择多个数据集,并且可以指定数据之间的配比和条数,最大支持20个。
- 配比的作用:支持用户灵活调整数据集的比例。
比例:用户自己创建的数据集,默认1:1:1的方式。例如,3个数据集D1(100GB)、D2(50GB)、D3(200GB),配比按照最大比例去配比,即为D1(50GB)、D2(50GB)、D3(50GB),则3*50=150GB,此时用户可以控制最大的数据量,限制数据量大小,如100GB。
表1 配置比例 配置比例
数据集大小上限500GB
第一阶段
第二阶段
-
数据集
原始大小
默认值
手动修改
实际大小
D1
100GB
1
1
100GB
D2
50GB
1
2
50GB
D3
200GB
1
1
200GB
训练数据集PD1
/
15
15
750GB
- 条数:用户指定每个数据集需要提供的条数;如果某个数据集的条数不满足用户需求,则提示用户重新输入,避免用户无感配置失败。
表2 配置条数 配置条数
数据集大小上限500GB
第一阶段
第二阶段
-
数据集
原始大小
默认值
手动修改
实际条数
D1
100
100
100
53
D2
50
50
50
27
D3
200
200
100
53
训练数据集PD1
/
/
1250
667
- 配比的作用:支持用户灵活调整数据集的比例。
父主题: 准备盘古大模型训练数据集





