

通过DataArts Studio提交MRS Hive作业
HiveSql作业是基于Hive数据仓库工具编写和运行的数据分析任务,主要用于在Hadoop分布式集群上处理大规模结构化或半结构化数据。HiveSQL是Hive定义的SQL方言,语法与标准SQL类似,但针对大数据场景做了优化,可将SQL语句转换为MapReduce或Spark任务执行,适合非编程人员快速实现数据查询、统计和分析。
DataArts Studio作为一款强大的一站式数据处理平台,为用户提供了便捷、高效的Hive作业提交能力,让数据处理变得轻松简单。
通过DataArts Studio提交MRS Hive作业流程如图1所示。

| 阶段 | 说明 |
|---|---|
| 准备MRS集群 | DataArts Studio支持对接MRS Hive、HDFS、HBase、Spark、ClickHouse等大数据组件,可基于业务需求按需选择并创建包含有对应组件的MRS集群。 |
| 初始配置DataArts Studio | DataArts Studio实例的虚拟私有云、子网、安全组信息,需与MRS集群保持一致。 MRS为非全托管服务,DataArts Studio无法直接与其进行连接。数据集成集群(CDM集群)提供了DataArts Studio与非全托管服务通信的代理,所以需提前准备一个CDM集群。 |
| 创建数据连接 | DataArts Studio基于管理中心的数据连接对数据湖底座进行数据开发、治理、服务和运营。建立数据连接用于作业运行时,DataArts Studio访问MRS集群内对应组件。 |
| 开发脚本或应用程序 | 数据开发是一个一站式的大数据协同开发平台,提供全托管的大数据调度能力。 用户基于业务需求开发相关的SQL脚本作业或者Jar作业。 |
| 编排调度作业 | DataArts Studio平台支持将多个脚本编排成一个作业,通过可视化方式构建工作流并定义节点依赖关系,实现数据采集、处理、分析等多个业务场景的串联运行。同时还能为作业配置自动化调度计划,支持灵活周期定时执行,搭配失败重试、告警通知等容错策略,让业务流程无需人工干预即可周期性自动运转,同步通过监控面板实时追踪作业状态,大幅提升数据处理的效率与稳定性。 |
| 运行作业并查看结果 | 用户可以直接通过运行结果查看作业运行情况。 |
在本章节中以开发一个MRS HiveSQL作业为例进行介绍。
步骤1:准备MRS集群
- 进入购买MRS集群页面。
- 选择“快速购买”,填写软件配置参数。
以购买一个开启Kerberos认证的包含Hive组件的MRS集群为例,关键参数配置如表2所示。
更多MRS集群购买参数说明请参考快速购买MRS集群。
表2 创建MRS集群 参数名称
描述
取值样例
计费模式
选择待创建的MRS集群的计费模式。
按需计费
集群名称
待创建的MRS集群名称。
MRS_demo
集群类型
待创建的MRS集群类型。
选择“自定义”
版本类型
待创建的MRS集群版本类型。
LTS版
集群版本
待创建的MRS集群版本。
MRS 3.2.0-LTS.1
组件选择
选择待创建的MRS集群配套的组件。
Hadoop分析集群
可用区
选择集群工作区域下关联的可用区。
可用区1
虚拟私有云
选择需要创建集群的VPC,单击“查看虚拟私有云”进入VPC服务查看已创建的VPC名称和ID。如果没有VPC,需要创建一个新的VPC。
vpc-01
子网
选择需要创建集群的子网,可进入VPC服务查看VPC下已创建的子网名称和ID。如果VPC下未创建子网,请单击“创建子网”进行创建。
subnet-01
Kerberos认证
访问MRS集群时是否启用Kerberos认证。
开启
密码
配置Manager管理员admin用户及集群ECS节点root用户的密码。
Test!@12345。
企业项目
选择集群所属的企业项目。
default
- 单击“立即购买”,等待MRS集群创建成功。
- 集群状态变为“运行中”后,单击集群名称,进入集群详情页后选择“前往Manager”,然后继续选择一个弹性公网IP后,进入集群Manager登录界面。
更多MRS集群Manager界面登录方式介绍请参考访问MRS集群Manager。
- 使用admin用户登录集群Manager界面,密码为步骤 2中设置的密码。
- 选择“系统 > 用户”创建一个具有Hive操作权限的业务用户。
由于当前集群已开启Kerberos认证,需在Manager界面中创建一个具有Hive作业提交权限的业务用户,请参考创建MRS集群用户。

- MRS 3.1.0及之后版本集群,用户至少需具备Manager_viewer的角色权限才能在管理中心创建连接;如果需要对应组件的进行库、表、数据的操作,还需要添加对应组件的用户组权限。
- MRS 3.1.0版本之前的集群,所创建的用户需要具备Manager_administrator或System_administrator权限,才能在管理中心创建连接。
- 建议用户名的密码策略设置为永不过期,避免由于密码过期后导致连接失败,引起业务受损,请参考配置MRS集群用户密码策略。
例如创建一个人机用户testuser,关联用户组“supergroup”及角色“System_administrator”。
图2 添加集群业务用户
- 用户创建成功后,选择界面右上角“admin > 注销”,然后使用新创建的用户重新登录Manager,并按照界面提示修改初始密码。
步骤2:初始配置DataArts Studio
- 登录DataArts Studio管理控制台,购买一个DataArts Studio实例。
DataArts Studio实例的虚拟私有云、子网、安全组信息,需与MRS集群保持一致。
具体操作请参考购买DataArts Studio实例。
- 进入DataArts Studio实例概览信息页面,选择“空间管理 > 创建工作空间”,创建一个工作空间。
DataArts Studio实例中系统会默认创建一个默认的工作空间“default”,并赋予用户为管理员角色。您可以使用默认的工作空间,也可以在“空间管理”页签中创建一个新的工作空间。
具体操作请参考创建简单模式工作空间。
- (可选)在DataArts Studio实例概览信息页面,选择当前工作空间下的“数据集成”,继续创建一个数据集成集群(CDM集群)。
非免费版的DataArts Studio实例赠送的数据集成集群,可以作为管理中心数据连接的Agent代理使用,因此如果步骤 1中购买了DataArts Studio非免费版实例,本步骤可忽略。
新创建的CDM集群须和MRS集群处于相同的区域、可用区,且使用同一个VPC和子网,安全组规则需允许两者网络互通或者使用同一个安全组。
更多关于CDM集群的创建操作请参考购买批量数据迁移增量包。
图3 创建CMD集群
步骤3:创建MRS Hive数据连接
- 在DataArts Studio实例概览信息页面,选择当前工作空间下的“管理中心”。
- 在数据连接界面中选择“创建数据连接”,创建一个“MapReduce服务 (MRS Hive)”类型的数据连接。
表3 MRS Hive数据连接 参数名称
描述
取值样例
数据连接名称
数据连接的名称,只能包含字母、数字、下划线和中划线,且长度不超过100个字符。
mrs-hive
适用组件
选择此连接适用的组件。
数据开发
连接方式
- 通过代理连接:通过Agent(即CDM集群)进行代理,以集群用户访问MRS集群。代理连接方式支持MRS所有版本的集群。
- MRS API连接:以MRS API的方式访问MRS集群。
为保证数据架构、数据质量、数据目录、数据服务等组件能够使用此MRS连接,此处连接方式推荐配置为“通过代理连接”。
通过代理连接
手动
选择连接模式,如果没有访问其他项目或企业项目下MRS集群的需求,使用集群名模式即可。
- 集群名模式:通过选择已有集群名称进行连接配置,仅可选择本项目内且企业项目相同的MRS集群进行连接。
- 连接串模式:通过手动输入Manager IP,并打通本连接Agent(即CDM集群)和MRS集群之间的网络,则可以访问其他项目或企业项目的MRS集群。
集群名模式
MRS集群名
选择步骤1:准备MRS集群中创建的MRS集群。
mrs-demo
KMS加密密钥
通过KMS加解密数据源认证信息,选择KMS中的任一默认密钥或自定义密钥即可。
ims/default
绑定Agent
选择步骤2:初始配置DataArts Studio中的CDM集群。
cdm-a123
用户名
MRS集群的业务用户,选择步骤1:准备MRS集群中创建的MRS集群业务用户。
testuser
密码
MRS集群业务用户的密码。
-
开启ldap
当MRS Hive对接了外部LDAP时,连接Hive时需要使用LDAP账号与密码进行认证,此时须开启此参数,否则会连接失败。
否
更多关于DataArts Studio数据连接的配置说明及约束信息,请参考创建DataArts Studio数据连接。
- 参数配置完成后,单击“保存 ”,系统会自动检查数据连接的连通性。
步骤4:开发Hive SQL脚本
- 在DataArts Studio实例概览信息页面,选择当前工作空间下的“数据开发”。
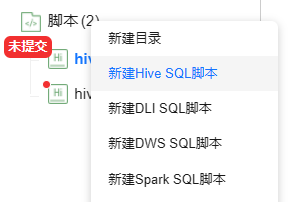
- 在“脚本开发”页面中的“脚本”目录上右键,选择“新建Hive SQL脚本”。 图4 新建HiveSQL脚本
- 在编辑器中输入SQL语句,通过SQL语句来实现业务需求。
例如开发一个脚本如下:
在Hive中新创建一个数据库及数据表。
-- 创建数据库 CREATE DATABASE IF NOT EXISTS test_db; -- 使用数据库 USE test_db; -- 创建数据表 CREATE TABLE IF NOT EXISTS test_table ( id INT, name STRING, age INT, gender STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';脚本开发完成后,设置开发区右上角的运行配置参数后,单击画布上方的“运行”可查看脚本执行情况与执行结果。
- 数据连接:选择步骤3:创建MRS Hive数据连接中创建的MRS Hive连接。
- 数据库:选择Hive中的数据库。
- 资源队列:运行Hive作业任务时使用的资源队列信息,若不设置默认使用集群的default队列。
- 脚本开发完成后,选择“保存”,保存当前脚本。
- 参考步骤 3继续开发其他脚本。
例如继续开发一个脚本如下:
在Hive表插入一行数据并查询。
-- 使用数据库 USE test_db; -- 插入单行数据 INSERT INTO test_table VALUES (1, 'Zhangsan', 30, 'Male'); -- 查看数据表内容 SELECT * FROM test_table;
步骤5:编排调度作业
- 在DataArts Studio实例概览信息页面,选择当前工作空间下的“数据开发”。
- 在“作业开发”页面中的“作业”目录上右键,选择“新建作业”。
- 配置作业参数并选择“确定”,创建一个批处理作业。
表4 DataArts Studio作业配置参数 参数名称
描述
取值样例
作业名称
自定义作业的名称,只能包含英文字母、数字、中文、“-”、“_”、“.”,且长度为1~128个字符。
job_test
作业类型
- 批处理作业:按调度计划定期处理批量数据,主要用于实时性要求低的场景。批作业是由一个或多个节点组成的流水线,以流水线作为一个整体被调度。被调度触发后,任务执行一段时间必须结束,即任务不能无限时间持续运行。
- 实时处理作业:处理实时的连续数据,主要用于实时性要求高的场景。实时作业是由一个或多个节点组成的业务关系,每个节点可单独被配置调度策略,而且节点启动的任务可以永不下线。在实时作业里,带箭头的连线仅代表业务上的关系,而非任务执行流程,更不是数据流。
批处理
模式
- Pipeline:即传统的流水线式作业,作业通过画布编辑,可以拖入一个或多个节点组成作业,各节点依次被流水线式地执行。
- 单任务:单任务作业可以认为是有且只有一个节点的批处理作业,整个作业即为一个脚本节点。
Pipeline
选择目录
选择作业所属的目录,默认为根目录。
/作业/
责任人
填写该作业的责任人。
-
作业优先级
选择作业的优先级,提供高、中、低三个等级。
作业优先级是作业的一个标签属性,不影响作业的实际调度执行的先后顺序。
高
委托配置
作业执行过程中,以IAM委托的身份与其他服务交互。
若工作空间已配置过委托,则新建的作业默认使用该工作空间级委托。
-
日志路径
选择作业日志的OBS存储路径。
obs://test/dataarts-log/
作业描述
作业的描述信息。
-
更多关于DataArts Studio作业的配置说明及约束信息,请参考新建DataArts Studio作业。
- 作业创建成功后,进入到作业开发编排页面。
拖动左侧节点库中所需的节点到画布中,鼠标移动到节点图标上,选中连线图标,然后单击节点配置相关的属性参数。
例如在本示例中,配置两个MRS Hive SQL节点并连线,执行作业时,系统将依次执行两个指定的SQL脚本。
图5 编排DataArts Studio作业
关键属性说明:
- 节点名称:默认显示为SQL脚本“hive_sql”的名称,支持修改。
- SQL脚本:选择步骤4:开发Hive SQL脚本中开发完成的Hive SQL脚本。
- 数据连接:选择步骤3:创建MRS Hive数据连接中创建的MRS Hive连接。
- 数据库:默认选择SQL脚本中设置的数据库,支持修改。
- 其他作业参数保持默认,或者根据业务需求进行调整。
更多关于DataArts Studio作业开发参数配置说明,请参考DataArts Studio作业开发。
- 作业编排完成后,单击画布上方的“测试运行”,会弹出测试参数配置的弹框,自动显示作业的变量参数,单击“确定”,测试作业。
如果测试未通过,请您查看作业节点的运行日志,进行定位处理。
图6 测试DataArts Studio作业运行
在本示例中,通过日志可查看到成功在表“test_table”中插入了数据。
... 1,Zhangsan,30,Male
- 作业运行成功后,单击画布空白处,在右侧的“调度配置”页面,配置作业的调度策略。
DataArts Studio作业支持多种调度方式,例如可配置当前作业在指定时间段内的每天固定时间自动运行。
图7 DataArts Studio作业调度配置
更多关于DataArts Studio作业调度方式和约束限制说明,请参考DataArts Studio调度作业。
- 配置完成后,单击画布上方的“提交”,提交版本并勾选是否在下个调度周期使用新版本。
在提交版本时,单击“版本对比”可以查看当前提交版本与最近一个版本之间的差异对比。
作业提交后,单击“执行调度”,然后在数据开发页面的“运维调度 > 作业监控”页面,即可查看当前作业的调度状态及历史执行结果。
图8 查看作业状态
相关文档
- 关于DataArts Studio平台更多数据开发实践案例,请参考DataArts Studio数据开发进阶实践。
- 更多关于DataArts Studio作业开发操作说明及注意事项,请参考作业开发流程。
- 如需通过API方式新增并执行作业,具体操作请参见新增并执行作业。
- 更多MRS应用开发样例程序,请参见MRS应用开发指南。




