

云数据库 TaurusDB
云数据库 TaurusDB
- 最新动态
- 功能总览
- 服务公告
- 产品介绍
- 快速入门
- 内核介绍
- 用户指南
- 最佳实践
- 性能白皮书
-
API参考
- 使用前必读
- API概览
- 如何调用API
-
API(推荐)
- 查询数据库引擎的版本
- 查询数据库规格
-
实例管理
- 创建数据库实例
- 重启数据库实例
- 删除/退订数据库实例
- 创建只读节点
- 删除/退订只读节点
- 包年/包月实例存储扩容
- 修改实例名称
- 重置数据库密码
- 变更实例规格
- 查询专属资源池列表
- 查询专属资源信息详情
- 设置实例秒级监控
- 查询实例秒级监控
- 节点重启
- 内核版本升级
- 开关SSL
- 绑定弹性公网IP地址
- 解绑弹性公网IP地址
- 手动主备倒换
- 设置可维护时间段
- 修改安全组
- 修改内网地址
- 修改实例端口
- 修改实例备注
- 申请内网域名
- 修改内网域名
- 查询内核版本信息
- 设置自动变配
- 查询自动变配
- 资源预校验
- 查询实例列表
- 查询实例详情信息
- 批量查询实例详情
- 设置回收站策略
- 查询回收站策略
- 查询回收站实例信息
- 批量修改节点名称
- 查询自动变配历史记录
- 设置Serverless配置策略
- 修改节点故障倒换优先级
- 查询弹性公网IP
- 备份管理
- 参数模板管理
- 配额管理
- 数据库代理
- 日志管理
- 标签管理
- 数据库用户管理
- 数据库管理
- SQL限流
- 任务中心
- 智能诊断
-
HTAP-标准版
- 恢复StarRocks数据同步
- 暂停StarRocks数据同步
- HTAP数据同步表配置校验
- 创建StarRocks实例
- 查询StarRocks实例
- 删除StarRocks实例
- 重启StarRocks实例
- 重启StarRocks节点
- StarRocks资源检查
- HTAP引擎资源查询
- 获取HTAP实例存储类型
- HTAP查询规格信息
- 查询HTAP实例列表
- 创建StarRocks数据同步
- 删除StarRocks数据同步
- 查询StarRocks数据同步状态信息
- HTAP数据同步库配置校验
- 查询StarRocks数据同步配置信息
- 查询StarRocks数据同步的库参数配置
- 查询StarRocks数据库
- 查询数据库账户
- 创建数据库账号
- 删除数据库账户
- 修改数据库账号密码
- 修改数据库账号权限
- StarRocks实例规格变更
- 查询参数
- 修改参数
- StarRocks实例开启行列分流
- 参数对比
- HTAP-轻量版
- 多租特性
- API(即将下线)
- 权限策略和授权项
- 附录
- SDK参考
- 场景代码示例
-
故障排除
- 备份恢复
- 连接类
-
SQL类
- 建表时timestamp字段默认值无效
- 索引长度限制导致修改varchar长度失败
- delete大表数据后,再查询同一张表时出现慢SQL
- 更新emoji表情数据报错Error 1366
- 存储过程和相关表字符集不一致导致执行缓慢
- 报错ERROR [1412]的解决方法
- 存在外键的表无法删除
- GROUP_CONCAT结果不符合预期
- 创建二级索引报错Too many keys specified
- distinct与group by优化
- 为什么有时候用浮点数做等值比较查不到数据
- 开通数据库代理后,还是有大量select请求分发到主节点
- 表空间膨胀问题
- MySQL创建用户提示服务器错误(ERROR 1396)
- 执行alter table xxx discard/import tablespace报错
- 数据库报错Native error 1461的解决方案
- 创建表失败报错Row size too large的解决方案
- Order by limit分页出现数据重复问题
- 执行select * from sys.innodb_lock_waits报错
- 参数类
- 性能资源类
-
基本使用类
- 查看TaurusDB的存储容量
- 修改库名和修改表名
- 字符集和字符序的默认选择方式
- 自增字段值跳变的原因
- 表的自增AUTO_INCREMENT初值与步长
- 修改表的自增AUTO_INCREMENT值
- 自增主键达到上限,无法插入数据
- 自增字段取值
- 自增属性AUTO_INCREMENT为何未在表结构中显示
- 空用户的危害
- 慢日志显示SQL语句扫描行数为0
- 错误日志页面显示handle_sync_msg_from_slave my_net_read error:-1
- 执行SQL语句报错:ERROR 1290 (HY000): The MySQL server is running with the --sql-replica-on option so it cannot execute this statement的原因及解决方案
- 常见问题
- 视频帮助
- 文档下载
- 通用参考

链接复制成功!
功能介绍
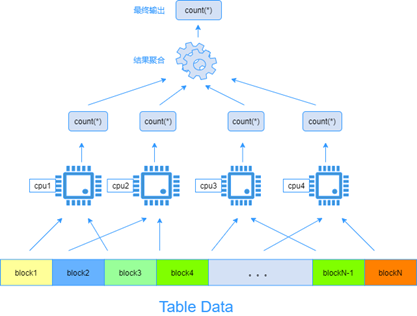
云数据库GaussDB(for MySQL)支持了并行执行的查询方式,用以降低分析型查询场景的处理时间,满足企业级应用对查询低时延的要求。并行查询的基本实现原理是将查询任务进行切分并分发到多个CPU核上进行计算,充分利用cpu的多核计算资源来缩短查询时间。并行查询的性能提升倍数理论上与CPU的核数正相关,也就是说并行度越高能够使用的CPU核数就越多,性能提升的倍数也就越高。
下图是使用CPU多核资源并行计算一个表的count(*)过程的基本原理:表数据进行切块后分发给多个核进行并行计算,每个核计算部分数据得到一个中间count(*)结果,并在最后阶段将所有中间结果进行聚合得到最终结果。具体如下:
图1 并行查询示意图
前提条件
云数据库GaussDB(for MySQL)的引擎版本为MySQL 8.0.22及以上。

父主题: 实例管理




