

更新时间:2025-12-25 GMT+08:00
附加字段使用说明
使用场景
- 用户期望在目的端表中新增一个附加字段,附加字段的值可以来自于源端某个已有字段的转换结果,也可以来源于源端、目的端库表相关的元数据。
- 用户期望通过附加字段覆盖已有同名字段的值(仅部分链路支持)。
支持的链路:多数整库作业都支持为目的端表添加附加字段,是否支持附加字段请以使用教程各链路描述为准。
约束限制
- 当附加字段名与源端已有字段名重名时自动建表可能会失败,提示字段名重复,用户需要手动完成建表。
- 对于已有表添加附加字段时,用户需要保证目的端表结构中已包含附加字段,否则可能会出现作业运行失败。
- 在使用UDF时,请仔细阅读字段值配置说明中UDF字段值的说明。
配置附加字段方式
作业编辑阶段,目标端配置,刷新源表和目标表映射后可以为指定表添加附加字段。
图1 配置附加字段入口

附加字段需要配置包括以下内容:
字段值配置说明
- 常量
- 参数说明:字段值为常量时,附加字段填充固定值。
- 作业样例:如下图,mysql_constant_extra_col字段在目的端的查询结果为固定的AAAA。 图2 常量取值示例

- 内置变量
- 参数说明:内置变量支持配置以下值,均为与数据源元数据相关的值:
- 源端host ip地址:source.
- 源端库名称:source.schema
- 源端表名称:source.table
- 目的端库名称:target.schema
- 目的端表名称:target.table
- 作业样例:如下图。 图3 内置变量示例

查看目的端输出结果。
图4 目的端结果
- 参数说明:内置变量支持配置以下值,均为与数据源元数据相关的值:
- 字段变量
- 参数说明:字段变量会为附加字段填充源端表的某个字段值,用户可以通过下拉框选定或手动输入源端字段名。
- 作业样例:如下图。 图5 字段变量取值示例

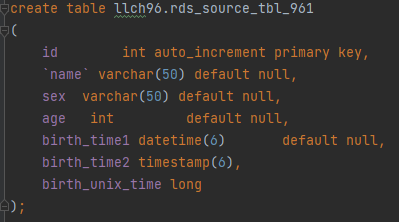
源端表llch96.rds_source_tbl_961表数据如下:
图6 源端表数据
数据迁移到目的端后输入如下:
图7 目的端表数据
- UDF方法
- 参数说明:字段值选择UDF方法时,支持用户按需选择UDF转换函数对源端字段值做二次处理后写入附加字段,支持UDF方法包括:
- substring(#col, pos[, len]): 截取源端col列的子串, 范围在[pos, pos+len)。
- date_format(#col, time_format[, src_tz, dst_tz]): 将源端col列按time_format格式化, 可选转换时区。
- now([tz]):获取指定时区的当前时间。
- if(cond_exp, str1, str2): 满足条件表达式cond_exp时返回str1, 否则返回str2。
- concat(#col[, #str, ...]): 拼接多个参数, 可为源端列或字符串。
- from_unixtime(#col[, time_format]): 将unix时间戳按time_format格式化。
- unix_timestamp(#col[, precision, time_format]): 将时间转成unix时间戳, 可显式定义时间格式及转换后精度。
各个UDF函数的详细使用方式和样例如下:- substring
substring(#col, pos[, len])说明:
- 对源端col字段的值从第pos个字符(包含pos)开始截取,默认截取到末尾。
- 截取长度len参数可选,配置len时表示向后截取结果字符的长度为len。
- 第一个字符pos=1,第二个字符pos=2,依次类推。
- pos=0同样表示第一个字符。
设定col = "abcdefg",长度为7 substring(#col, 1) = "abcdefg" substring(#col, 1, 3) = "abc" substring(#col, 0, 3) = "abc" substring(#col, 3, 4) = "cdef" substring(#col, 1, 100) = "abcdefg"
- date_format date_format(#col, time_format[, src_tz, dst_tz])说明:
- 对源端的时间格式字段col按照新的格式time_format进行格式化,可以设置源端col的时区为src_tz、目的端的时区dst_tz。
- col的值必须为时间格式,例如'2025-12-11 00:49:00.123456',否则可能在转换时导致作业异常。
- time_format参数必须为合法的时间格式,可以包含yyyy、MM、dd、HH、mm、ss、SS,例如yyyy-MM-dd HH:mm:ss.SSS,在拼写date_format表达式时请勿用引号将time_format包裹,否则会导致作业异常。例如 date_format(#col, yyyy)是合法的,date_format(#col, 'yyyy')是非法的。
- src_tz为输入时区,表示输入时间字段col的时区,配置输入时区的表达式模板为date_format(#col, time_format, src_tz, dst_tz),例如 date_format(#col, yyyy-MM-dd, -8, +8),-8即为源端时区。
- dst_tz为输出时区,表示用户期望UDF输出结果时间的时区,配置输出时区的表达式模板为date_format(#col, time_format, dst_tz)或date_format(#col, time_format, src_tz, dst_tz),例如date_format(#col, yyyy-MM-dd, +8)、date_format(#col, yyyy-MM-dd, -8, +8)均表示输出时区为+8。
- 当源端字段col类型为timestamp时,字段值已默认带有输入时区信息,配置输入时区不会生效。
- date_format(#col, time_format),当源端col为非timestamp类型时,默认源端与目的端时区一致,不做时区转换;当源端col为timestamp类型时,默认按系统时区输出结果。
- date_format(#col, time_format, dst_tz),当源端col为非timestamp类型时,默认源端时区为UTC。
表1 时区生效规则 表达式
源端字段类型
源端生效时区
目的端生效时区
date_format(#col, time_format)
字符串/datetime
当前region时区
当前region时区
timestamp
源端时区
当前region时区
date_format(#col, time_format, dst_tz)
字符串/datetime
UTC
dst_tz
timestamp
源端时区
dst_tz
date_format(#col, time_format, src_tz, dst_tz)
字符串/datetime
src_tz
dst_tz
timestamp
源端时区
dst_tz
字段类型为datetime类型示例:
设定col = "2023-08-01 09:00:00.000000",字段类型为datetime类型或字符串类型 #未配置时区信息,默认源端与目的端时区一致 date_format(#col, yyyy-MM-dd HH:mm:ss) = "2023-08-01 09:00:00" #源端非timestamp字段类型,默认源端时区为UTC,这里配置目的端为UTC,源端与目的端时区一致 date_format(#col, yyyy-MM-dd HH:mm:ss, UTC) = "2023-08-01 09:00:00" #源端非timestamp字段类型,默认源端时区为UTC,这里配置目的端时区为+8 date_format(#col, yyyy-MM-dd HH:mm:ss, +8) = "2023-08-01 17:00:00" date_format(#col, yyyy-MM-dd HH:mm:ss, GMT+8) = "2023-08-01 17:00:00" date_format(#col, yyyy-MM-dd HH:mm:ss, UTC+8) = "2023-08-01 17:00:00" #源端非timestamp字段类型,配置源端时区+1生效,配置目的端时区为+8 date_format(#col, yyyy-MM-dd HH:mm:ss, +1, +8) = "2023-08-01 16:00:00" #源端非timestamp字段类型,配置源端时区-8生效,配置目的端时区为+8 date_format(#col, yyyy-MM-dd HH:mm:ss, -8, +8) = "2023-08-02 01:00:00"
字段类型为timestamp示例:
设定col = "2023-07-05 00:00:15.123456",字段类型为timestamp,源端时区为+8,当前华为云region所在时区为+8(例如Asia/Singapore) #源端为timestamp字段类型,源端时区为+8,目的端时区为华为云region所在时区,即+8 date_format(#col, yyyy-MM-dd HH:mm:ss) = "2023-07-05 00:00:15" #源端为timestamp字段类型,源端时区为+8,目的端时区为配置的+16 date_format(#col, yyyy-MM-dd HH:mm:ss, +16) = "2023-07-05 08:00:15" #源端为timestamp字段类型,配置的src_tz不生效,使用源端真实时区+8,目的端时区为配置的+8 date_format(#col, yyyy-MM-dd HH:mm:ss, -8, +8) = "2023-07-05 00:00:15" #源端为timestamp字段类型,配置的src_tz不生效,使用源端真实时区+8,目的端时区为配置的+16 date_format(#col, yyyy-MM-dd HH:mm:ss, -8, +16) = "2023-07-05 08:00:15"
- now
- 数据被实时作业读取到时的系统时。
- tz为可选配置,用来指定系统时间所在时区,默认为华为云服务当前所在region的时区。
示例:
now() = "2025-07-30 14:46:48.969" now(+16) = "2025-07-30 22:46:48.969"
- if
- 根据用户配置的逻辑判断表达式cond_exp决定输出结果,cond_exp判定结果为true时输出“str1”,cond_exp判定结果为false时输出“str2”。
- 当前仅支持对内置变量的“等于”/“不等于”的逻辑判断,逻辑判断表达式一边的常量部分需要使用英文单引号包裹,例如,if(#{mgr.source.table} = 'src_tb', 'a', 'b')。
示例:
if(#{mgr.source.table} = 'src_tb', 'a', 'b') = 'a' if(#{source.host} = '10.xxx.x.xx', 'abcd', 'qaz') = 'qaz' - concat
- 将多个字段值拼接,支持对源端字段值的拼接,也支持对字符串常量的拼接,例如,concat(#col, '&', #col2, '_', aaa)。
- 当存在任意一个输入参数为null时整个表达式输出结果为null。
示例:
# col为源端字段,取值col="col_data",#{mgr.source.table}为内置变量“源端表名”的引用,取值为#{mgr.source.table}="src_tb" concat(#col, '_', #{mgr.source.table}) = "col_data_src_tb" # col为源端字段,取值col="col_data",col2源端字段,取值col2="col2_data",第三个输入参数为一个字符串常量“aaa” concat(#col, '&', #col2, '_', aaa) = "col_data&col2_data_aaa" # col_null为一个全null字段,整个表达式输出结果为null concat(#col, #col2, #col_null) = null - from_unixtime
from_unixtime(#col[, time_format])说明:
- 将长整型的时间戳字段转换为时间格式的值,col字段为源端长整型的unix timestamp,time_format参数为用户期望输出的时间格。
- 不支持指定输出时间的时区,默认按照当前华为云region的时区输出结果。
- 不指定time_format的场景下,默认值按照yyyy-MM-dd HH:mm:ss.SSS格式输出结果。
示例:
# col = 17042536161231 from_unixtime(#col, yyyy-MM-dd HH:mm) = "2024-01-03 11:46" from_unixtime(#col, yyyy-MM-dd HH:mm:ss:SSSSSS) = "2024-01-03 11:46:56:123100" # col= 1704253616 from_unixtime(#col) = "2024-01-03 11:46:56.000" # col= 942379893 from_unixtime(#col, yyyy-MM-dd) = "1999-11-12" # col= 17042536161 from_unixtime(#col, yyyy-MM-dd) = "2024-01-03"
- unix_timestamp
unix_timestamp(#col[, precision, time_format])说明:
- 将时间格式的数据转换成长整型的unix timestamp,col为源端时间格式的字段,precision参数用于配置输出unix timestamp的秒以下的精度,默认精度为3,time_format用于指定输入数据的时间格式。
- time_format用于指定输入数据的时间格式,time_format需要与col字段的格式严格匹配,否则可能出现精度丢失或转换不准确问题;当用户没有配置time_format时,会按照yyyy-MM-dd HH:mm:ss[.fffffffff]格式解析输入数据。
- unix_timestamp无法指定col字段的时区信息,当col字段为timestamp类型时,会使用源端时区解析输入值;当col字段为datetime或字符串时,默认使用华为云服务当前所在region的时区解析输入值。
示例:
# col = "2024-01-03 11:46:56.123" unix_timestamp(#col) = "1704253616123" # col = "2024-01-03 11:46:56" unix_timestamp(#col) = "1704253616000" # col = "2024-01-03 11:46:56.123456" unix_timestamp(#col, 9) = "1704253616123456000" # col = "2024-01-03 11:46:56.123456789" unix_timestamp(#col, 9) = "1704253616123456789" # col = "2024-01-03 11:46" unix_timestamp(#dateStr1, 0, yyyy-MM-dd HH:mm) = "1704253560"
- 表达式嵌套
示例:
# col = "2025-11-11 00:14:23" substring(date_format(#col, 'yyyyMMdd'), 0, 4) = "2025"
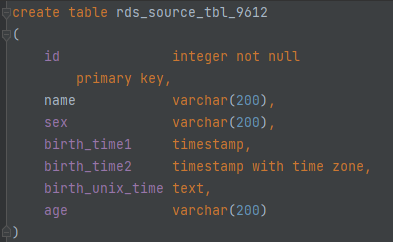
- 作业样例:如下图例。
图8 源表建表结构示例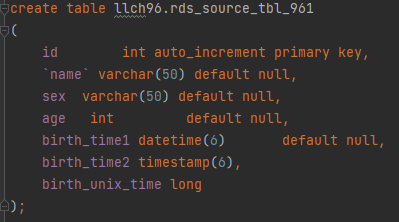
查看源端数据。
图9 源端数据
查看作业配置。
图10 作业配置
查看最终同步结果。
图11 同步结果
- 参数说明:字段值选择UDF方法时,支持用户按需选择UDF转换函数对源端字段值做二次处理后写入附加字段,支持UDF方法包括:




父主题: 数据集成(实时作业)




