

实施步骤
天宽行业大模型适配服务
前期咨询:天宽会深入了解客户所在行业的需求,评估业务场景中的具体问题和痛点。通过与客户的多轮沟通,明确所需解决的问题及目标,为客户量身定制相应的大模型解决方案。同时,天宽会结合模型的技术特点和行业实践,确定模型落地路径,并规划整个模型开发与实施的整体方案。
模型开发与训练:根据客户的具体业务需求及数据特性,天宽将设计出适合该业务场景的模型。此阶段会涉及数据预处理、特征工程及模型架构的选择。
- 天宽在数据采集领域拥有丰富的爬虫开发经验,能够熟练使用Python、JavaScript等编程语言,为客户定制高效的爬虫脚本,从指定的网站和平台采集所需数据。天宽团队在实际项目中曾广泛应用Scrapy、Beautiful Soup和Selenium等工具,确保数据采集的速度和质量。
图1 模型开发与训练1

- 天宽团队在数据处理方面具备深厚的专业技能,能够熟练运用Python的Pandas和NumPy等库进行高效的数据清洗与预处理。天宽团队掌握全面的数据清洗流程,包括去除重复值、处理缺失数据、检测和修正异常值等操作,确保数据的完整性和一致性。对于大规模数据集,天宽团队擅长使用Apache Spark等大数据处理工具,能够高效地对数据进行清洗、转换和优化。
图2 天宽行业大模型适配服务1
 图3 天宽行业大模型适配服务2
图3 天宽行业大模型适配服务2





模型评估调优:天宽凭借在多个项目中的实践,积累了丰富的大模型评测经验,能够高效且准确地定义性能指标,如准确性、召回率、精确度等标准评价维度。对于不同的业务场景,天宽还会根据具体需求设定与业务紧密相关的关键绩效指标(KPIs),如用户满意度、转化率或响应时间,确保评测结果能够直接反映模型在真实业务中的表现。在评测准备阶段,天宽特别注重测试集的创建与选择,力求测试数据具有高度的多样性和代表性,以真实反映模型的预期使用场景。这不仅能有效避免因数据偏差导致的评测失真,还能确保模型在不同环境和条件下的一致表现,从而为实际应用提供可靠的依据。在工具和框架的选择上,天宽充分考虑项目的具体需求,精心挑选支持范围广、精确度高、效率和易用性兼备的评测工具。例如,MLPerf作为广泛应用的行业标准工具,能够对多种模型和任务进行性能测试;而TensorFlow Model Analysis则适用于深入分析TensorFlow模型的行为。在需要定制化解决方案的场景下,天宽也会开发自定义评测脚本,确保评测方案能够全面覆盖项目的特殊需求,实现对模型表现的全方位评估和优化。通过这一系统化的评测流程,天宽确保模型能够在实际业务中达到最佳性能。

实施模型能力评测时,首先运行评测测试,执行模型在预设的测试集上的推理,并收集相关的性能数据。这一过程也可以通过在线评测来完成,模拟模型在真实环境中的表现,从而获取更具参考价值的结果。随后,对测试结果进行统计和分析,运用统计方法来确定模型的性能是否达到了预期标准。如果条件允许,还可以进行A/B测试,以对比不同模型或不同版本的模型在实际场景中的表现,进一步评估其优劣。

在结果解读阶段,对于未达到标准的指标,需要深入分析可能的原因。常见的问题可能包括数据质量的不足、模型过拟合或欠拟合等。通过混淆矩阵、ROC曲线等工具,可以更深入地理解模型的行为,找到其潜在的弱点,并据此进行相应的改进或优化。

模型应用开发:基于大模型框架,天宽团队将训练好的模型集成到实际应用中,使其能够在具体的业务场景中发挥作用。例如在自动化流程、预测分析等应用中,构建智能体以应对复杂场景。同时,天宽团队会确保该系统在实际应用中的性能、稳定性及可扩展性。对需要部署在不同环境中的模型,会进行针对性的适配和优化。
模型推理部署:完成模型训练和优化后,进入推理部署阶段。天宽团队将模型打包部署为可供API调用的AI应用,使客户能够在自己的业务场景中方便地集成模型推理服务。通过API接口,客户可以实现与其他应用系统的集成,完成对大规模数据的实时处理和推理操作。天宽团队会确保部署过程中的高效性与稳定性,以应对业务中的并发需求和大数据量处理。


模型运维服务:部署完成后,天宽团队为客户提供完善的运维服务。通过现场或远程的方式,天宽团队会为客户提供后续支持,包括模型的日常巡检、性能监控、技术指导等。同时,还将提供模型升级服务,确保模型能够与最新的业务需求和技术发展同步。在遇到模型性能下降或业务调整时,天宽团队会迅速响应,并提供针对性的调优或升级方案,保障模型的长期稳定运行。
天宽科技昇腾迁移&优化服务
前期咨询:天宽具备丰富的技术实力和专业经验,可以为客户提供 NLP、CV、多模态等领域 L0 级别大模型的服务部署方案的全面规划设计。将利用大模型(商用大模型、经典开源大模型)、计算机视觉算法(例如 ResNet、YOLO 等)、以及多模态融合技术(如 CLIP 等),为客户量身定制符合其业务需求的部署方案。天宽将综合考虑模型选择、性能优化、部署架构设计、系统可扩展性以及高可用性等方面因素,确保客户能够在实际应用中充分发挥大模型的潜力,实现业务目标的有效实施。

迁移可行性分析:天宽提供全面的迁移分析服务,帮助客户将基于其他平台(如GPU)的PyTorch训练脚本顺利迁移至昇腾AI处理器。迁移前,天宽会借助msFmkTransplt工具,对客户的PyTorch训练脚本进行全面分析,确保迁移过程的高效性和成功率。该工具能够深入分析脚本中使用的算子、三方库套件、亲和API以及动态shape等方面的适配情况,并对模型迁移到昇腾平台的可行性做出详细评估。通过迁移分析,天宽团队能够快速识别训练脚本中不支持的torch API和cuda API,提供针对性优化建议,帮助提升模型在昇腾平台上的精度和性能。此外,针对三方库套件的分析,也可以帮助用户快速发现代码中不支持的第三方库API及其相关依赖项。三方库中的函数如果包含了不被支持的算子或cuda自定义算子,天宽会根据分析结果提供替代方案或进行适配优化,以保证整体系统的兼容性和稳定性。

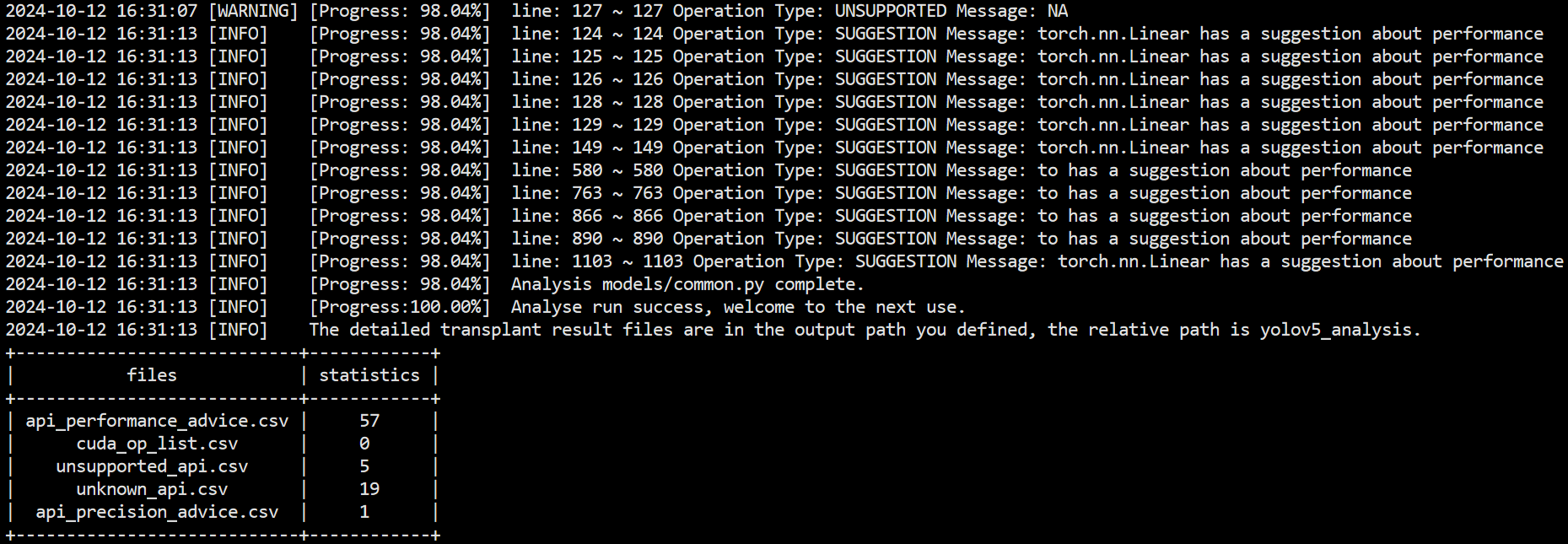
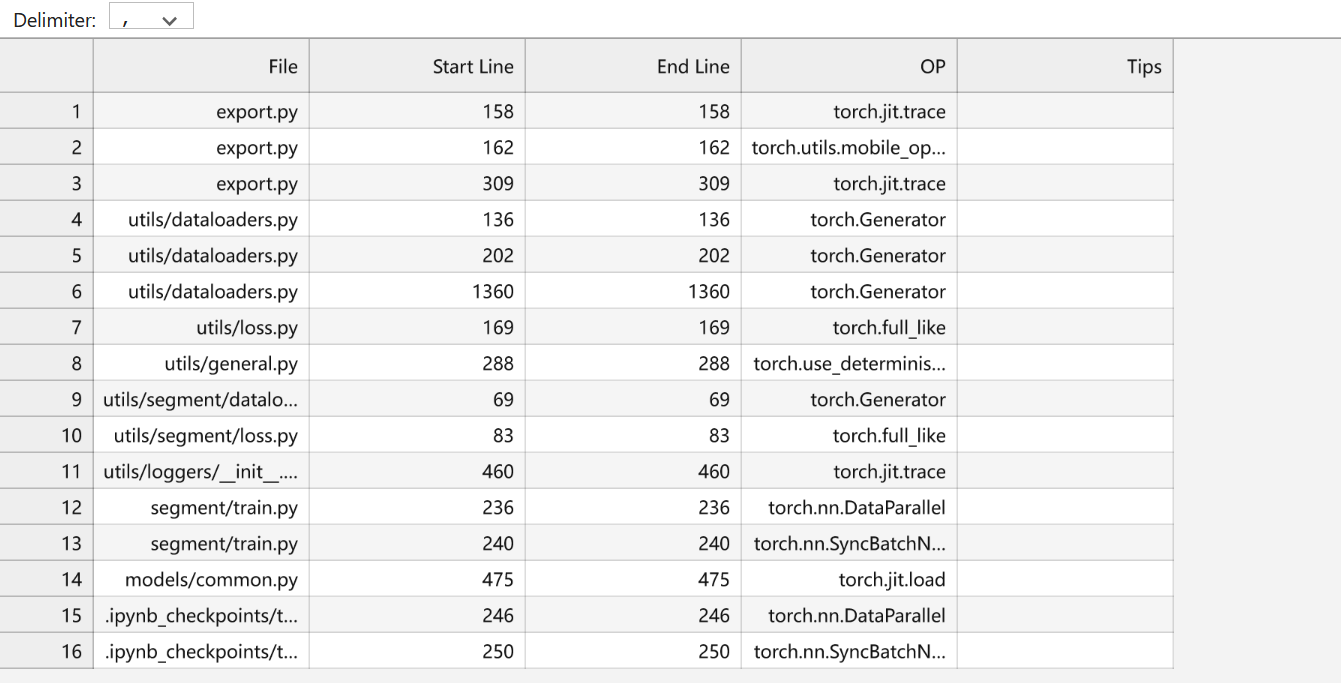
模型迁移:天宽通过三种方式完成模型迁移任务。导入import torch_npu和from torch_npu.contrib import transfer_to_npu库,可以实现自动迁移。在这种方法下,训练脚本会在运行过程中自动将CUDA接口替换为昇腾AI处理器支持的NPU接口,整个流程是在训练中动态完成转换,简化了操作,提升了效率。使用迁移工具ms_fmk_transplt是另一种迁移方式。通过这个工具,训练脚本中的CUDA接口会被自动替换为NPU接口,并生成迁移报告,其中包括脚本转换日志、不支持的算子列表和脚本修改记录。完成脚本转换后,可直接运行转换后的脚本进行训练,实现快速迁移。在手工迁移中,天宽团队通过分析模型,对比GPU和NPU接口,对训练脚本进行手动调整,以支持昇腾AI处理器的运行。手工迁移的核心在于将训练设备切换至NPU,并手动替换脚本中适配GPU的接口。在涉及多卡分布式训练时,还需要修改芯片间的通信方式,使用昇腾支持的hccl。通过这些灵活的迁移方式,天宽能够高效地满足客户不同场景下的迁移需求,并优化模型性能。


模型评估与调优
天宽凭借在多个项目中的实践,积累了丰富的大模型评测经验,能够高效且准确地定义性能指标,如准确性、召回率、精确度等标准评价维度。对于不同的业务场景,天宽还会根据具体需求设定与业务紧密相关的关键绩效指标(KPIs),如用户满意度、转化率或响应时间,确保评测结果能够直接反映模型在真实业务中的表现。在评测准备阶段,天宽特别注重测试集的创建与选择,力求测试数据具有高度的多样性和代表性,以真实反映模型的预期使用场景。这不仅能有效避免因数据偏差导致的评测失真,还能确保模型在不同环境和条件下的一致表现,从而为实际应用提供可靠的依据。在工具和框架的选择上,天宽充分考虑项目的具体需求,精心挑选支持范围广、精确度高、效率和易用性兼备的评测工具。例如,MLPerf作为广泛应用的行业标准工具,能够对多种模型和任务进行性能测试;而TensorFlow Model Analysis则适用于深入分析TensorFlow模型的行为。在需要定制化解决方案的场景下,天宽也会开发自定义评测脚本,确保评测方案能够全面覆盖项目的特殊需求,实现对模型表现的全方位评估和优化。通过这一系统化的评测流程,天宽确保模型能够在实际业务中达到最佳性能。
实施模型能力评测时,首先运行评测测试,执行模型在预设的测试集上的推理,并收集相关的性能数据。这一过程也可以通过在线评测来完成,模拟模型在真实环境中的表现,从而获取更具参考价值的结果。随后,对测试结果进行统计和分析,运用统计方法来确定模型的性能是否达到了预期标准。如果条件允许,还可以进行A/B测试,以对比不同模型或不同版本的模型在实际场景中的表现,进一步评估其优劣。


在结果解读阶段,对于未达到标准的指标,需要深入分析可能的原因。常见的问题可能包括数据质量的不足、模型过拟合或欠拟合等。通过混淆矩阵、ROC曲线等工具,可以更深入地理解模型的行为,找到其潜在的弱点,并据此进行相应的改进或优化。
模型交付:在交付阶段准备详细的评测报告,清晰地描述评测过程、结果以及优化建议。同时,提供可交互的仪表板,使非技术利益相关者也能够理解评测结果。基于评测反馈,模型架构可能需要通过增加或减少层次来进行调整,或者通过引入更多的数据预处理步骤来提升输入数据的质量。此外,自动化测试流程的设立,能够确保模型定期接受性能评估,持续满足业务需求。





