

StarRocks
StarRocks简介
StarRocks是一款高性能分析型数据仓库,使用向量化、MPP架构、CBO、智能物化视图、可实时更新的列式存储引擎等技术实现多维、实时、高并发的数据分析。
StarRocks既支持从各类实时和离线的数据源高效导入数据,也支持直接分析数据湖上各种格式的数据。
StarRocks兼容MySQL协议,可使用MySQL客户端和常用BI工具对接进行数据分析,同时StarRocks具备水平扩展、高可用、高可靠、易运维等特性,广泛应用于实时数仓、OLAP报表、数据湖分析等场景。
更多相关介绍请参见StarRocks。

该功能当前处于公测阶段,如需使用请提交工单申请开通。
StarRocks架构
StarRocks整体架构如下图所示,FE和BE节点可以水平无限扩展。
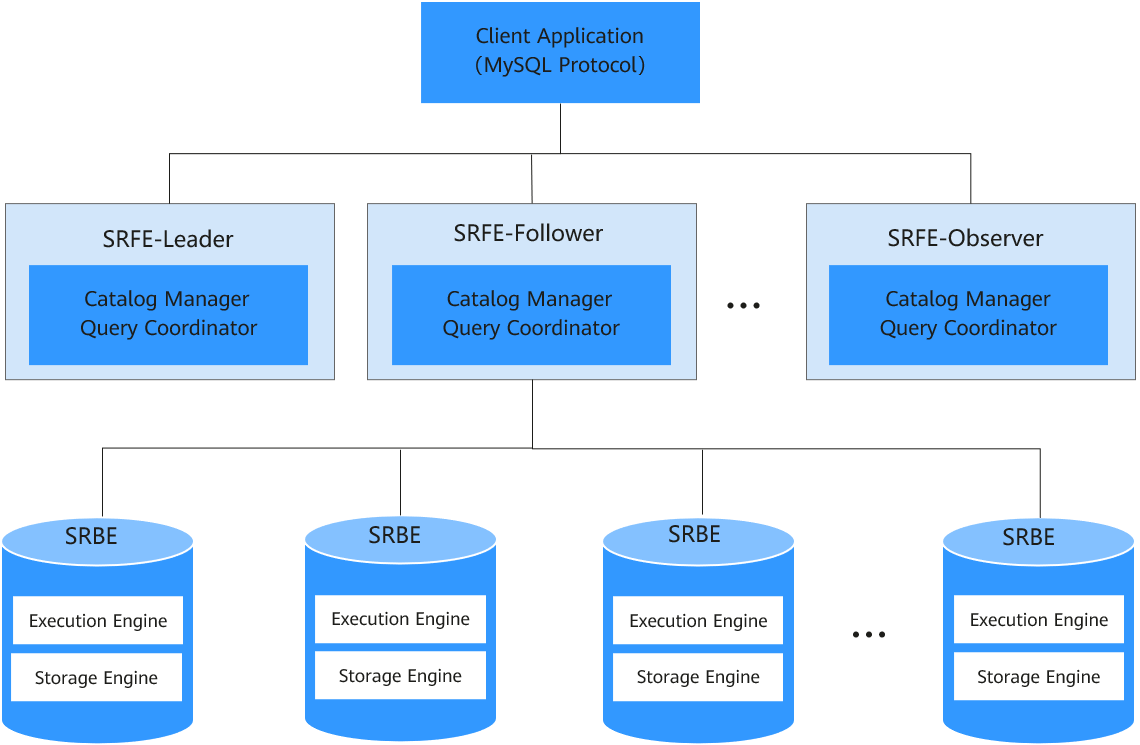
|
名称 |
说明 |
|---|---|
|
Client Application |
StarRocks兼容MySQL协议,支持标准SQL语法,用户可通过各类MySQL客户端和常用BI工具对接。 |
|
SRFE |
StarRocks的前端节点,主要负责管理元数据、管理客户端连接、进行查询规划、查询调度等工作。 |
|
SRBE |
StarRocks的后端节点,主要负责数据存储和SQL计算等工作。 |
|
Leader |
Leader从Follower中自动选出,FE Leader提供元数据读写服务,Follower和Observer只有读取权限,无写入权限。 |
|
Follower |
Follower只有元数据读取权限,无写入权限,Follower参与Leader选举。 |
|
Observer |
Observer主要用于扩展集群的查询并发能力,可选部署。Observer不参与选主,不会增加集群的选主压力。 |
StarRocks基本概念
在StarRocks中,数据都以表(Table)的形式进行逻辑上的描述。
StarRocks中的表由行和列构成,每行数据对应用户一条记录,每列数据具有相同的数据类型。所有数据行的列数相同,可以动态增删列。在StarRocks中,一张表的列可以分为维度列(也称为Key列)和指标列(也称为Value列),维度列用于分组和排序,指标列的值可以通过聚合函数sum、count、min、max、hll_union_agg和bitmap_union等累加起来。
- 列式存储
在StarRocks中,表数据按列存储。物理上,一列数据会经过分块编码、压缩等操作,然后持久化存储到非易失设备上。但在逻辑上,一列数据可以看成是由相同类型的元素构成的一个数组, 一行数据的所有列值在各自的数组中按照列顺序排列,即拥有相同的数组下标。数组下标是隐式的,不需要存储。表中所有的行按照维度列,做多重排序,排序后的位置就是该行的行号。
- 数据模型
StarRocks支持四种数据模型,分别是明细模型(Duplicate Key Model)、聚合模型(Aggregate Key Model)、更新模型(Unique Key Model)和主键模型(Primary Key Model)。
这四种数据模型能够支持多种数据分析场景,例如日志分析、数据汇总分析、实时分析等。创建表时,您需要指定数据模型(Data Model),当数据导入至数据模型时,StarRocks会按照排序键对数据进行排序、处理和存储。四种数据模型介绍如下:




