

HBase基本原理
HBase简介
HBase是一个稳定可靠,性能卓越、可伸缩、面向列的分布式云存储系统,适用于海量数据存储以及分布式计算的场景,用户可以利用HBase搭建起TB至PB级数据规模的存储系统,对数据轻松进行过滤分析,毫秒级得到响应,快速发现数据价值。
HBase适用场景有:
- 海量数据存储。
适用于TB~PB级以上的数据存储,提供动态伸缩能力,方便用户在性能或容量需要改变时,改变集群资源,轻松构建企业海量数据存储系统。
- 实时查询。
HBase的列式KeyValue存储机制,适用于企业用户明细数据即时查询,基于主键的低时延点查,响应时延一般为秒级或毫秒级,方便用户对数据的实时分析。
HBase的架构和详细原理介绍,请参见:https://hbase.apache.org/book.html
HBase原理
HBase针对PB级的海量结构化和半结构化数据,在短期内可能会出现爆炸式增长的不规律特征。HBase拥有海量数据存储引擎和强大的Key-Value查询能力,支持千万级高并发吞吐、毫秒级访问延迟,可以较好地满足互联网等企业针对BI报表、在线监控、交互式分析的业务需求。
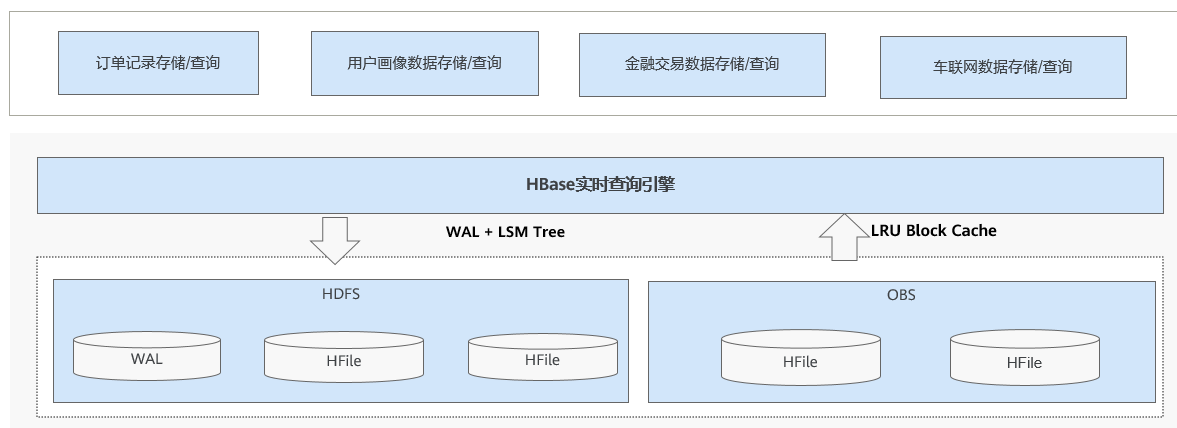
| 名称 | 描述 |
|---|---|
| HBase实时查询引擎 | HBase是一个分布式、面向列的数据库,具有高可靠性和线性扩展能力。它基于HDFS实现海量数据存储,并通过树结构和分片机制,提供毫秒级的点查询和范围扫描性能。 |
| WAL + LSM Tree | Write Ahead Log(预写日志),LSM是HBase高性能写入的核心存储架构,通过特定设计优化海量数据吞吐,数据先写入内存缓冲区(MemStore),达到阈值后批量顺序依次写入磁盘(HFile),避免频繁的小文件随机输入/输出。 |
| LRU Block Cache | 是HBase默认的堆内缓存机制,通过三层优先级(SINGLE、MULTI、MEMORY)策略管理内存中的HFile数据块(如索引块、数据块),优化读取性能并减少磁盘输入/输出。 |
| HDFS | HDFS(Hadoop Distributed File System)是HBase的分布式文件存储系统,提供高可靠性、高性能、列存储、可伸缩、实时读写等能力。 |
| OBS | 基于对象的海量存储云服务,提供安全可靠、高性能、低成本的数据存储能力。 |
| WAL | 预写式日志Write-Ahead Logging,当RegionServer故障时,用户写入的数据不丢失。 |
| HFile | HFile定义了StoreFile在文件系统中的存储格式,是HBase系统中StoreFile的具体实现。 |
HBase优势
- HBase原生接口:兼容原生HBase接口,架构高可用,计算和存储分离保证高可靠,内核深度优化。
- 易使用:支持二级索引,满足数据非主键查询需求,简单易用。
- 低成本:支持冷热分离,满足数据归档、访问频率较低历史数据存储需求,降低存储成本。
- 稳定可靠:支持热点诊断和自愈,提升系统稳定性。
- 可视化监控运维:提供常用的监控信息和自定义告警规则,简化系统运维。
- 兼容性强:兼容HBase原生接口,NoSQL引擎支持业界典型接口协议。
- SLA保证:实现平稳的TPS和时延。
- 高可用:通过HMaster HA,Region秒级转移,使有问题的磁盘不影响读写,双读机制等提供更稳定的SLA。




