

GeminiDB Mongo实例CPU使用率高问题排查
分析GeminiDB Mongo数据库正在执行的请求
- 通过Mongo Shell连接GeminiDB Mongo实例。
- 执行以下命令,查看数据库当前正在执行的操作。
回显如下:
{ "raw" : { "shard0001" : { "inprog" : [ { "desc" : "StatisticsCollector", "threadId" : "140323686905600", "active" : true, "opid" : 9037713, "op" : "none", "ns" : "", "query" : { }, "numYields" : 0, "locks" : { }, "waitingForLock" : false, "lockStats" : { } }, { "desc" : "conn2607", "threadId" : "140323415066368", "connectionId" : 2607, "client" : "xxx.xxx.xxx.xxx:xxx", "appName" : "MongoDB Shell", "active" : true, "opid" : 9039588, "secs_running" : 0, "microsecs_running" : NumberLong(63), "op" : "command", "ns" : "admin.", "query" : { "currentOp" : 1 }, "numYields" : 0, "locks" : { }, "waitingForLock" : false, "lockStats" : { } } ], "ok" : 1 }, ... }
- client:发起请求的客户端。
- opid:操作的唯一标识符。
- secs_running:该操作已经执行的时间,单位:秒。如果该字段返回的值特别大,需要查看请求是否合理。
- microsecs_running:该操作已经执行的时间,单位:微秒。如果该字段返回的值特别大,需要查看请求是否合理。
- op:操作类型。通常是query、insert、update、delete、command中的一种。
- ns:操作目标集合。
其他参数详见db.currentOp()命令官方文档。
- 根据命令执行结果,分析是否有异常耗时的请求正在执行。
如果业务日常运行的CPU使用率不高,由于执行某一操作使得CPU使用率过高,导致业务运行缓慢,该场景下,您需要关注执行耗时久的请求。
如果发现异常请求,您可以找到该请求对应的opid,执行db.killOp(opid)命令终止该请求。
分析GeminiDB Mongo数据库的慢请求
GeminiDB Mongo数据库服务默认开启了慢请求Profiling ,系统自动将请求时间超过500ms的执行情况记录到对应数据库下的“system.profile”集合中。
- 通过Mongo Shell连接GeminiDB Mongo实例。
- 执行以下命令,进入指定数据库,以“test”为例。
use test
- 查看是否生成慢sql集合“system.profile”。
show collections;
- 回显中有“system.profile”,说明产生了慢SQL,继续执行下一步。

- 回显中没有“system.profile”,说明未产生慢SQL,该数据库不涉及慢请求分析。

- 查看数据下的慢请求日志。
- 分析慢请求日志,查找CPU使用率升高的原因。
下面是某个慢请求日志示例,可查看到该请求进行了全表扫描,扫描了1561632个文档,没有通过索引进行查询。
{ "op" : "query", "ns" : "taiyiDatabase.taiyiTables$10002e", "query" : { "find" : "taiyiTables", "filter" : { "filed19" : NumberLong("852605039766") }, "shardVersion" : [ Timestamp(1, 1048673), ObjectId("5da43185267ad9c374a72fd5") ], "chunkId" : "10002e" }, "keysExamined" : 0, "docsExamined" : 1561632, "cursorExhausted" : true, "numYield" : 12335, "locks" : { "Global" : { "acquireCount" : { "r" : NumberLong(24672) } }, "Database" : { "acquireCount" : { "r" : NumberLong(12336) } }, "Collection" : { "acquireCount" : { "r" : NumberLong(12336) } } }, "nreturned" : 0, "responseLength" : 157, "protocol" : "op_command", "millis" : 44480, "planSummary" : "COLLSCAN", "execStats" : { "stage" : "SHARDING_FILTER", [3/1955] "nReturned" : 0, "executionTimeMillisEstimate" : 43701, "works" : 1561634, "advanced" : 0, "needTime" : 1561633, "needYield" : 0, "saveState" : 12335, "restoreState" : 12335, "isEOF" : 1, "invalidates" : 0, "chunkSkips" : 0, "inputStage" : { "stage" : "COLLSCAN", "filter" : { "filed19" : { "$eq" : NumberLong("852605039766") } }, "nReturned" : 0, "executionTimeMillisEstimate" : 43590, "works" : 1561634, "advanced" : 0, "needTime" : 1561633, "needYield" : 0, "saveState" : 12335, "restoreState" : 12335, "isEOF" : 1, "invalidates" : 0, "direction" : "forward", "docsExamined" : 1561632 } }, "ts" : ISODate("2019-10-14T10:49:52.780Z"), "client" : "xxx.xxx.xxx.xxx", "appName" : "MongoDB Shell", "allUsers" : [ { "user" : "__system", "db" : "local" } ], "user" : "__system@local" }在慢请求日志中,您需要重点关注以下关键字。
- 全集合(全表)扫描:COLLSCAN
当一个操作请求(如QUERY、UPDATE、DELETE)需要全表扫描时,将大量占用CPU资源。在查看慢请求日志时,发现COLLSCAN关键字,很可能是这些查询占用了CPU资源。
如果该类操作请求较为频繁,建议您对查询的字段建立索引进行优化。
- 不合理的索引:IXSCAN、keysExamined
- 索引不是越多越好,过多索引会影响写入和更新的性能。
- 如果您的应用偏向于写操作,建立索引可能会降低写操作的性能。
通过查看参数“keysExamined”的值,可以查看一个使用了索引的查询,扫描了多少条索引。该值越大,请求的CPU使用率越高。
如果索引建立不太合理,或者匹配的结果很多。该场景下,即便使用了索引,请求的CPU使用率也不会降低很多,执行的速度也会很慢。
示例:对于某个集合的数据,a字段的取值很少(只有1和2),而b字段的取值很多。
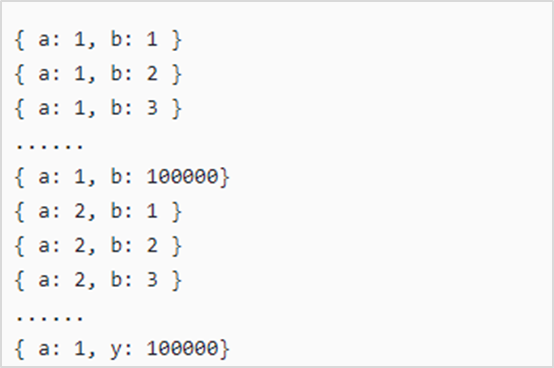
如下所示,要实现 {a: 1, b: 2} 这样的查询。
db.createIndex( {a: 1} ) 效果不好,因为a相同取值太多 db.createIndex( {a: 1, b: 1} ) 效果不好,因为a相同取值太多 db.createIndex( {b: 1 } ) 效果好,因为b相同取值很少 db.createIndex( {b: 1, a: 1 }) 效果好,因为b相同取值少关于{a: 1}与{b: 1, a: 1}的区别,可参考官方文档。
- 大量数据排序:SORT、hasSortStage
当查询请求中包含排序时,“system.profile”集合中的参数“hasSortStage”的值为“true”。如果排序无法通过索引实现,将在查询结果中进行排序。由于排序将占用大量CPU资源,该场景下,需要通过对经常排序的字段建立索引进行优化。
当您在“system.profile”集合中发现SORT关键字时,可以考虑通过索引来优化排序。
其他操作如建立索引、Aggregation(遍历、查询、更新、排序等动作的组合)也可能占用大量CPU资源,但本质上也适用以上几种场景。更多Profiling的设置,请参见官方文档。
- 全集合(全表)扫描:COLLSCAN
分析服务能力
经过前面数据库正在执行的请求和慢请求的分析和优化,所有的请求都使用了合理的索引,CPU的使用率相对趋于稳定。如果经过前面的分析排查,CPU使用率仍然居高不下,则可能是因为当前实例已达到性能瓶颈,不能满足业务需要,此时您可以通过如下方法解决。
- 通过查看监控信息分析实例资源的使用情况,详情请参见查看监控指标。
- 对GeminiDB Mongo进行规格变更或者添加分片数量。具体操作请根据当前的实例类型参考如下文档。




