
使用DRS将Oracle数据库迁移至GaussDB
操作场景
本章主要介绍如何使用DRS的实时同步功能将本地Oracle数据库实时迁移至华为云GaussDB。通过全量+增量同步,实现源数据库Oracle与目标数据库GaussDB的数据长期同步。全量同步可以实现数据迁移;增量同步可以实现实时同步源端和目标端两个库之间的数据。
解决问题
- 企业业务高速发展,传统数据库扩容性差,迫切需要分布式化改造。
- 传统数据库需要自购并安装服务器、系统、数据库等软件,运维成本高、难度大。
- 传统数据库性能瓶颈问题,复杂查询性能较差。
- 如何不中断业务并且平滑地实现数据迁移。
前提条件
- 拥有华为云账号。
- 账户余额大于等于0元。
- 如果测试使用,需要自行在本地搭建Oracle数据库。
- 已知待迁移Oracle数据库的IP地址,端口,账户和密码。
业务架构图
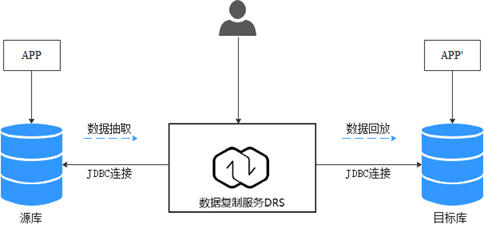
迁移原理
本次迁移使用全量+增量同步功能,原理如下:
- 全量同步阶段,先进行结构迁移,例如表、主键、唯一键的迁移。
- 结构迁移完成后,启动增量数据抽取,以确保全量数据同步期间的增量数据完整地抽取到DRS实例。
- 启动全量迁移任务。
- 全量迁移完成后自动进入增量同步,从全量迁移开始抽取的位点开始回放。
- 当增量回放全部完成后,启动比对任务进行一致性检查,支持实时比对。
- 实时比对数据一致时,可以启动业务割接。

资源规划
本章中的资源规划仅作为演示,实际业务场景资源以用户实际需求为准。
|
类别 |
子类 |
规划 |
备注 |
|---|---|---|---|
|
VPC |
VPC名称 |
vpc-src-172 |
自定义,易理解可识别。 |
|
所属Region |
测试Region |
现网实际选择时建议选择和自己业务区最近的Region,减少网络时延。 |
|
|
可用区 |
可用区3 |
- |
|
|
子网网段 |
172.16.0.0/16 |
子网选择时建议预留足够的网络资源。 |
|
|
子网名称 |
subnet-src-172 |
自定义,易理解可识别。 |
|
|
本地Oracle数据库 |
名称 |
orcl |
自定义,易理解可识别。 |
|
规格 |
16vCPUs | 32GB |
- |
|
|
数据库版本 |
11.2.0.1 |
- |
|
|
数据库用户 |
test_info |
可以自定义用户,但是迁移时最小权限为:CREATE SESSION,SELECT ANY TRANSACTION, SELECT ANY TABLE, SELECT ANY DICTIONARY, EXECUTE_CATALOG_ROLE |
|
|
GaussDB |
实例名 |
Auto-drs-gaussdbv5-tar-1 |
自定义,易理解可识别。 |
|
数据库版本 |
GaussDB V2.0-8.218企业版 |
- |
|
|
实例类型 |
分布式版,3CN,3DN,3副本 |
本示例中为分布式实例。 |
|
|
部署形态 |
独立部署 |
- |
|
|
事务一致性 |
强一致性 |
- |
|
|
分片数量 |
3 |
- |
|
|
协调节点数量 |
3 |
- |
|
|
存储类型 |
超高IO |
- |
|
|
可用区 |
可用区2 |
本示例中选择了单可用区,实际建议选择多可用区,以提高实例的高可用性。 |
|
|
性能规格 |
独享型(1:8) 8 vCPUs | 64GB |
本示例中为测试实例,选择较小的测试规格,实际选择规格以业务诉求为准。 |
|
|
存储空间 |
480GB |
本示例中为测试实例,选择较小的存储空间,实际选择存储空间大小以业务诉求为准。 |
|
|
加密磁盘 |
不加密 |
本示例中选择磁盘不加密,选择加密后会提高数据安全性,但对数据库读写性能有少量影响,实际请按照业务使用策略进行选择。 |
|
|
DAS登录数据库 |
数据库引擎 |
GaussDB |
- |
|
数据库来源 |
GaussDB |
勾选本示例中创建的GaussDB实例 |
|
|
数据库名称 |
postgres |
- |
|
|
登录用户名 |
root |
- |
|
|
密码 |
- |
本示例中创建的GaussDB实例root用户密码 |
|
|
DRS迁移任务 |
迁移任务名 |
DRS-test-info |
自定义。 |
|
目标库名称 |
test_database_info |
自定义,易理解可识别,但是需要确保兼容模式为Oracle模式。 |
|
|
源数据库引擎 |
Oracle |
- |
|
|
目标数据库引擎 |
GaussDB |
- |
|
|
网络类型 |
公网网络 |
本示例中采用公网网络。 |
- 登录华为云控制台。
- 单击管理控制台左上角的
 ,选择区域。
,选择区域。 - 单击左侧的服务列表图标,选择。进入虚拟私有云信息页面。
- 单击“创建虚拟私有云”购买VPC。
图2 基本信息
 图3 子网设置
图3 子网设置
表2 虚拟私有云参数说明 参数
说明
区域
不同区域的云服务产品之间内网互不相通,请就近选择靠近您业务的区域,可减少网络时延,提高访问速度。
名称
输入VPC的名称。要求如下:
- 长度范围为1~64位。
- 名称由中文、英文字母、数字、下划线(_)、中划线(-)、点(.)组成。
IPv4网段
设置VPC的IPv4网段范围,VPC网段的选择需要考虑以下两点:
- IP地址数量:要为业务预留足够的IP地址,防止业务扩展给网络带来冲击。
- IP地址网段:当前VPC与其他VPC、云下数据中心连通时,要避免网络两端的IP地址冲突,否则无法正常通信。
企业项目
创建VPC时,可以将VPC加入已启用的企业项目。
企业项目管理提供了一种按企业项目管理云资源的方式,帮助您实现以企业项目为基本单元的资源及人员的统一管理,默认项目为default。
高级配置 > 标签
单击
 ,展开折叠的高级配置区域,可以设置该参数。
,展开折叠的高级配置区域,可以设置该参数。您可以在创建VPC的时候为VPC绑定标签,标签用于标识云资源,可通过标签实现对云资源的分类和搜索。
高级配置 > 描述
单击
 ,展开折叠的高级配置区域,可以设置该参数。
,展开折叠的高级配置区域,可以设置该参数。您可以根据需要在文本框中输入对该VPC的描述信息。
描述信息内容不能超过255个字符,且不能包含“<”和“>”。
表3 子网参数说明 参数
说明
子网名称
输入子网的名称。要求如下:
- 长度范围为1~64位。
- 名称由中文、英文字母、数字、下划线(_)、中划线(-)、点(.)组成。
可用区
可用区是指在同一地域内,电力和网络互相独立的物理区域。在同一VPC网络内可用区与可用区之间内网互通,可用区之间能做到物理隔离。
一个区域内有多个可用区,一个可用区发生故障后不会影响同一区域内的其它可用区。
子网IPv4网段
在开启IPv4/IPv6双栈的区域,显示此参数。
设置子网的IPv4网段范围,子网是VPC内的IP地址块,可以将VPC的网段分成若干块,建议您规划子网时,遵循以下原则:
- 子网内可用IP数量:子网创建成功后,不支持修改网段,请您结合业务所需的IP地址数量,提前合理规划好子网网段。
- 子网网段不能太小,需要确保子网内可用IP地址数量可以满足业务需求。子网网段中第一个地址和后三个地址为系统预留地址,不能供实际业务使用,比如子网(10.0.0.0/24)中,10.0.0.1为网关地址、10.0.0.253为系统接口、10.0.0.254为DHCP使用、10.0.0.255为广播地址。
- 子网网段也不能太大,以免后续扩展新的业务时,VPC内可用网段不够再创建新的子网。
- 子网网段避免冲突:如果子网所在的VPC与其他VPC、或者VPC与云下数据中心需要通信时,则VPC子网网段和网络对端网段不能相同,否则无法正常通信。
如果网络两端的子网网段已经相同,您可以创建新的子网,请参见为虚拟私有云创建新的子网。
子网的网段必须在VPC网段范围内,子网网段的掩码长度范围为“子网所在VPC的掩码~29”,比如VPC网段为10.0.0.0/16,掩码为16,则子网的掩码可在16~29范围内选择。
关于VPC子网规划更详细的说明,请参见虚拟私有云和子网规划建议。
子网IPv6网段
在开启IPv4/IPv6双栈的区域,显示此参数。
开启IPv6功能后,将自动为子网分配IPv6网段,暂不支持自定义设置IPv6网段。该功能一旦开启,将不能关闭。
高级配置 > 网关
单击
 ,展开折叠的高级配置区域,可以设置该参数。
,展开折叠的高级配置区域,可以设置该参数。子网的网关,如果没有特殊需求,建议保持系统默认设置。
高级配置 > DNS服务器地址
单击
 ,展开折叠的高级配置区域,可以设置该参数。
,展开折叠的高级配置区域,可以设置该参数。此处默认填写华为云的DNS服务器地址,可实现云服务器在VPC内直接通过内网域名互相访问。同时,还支持不经公网,直接通过内网DNS访问云上服务。
若您由于业务原因需要指定其他DNS服务器地址,您可以修改默认的DNS服务器地址。如果您删除默认的DNS服务器地址,可能会导致您无法访问云上其他服务,请谨慎操作。
您也可以通过“DNS服务器地址”右侧的“重置”将DNS服务器地址恢复为默认值。
DNS服务器地址最多支持2个IP,请以英文逗号隔开。
高级配置 > 域名
单击
 ,展开折叠的高级配置区域,可以设置该参数。
,展开折叠的高级配置区域,可以设置该参数。此处填写DNS域名后缀:支持填写多个域名,不同的域名之间以空格分隔,单个字符串长度不超过63个字符(以域名test.com为例,test和com是两个字符串),并且域名总长度不超过254个字符。
访问某个域名时,只需要输入域名前缀,子网内的云服务器会自动匹配设置的域名后缀。
域名设置完成后,子网内新创建的云服务器会自动同步该配置。
子网内的存量云服务器,需要更新DHCP配置使域名生效,您可以重启云服器、重启DHCP Client服务或者重启网络服务。
说明:对于不同操作系统云服务器,更新DHCP配置的命令不同,以下命令供您参考。
- 重启DHCP Client服务:service dhcpd restart
- 重启网络服务:service network restart
高级配置 > NTP服务器地址
单击
 ,展开折叠的高级配置区域,可以设置该参数。
,展开折叠的高级配置区域,可以设置该参数。如果您需要为当前子网新增NTP服务器地址,则需要填写该地址。此处填写的地址不会影响默认NTP服务器地址。
- 新增或修改原有子网的NTP服务器地址后,需要子网内的ECS重新获取一次DHCP租约,或者重启ECS,才能生效。
- 清空NTP服务器地址时,需要子网内的ECS重新获取一次DHCP租约,重启ECS无法生效。
高级配置 > IPv4 DHCP租约时间
单击
 ,展开折叠的高级配置区域,可以设置该参数。
,展开折叠的高级配置区域,可以设置该参数。在开启IPv4/IPv6双栈的区域,显示该参数。
您可以设置IPv4地址的DHCP租约时间。
DHCP租约时间是指DHCP服务器自动分配给客户端的IP地址的使用期限。超过租约时间,IP地址将被收回,需要重新分配。- 期限租约:设置DHCP租约期限,单位为天或者小时。
- 无限租约:设置DHCP不过期。
DHCP租约时间修改后,对于子网内的实例(比如ECS)来说,当实例下一次续租时,新的租约时间将会生效。实例续租分为自动更新租约和手动更新租约两种,续租不会改变实例当前的IP地址。如果需要DHCP租约立即生效,请在实例中手动更新租约或者重启实例。
高级配置 > IPv6 DHCP租约时间
单击
 ,展开折叠的高级配置区域,可以设置该参数。
,展开折叠的高级配置区域,可以设置该参数。在开启IPv4/IPv6双栈的区域,当“子网IPv6网段”选择“开启IPv6”时,显示该参数。
您可以设置IPv6地址的DHCP租约时间。IPv6 地址和IPv4地址的租约时间设置方法、生效情况相同。
高级配置 > 标签
单击
 ,展开折叠的高级配置区域,可以设置该参数。
,展开折叠的高级配置区域,可以设置该参数。您可以在创建子网的时候为子网绑定标签,标签用于标识云资源,可通过标签实现对云资源的分类和搜索。
高级配置 > 描述
单击
 ,展开折叠的高级配置区域,可以设置该参数。
,展开折叠的高级配置区域,可以设置该参数。您可以根据需要在文本框中输入对该子网的描述信息。
描述信息内容不能超过255个字符,且不能包含“<”和“>”。
- 单击“立即创建”。
- 返回VPC列表,查看创建VPC是否创建完成。
- 登录华为云控制台。
- 单击管理控制台左上角的
 ,选择区域。
,选择区域。 - 单击左侧的服务列表图标,选择。进入虚拟私有云信息页面。
- 选择“访问控制 > 安全组”。
- 单击“创建安全组”。
- 填写安全组名称等信息。
图4 基本信息

表4 参数说明 参数
参数说明
区域
不同区域的云服务产品之间内网互不相通,请就近选择靠近您业务的区域,可减少网络时延,提高访问速度。
安全组和实例必须位于同一个区域内,才可以将实例添加到安全组内。
名称
输入安全组的名称。要求如下:- 长度范围为1~64位。
- 名称由中文、英文字母、数字、下划线(_)、中划线(-)、点(.)组成。
安全组名称创建后可以修改,建议不要重名。
企业项目
创建安全组时,可以将安全组加入已启用的企业项目。
企业项目管理提供了一种按企业项目管理云资源的方式,帮助您实现以企业项目为基本单元的资源及人员的统一管理,默认项目为default。
标签
您可以在创建安全组的时候为安全组绑定标签,标签用于标识安全组资源,可通过标签实现对安全组资源的分类和搜索。
描述
安全组的描述信息。
描述信息内容不能超过255个字符,且不能包含“<”和“>”。
- 选择“入方向规则”,单击“添加规则”。
- 配置入方向规则,添加源库的IP地址。
图5 配置入方向规则

- 单击“立即创建”。
步骤二:创建GaussDB实例
创建GaussDB实例,作为迁移任务目标库。
- 进入购买云数据库GaussDB实例页面。
- 在购买实例页面,选择“自定义购买”。参考图6,配置实例名称,选择计费模式、产品类型、数据库引擎版本、实例类型、事务一致性、分片数量、协调节点数量和可用区。
图7 实例选配

- 选择实例规格、存储空间大小。
图8 实例规格

- 选择实例所属的VPC(创建VPC)和安全组(创建安全组),配置数据库端口。
图9 选择VPC和安全组

- 配置实例密码等信息。
图10 配置实例密码等信息

- 单击“立即购买”,确认信息并提交。
- 返回实例列表。

步骤三:迁移前构造数据
迁移前需要在源库构造一些数据类型,供迁移完成后验证数据。本章中端到端的数据为测试数据,仅供参考。
DRS支持的数据类型如下所示:
|
源库数据类型 |
目标库数据类型 |
源库数据类型做主键,同步能力 |
源库数据类型做非主键,同步能力 |
源库数据类型做主键,对比能力 |
源库数据类型做非主键,对比能力 |
备注 |
|---|---|---|---|---|---|---|
|
CHAR |
character |
支持 |
支持 |
支持,忽略字符前后的空格 |
支持,忽略字符前后的空格 |
- |
|
VARCHAR |
character varying |
支持 |
支持 |
支持 |
支持 |
源目标库数据表示范围不同,存在精度损失。 |
|
VARCHAR2 |
character varying |
支持 |
支持 |
支持 |
支持 |
- |
|
NCHAR |
character |
支持 |
支持 |
支持,忽略字符前后的空格 |
支持,忽略字符前后的空格 |
- |
|
NVARCHAR2 |
nvarchar2 |
支持 |
支持 |
支持 |
支持 |
- |
|
NUMBER |
numeric |
支持 |
支持 |
支持 |
支持 |
- |
|
NUMBER (6,3) |
numeric(6,3) |
支持 |
支持 |
支持 |
支持 |
- |
|
NUMBER (6,0) |
Integer |
支持 |
支持 |
支持 |
支持 |
- |
|
NUMBER (3) |
smallint |
支持 |
支持 |
支持 |
支持 |
- |
|
NUMBER (6,-2) |
integer |
支持 |
支持 |
支持 |
支持 |
- |
|
BINARY_FLOAT |
real |
不支持(目标库不支持做主键建表) |
支持 |
不支持 |
支持 |
源目标库数据表示范围不同,存在精度损失。 |
|
BINARY_DOUBLE |
double precision |
不支持(目标库不支持做主键建表) |
支持 |
不支持 |
支持 |
- |
|
FLOAT |
real |
不支持(目标库不支持做主键建表) |
支持 |
不支持 |
支持 |
源目标库数据表示范围不同,存在精度损失。 |
|
INT |
numeric |
支持 |
支持 |
支持 |
支持 |
- |
|
INTEGER |
numeric |
支持 |
支持 |
支持 |
支持 |
- |
|
DATE |
date |
支持 |
支持 |
不支持 |
支持 |
DRS在目标库建表时类型为date,此时源目标库数据表示范围不同,存在精度损失,不支持对比。 |
|
TIMESTAMP |
timestamp(6) without time zone |
支持 |
支持 |
不支持 |
校验到小数点后6位 |
源库使用限制:支持的最大精度是6。 |
|
TIMESTAMP_TZ |
timestamp(6) with time zone |
不支持(源库不支持做主键建表) |
支持 |
不支持 |
过滤该列 |
- |
|
TIMESTAMP_LTZ |
timestamp(6) with time zone |
不支持(目标库不支持做主键建表) |
支持 |
不支持 |
过滤该列 |
- |
|
INTERVAL_YM |
interval year to month |
支持 |
支持 |
不支持 |
不支持 |
增量同步不支持该类型。 |
|
INTERVAL_DS |
interval day to second |
支持 |
支持 |
不支持 |
不支持 |
增量同步不支持该类型。源库使用限制:支持的最大精度是6。 |
|
BLOB |
bytea |
不支持(源库不支持做主键建表) |
支持 |
不支持 |
过滤该列 |
- |
|
CLOB |
text |
不支持(源库不支持做主键建表) |
支持 |
不支持 |
过滤该列 |
- |
|
NCLOB |
text |
不支持(源库不支持做主键建表) |
支持 |
不支持 |
过滤该列 |
- |
|
LONG |
text |
不支持(源库不支持做主键建表) |
支持 |
不支持 |
过滤该列 |
- |
|
LONG_RAW |
bytea |
不支持(源库不支持做主键建表) |
支持 |
不支持 |
过滤该列 |
- |
|
RAW |
bytea |
不支持(目标库不支持做主键建表) |
支持 |
不支持 |
支持 |
- |
|
RowID |
character varying(18) |
支持 |
支持 |
支持 |
支持 |
- |
|
BFILE |
- |
不支持 |
不支持 |
不支持 |
不支持 |
源库使用限制:不支持bfile类型。 |
|
XMLTYPE |
- |
不支持 |
不支持 |
不支持 |
不支持 |
源库使用限制:不支持xmltype类型。 |
|
UROWID |
- |
不支持 |
不支持 |
不支持 |
不支持 |
全量增量都不支持同步。 |
|
sdo_geometry |
- |
不支持 |
不支持 |
不支持 |
不支持 |
源库使用限制:不支持sdo_geometry类型。 |
|
NUMBER(*,0) |
numeric |
支持 |
支持 |
支持 |
支持 |
- |
执行如下步骤在源库构造数据:
- 根据本地的Oracle数据库的IP地址,通过数据库连接工具连接数据库。
- 根据DRS支持的数据类型,在源库执行语句构造数据。
- 创建一个测试用的用户。
create user test_info identified by xxx;
test_info为本次迁移创建的用户,xxx为用户的密码,请根据实际情况替换。
- 给用户赋权。
- 在当前用户下创建一个数据表。
CREATE TABLE test_info.DATATYPELIST(
ID INT,
COL_01_CHAR______E CHAR(100),
COL_02_NCHAR_____E NCHAR(100),
COL_03_VARCHAR___E VARCHAR(1000),
COL_04_VARCHAR2__E VARCHAR2(1000),
COL_05_NVARCHAR2_E NVARCHAR2(1000),
COL_06_NUMBER____E NUMBER(38,0),
COL_07_FLOAT_____E FLOAT(126),
COL_08_BFLOAT____E BINARY_FLOAT,
COL_09_BDOUBLE___E BINARY_DOUBLE,
COL_10_DATE______E DATE DEFAULT SYSTIMESTAMP,
COL_11_TS________E TIMESTAMP(6),
COL_12_TSTZ______E TIMESTAMP(6) WITH TIME ZONE,
COL_13_TSLTZ_____E TIMESTAMP(6) WITH LOCAL TIME ZONE,
COL_14_CLOB______E CLOB DEFAULT EMPTY_CLOB(),
COL_15_BLOB______E BLOB DEFAULT EMPTY_BLOB(),
COL_16_NCLOB_____E NCLOB DEFAULT EMPTY_CLOB(),
COL_17_RAW_______E RAW(1000),
COL_19_LONGRAW___E LONG RAW,
COL_24_ROWID_____E ROWID,
PRIMARY KEY(ID)
);
- 插入两行数据。
insert into test_info.DATATYPELIST values(4,'huawei','xian','shanxi','zhongguo','shijie', 666,12.321,1.123,2.123,sysdate,sysdate,sysdate,sysdate,'hw','cb','df','FF','FF','AAAYEVAAJAAAACrAAA');
insert into test_info.DATATYPELIST values(2,'Migrate-test','test1','test2','test3','test4', 666,12.321,1.123,2.123,sysdate,sysdate,sysdate,sysdate,'hw','cb','df','FF','FF','AAAYEVAAJAAAACrAAA');
- 使语句生效。
- 创建一个测试用的用户。
- 在目标端创建库。
- 登录华为云控制台。
- 单击管理控制台左上角的
 ,选择区域。
,选择区域。 - 单击左侧的服务列表图标,选择。
- 在数据管理服务DAS左侧导航栏,单击“开发工具”,进入开发工具数据库登录列表页面。
- 单击“新增数据库实例登录”,打开新增数据库实例登录窗口。
- 选择“数据库引擎”、“数据库来源”、目标实例,填写登录用户名、密码以及描述(非必填项)信息,开启SQL执行记录功能。


创建迁移任务
- 登录华为云控制台。
- 单击管理控制台左上角的
 ,选择区域。
,选择区域。
选择目标实例所在的区域。
- 单击左侧的服务列表图标,选择。
- 左侧导航栏选择“实时同步管理”,单击“创建同步任务”。
- 配置同步实例信息。
- 配置源库及目标库信息。
- 设置同步。
- 高级设置。

- 数据加工。
- 预检查。
- 任务确定。
- 任务创建成功。

















步骤五:迁移后进行数据校验
当任务状态变为“增量同步”,说明全量同步已经完成,全量同步完成后,登录GaussDB查看数据迁移结果。
- 等待迁移任务状态变为“增量同步”。
- 单击任务名称,进入任务详情页。
- 在“同步进度”页签查看全量同步结果。
如图所示,本次迁移将TEST_INFO库中DATATYPELIST表迁移至shard_0,共迁移了两条数据。

- 验证数据一致性。
- 通过DAS连接GaussDB的目标库“test_database_info ”。
- 执行如下语句,查询全量同步结果。
SELECT * FROM test_info.datatypelist_after;
Oracle数据库中的模式迁移完成后,会在GaussDB库中作为Schema,所以查询语句中添加Schema精确查询。
如图所示,查询表中的各个数据类型都迁移成功,并且数据正确无误。

- 验证增量同步。
- 结束迁移任务。
- 迁移完成后,进行性能测试。
测试云数据库GaussDB性能的方法请参见性能白皮书。










