
层级队列
在多租户场景中,队列是实现公平调度、资源隔离和任务优先级控制的核心机制。而在实际应用中,不同队列往往隶属于不同部门,部门之间存在层级关系,传统平级队列的资源管理无法满足实际需要。为此,Volcano调度器引入层级队列,通过将队列按层级结构组织,实现不同层级间的资源分配、共享与抢占。通过这一功能,用户可以在层级队列的基础上实现更细粒度的资源配额管理,构建更高效的统一调度平台。
层级队列功能简介
层级队列是Volcano调度器中的一种高级队列管理机制,用于在多租户集群环境中实现资源的层次化分配和隔离。通过树形结构组织队列,支持以下功能:
- 支持配置队列层级关系。Volcano调度器在Queue spec中新增了parent属性,在创建队列时可以通过parent参数指定该队列所属的父队列:
type QueueSpec struct { ... // 指定队列所属的父队列 Parent string `json:"parent,omitempty" protobuf:"bytes,8,opt,name=parent"` ... }Volcano Scheduler在启动后会默认创建一个root队列,作为所有队列的根队列,用户可以基于root队列进一步构建层级队列树。
- 支持为每个维度的资源设置队列容量上限capability(超过队列资源上限的Pod无法被调度)、资源应得量deserved(若队列已分配资源量超过设置的deserved值,则资源超出部分可能被回收)以及资源预留量guarantee(表示当前队列预留资源,无法与其他队列共享)。
- 支持跨层级队列任务间资源共享与回收。在无其他队列提交任务时,集群中的队列可以共享使用这些队列超过所有预留量之外部分的资源,队列内任务所占资源量可超过deserved值;同时当多个队列提交任务且集群资源无法支撑Pod部署时,可以回收被其他层级队列共享使用的Pod资源。
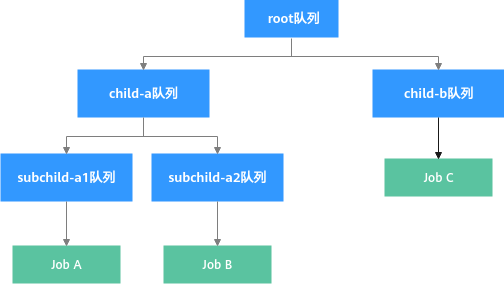
如图1,Job A和Job C先提交,且其队列已分配资源量皆超过设置的deserved值。当集群资源不够满足Job B要求,则系统会尝试回收Job A和Job C的资源。
前提条件
- 已创建及以上版本的CCE Standard/Turbo集群,具体步骤请参见购买Standard/Turbo集群。
- 已安装Volcano插件,且插件版本在及以上,具体步骤请参见Volcano调度器。
约束与限制
- 层级队列资源管理调度仅支持CPU、内存和原生异构资源(如nvidia.com/gpu),不支持虚拟化异构资源。
配置层级队列策略
配置层级队列策略后,您可以自定义队列间层级关系,实现跨层级队列的资源共享与回收,进而实现更细粒度的资源配额管理。
- 登录CCE控制台,单击集群名称进入集群。
- 在左侧导航栏中选择“配置中心”,在右侧切换至“调度配置”页签。
- 在Volcano调度器配置中,“层级队列”默认关闭,需进一步修改调度器配置参数以开启“层级队列”功能。
- 在“设置集群默认调度器 > 专家模式”中,单击“开始使用”。 图2 “专家模式 > 开始使用”

- 层级队列能力基于capacity插件构建,请确认调度器配置中已经打开capacity插件,并且将enableHierarchy设置为true,以开启层级队列能力。同时需要打开reclaim action,支持队列间的资源回收。当队列资源紧张时,将触发资源回收机制,系统将优先回收超出队列deserved值的资源,并结合队列/任务优先级选择合适的回收对象。
如果需要使用GPU资源的队列间共享回收能力,需要将配置项enable_topology_aware_preemption的值设置为true,用于实现GPU跨卡资源的回收抢占。

capacity和proportion插件是相互冲突的,请确保使用capacity插件时已移除proportion插件配置,并将capacity添加在下面YAML示例所在tier层级位置。
在YAML配置文件中,添加如下参数:... default_scheduler_conf: actions: allocate, backfill, preempt, reclaim # 开启reclaim action metrics: interval: 30s type: '' tiers: - plugins: - name: priority - enableJobStarving: false enablePreemptable: false enableReclaimable: false name: gang - name: conformance - name: capacity # 确认开启capacity插件 enableHierarchy: true # 确认开启层级队列 - plugins: - enablePreemptable: false enableReclaimable: false name: drf - name: predicates - name: nodeorder - arguments: binpack.cpu: 1 binpack.memory: 1 binpack.resources: nvidia.com/gpu binpack.resources.nvidia.com/gpu: 2 binpack.weight: 10 name: binpack ... descheduler_enable: 'false' deschedulingInterval: 10m enable_scale_in_score: true enable_topology_aware_preemption: true # 使用GPU资源的队列间共享与回收能力时,需要开启拓扑感知抢占开关 enable_workload_balancer: false oversubscription_method: nodeResource ... - 参数填写完成后,在右下角单击“保存”。
- 在“设置集群默认调度器 > 专家模式”中,单击“开始使用”。
- 完成上述配置后,单击右下角“确认配置”。在“确认配置”弹窗中,确认修改信息,无误后单击“保存”。
层级队列使用示例
假设集群中CPU和内存资源剩余可用量分别为8核、16Gi。首先,创建一个层级队列树。其次,创建2个Volcano job job-a和job-c将集群资源耗尽。最后,创建Volcano job job-b,查看层级队列中的资源回收流程。本示例的整体结构图请参见图3。

- 执行以下命令,创建层级队列树的YAML文件。
vim hierarchical_queue.yaml文件内容如下:
# child-queue-a的父队列为root队列 apiVersion: scheduling.volcano.sh/v1beta1 kind: Queue metadata: name: child-queue-a spec: reclaimable: true parent: root capability: cpu: "5" memory: "10Gi" deserved: cpu: "4" memory: "8Gi" guarantee: resource: cpu: "2" memory: "4Gi" --- # child-queue-b的父队列为root队列 apiVersion: scheduling.volcano.sh/v1beta1 kind: Queue metadata: name: child-queue-b spec: reclaimable: true parent: root deserved: cpu: "2" memory: "4Gi" --- # subchild-queue-a1的父队列为child-queue-a队列 apiVersion: scheduling.volcano.sh/v1beta1 kind: Queue metadata: name: subchild-queue-a1 spec: reclaimable: true parent: child-queue-a #可根据需要设置deserved,队列已分配资源若已超过deserved值,则队列中资源可能被回收 deserved: cpu: "2" memory: "4Gi" --- # subchild-queue-a2的父队列为child-queue-a队列 apiVersion: scheduling.volcano.sh/v1beta1 kind: Queue metadata: name: subchild-queue-a2 spec: reclaimable: true parent: child-queue-a #可根据需要设置deserved,队列已分配资源若已超过deserved值,则队列中资源可能被回收 deserved: cpu: "2" memory: "4Gi"
以child-queue-a的YAML文件为例,介绍层级队列的相关参数。更多参数信息,请参见Queue。
表1 层级队列参数说明 参数
示例
说明
reclaimable
true
可选参数,用于开启资源回收策略,默认值为true。
- true:该队列资源使用量超过其deserved时,允许其他队列回收该队列超额使用的资源。
- false:不允许其他队列回收该队列超额使用的资源。
parent
root
可选参数,用于指定该队列的父队列,使队列形成层级关系,子队列资源总量受父队列限制。若未指定parent,则父队列默认为root。
capability
cpu: "5"
memory: "10Gi"
可选参数,用于指定该队列的资源上限,具体数值不能超过父队列的capability值。超过该上限部分的Pod将无法调度。
如果某个队列未设置某一维度资源的capability值,则该维度的capability将继承自其父队列的设置。如果父队列及其所有祖先队列均未设置,则最终继承自root队列的配置,root队列的capability默认设置为无限大。
deserved
cpu: "4"
memory: "8Gi"
用于指定该队列的资源应得量,具体数值需小于等于capability。在一层队列场景,建议所有队列的值总和不超过集群资源总量;多层队列场景时,子队列的deserved总和不能超过父队列配置的deserved值。
若当前队列中已分配的资源量超过自身的deserved值,则该队列不可再回收其他队列中的资源,但可以被其他队列回收(队列中的Pod会被驱逐); 若当前队列中已分配的资源量减去待被驱逐的Pod资源请求量小于队列的deserved值,则该Pod不可被驱逐(即只允许回收超过deserved部分资源);若队列未配置deserved则取值默认为0,队列所用资源都可被回收。
guarantee
cpu: "2"
memory: "4Gi"
可选参数,用于指定该队列的资源预留量。预留资源只可被该队列所使用,其他队列无法使用。
子队列的guarantee总和不能超过父队列配置的guarantee值,且队列的guarantee值需小于等于deserved。若队列未配置guarantee则取值默认为0。
- 执行以下命令,创建层级队列树。
kubectl apply -f hierarchical_queue.yaml
回显结果如下:
queue.scheduling.volcano.sh/child-queue-a created queue.scheduling.volcano.sh/child-queue-b created queue.scheduling.volcano.sh/subchild-queue-a1 created queue.scheduling.volcano.sh/subchild-queue-a2 created
- 执行以下命令,创建Volcano job job-a和job-b的YAML文件,job-a和job-b分别属于subchild-queue-a1和child-queue-b层级队列。
vim vcjob.yaml文件内容如下:
# 提交job-a到叶子队列subchild-queue-a1中 apiVersion: batch.volcano.sh/v1alpha1 kind: Job metadata: name: job-a spec: queue: subchild-queue-a1 schedulerName: volcano minAvailable: 1 tasks: - replicas: 3 name: test template: spec: containers: - image: nginx imagePullPolicy: IfNotPresent name: nginx resources: requests: cpu: "1" memory: "2Gi" --- # 提交job-c到叶子队列child-queue-b中 apiVersion: batch.volcano.sh/v1alpha1 kind: Job metadata: name: job-c spec: queue: child-queue-b schedulerName: volcano minAvailable: 1 tasks: - replicas: 5 name: test template: spec: containers: - image: nginx imagePullPolicy: IfNotPresent name: nginx resources: requests: cpu: "1" memory: "2Gi"
- 执行以下命令,创建job-a和job-c。
kubectl apply -f vcjob.yaml
回显结果如下:
job.batch.volcano.sh/job-a created job.batch.volcano.sh/job-c created
- 执行以下命令,查看Pod的运行情况。
kubectl get pod
回显结果如下,所有Pod的STATUS皆为Running,此时集群CPU和内存资源皆已耗尽。
NAME READY STATUS RESTARTS AGE job-a-test-0 1/1 Running 0 3h21m job-a-test-1 1/1 Running 0 3h31m job-a-test-2 1/1 Running 0 3h31m job-c-test-0 1/1 Running 0 24m job-c-test-1 1/1 Running 0 24m job-c-test-2 1/1 Running 0 24m job-c-test-3 1/1 Running 0 24m job-c-test-4 1/1 Running 0 24m
- 执行以下命令,创建Volcano job job-b的YAML文件。
vim vcjob1.yaml文件内容如下:
# 提交job-b到叶子队列subchild-queue-a2中 apiVersion: batch.volcano.sh/v1alpha1 kind: Job metadata: name: job-b spec: queue: subchild-queue-a2 schedulerName: volcano minAvailable: 1 tasks: - replicas: 2 name: test template: spec: containers: - image: nginx imagePullPolicy: IfNotPresent name: nginx resources: requests: cpu: "1" memory: "2Gi"
- 执行以下命令,创建job-b。
kubectl apply -f vcjob1.yaml
回显结果如下:
job.batch.volcano.sh/job-b created
由于集群CPU和内存资源已耗尽,job-b将触发资源回收机制。
- 由于其兄弟队列中的job-a实际占用资源(3CPU/6Gi内存)已超过所属队列subchild-queue-a1的deserved值(2CPU/4Gi内存),超占部分(1CPU/2Gi内存)可被回收,但该回收量仍不满足job-b需求。
- 由于subchild-queue-a1队列可被回收资源不足,job-b将沿队列层级向上查找,最终定位到child-queue-b队列中的job-c进行跨队列资源回收。
- 执行以下命令,查看Pod运行情况,验证系统是否回收相关资源。
kubectl get pod
回显结果如下,则说明系统正在回收资源。NAME READY STATUS RESTARTS AGE job-a-test-0 1/1 Running 0 3h33m job-a-test-1 1/1 Running 0 3h33m job-a-test-2 1/1 Terminating 0 3h33m job-b-test-0 0/1 Pending 0 1m job-b-test-1 0/1 Pending 0 1m job-c-test-0 1/1 Running 0 26m job-c-test-1 1/1 Running 0 26m job-c-test-2 1/1 Running 0 26m job-c-test-3 1/1 Running 0 26m job-c-test-4 1/1 Terminating 0 26m
稍等几分钟后,再次执行以上命令查看Pod的运行情况。回显结果如下,则说明job-b已成功运行。
NAME READY STATUS RESTARTS AGE job-a-test-0 1/1 Running 0 3h35m job-a-test-1 1/1 Running 0 3h35m job-a-test-2 0/1 Pending 0 3h35m job-b-test-0 1/1 Running 0 2m job-b-test-1 1/1 Running 0 2m job-c-test-0 1/1 Running 0 28m job-c-test-1 1/1 Running 0 28m job-c-test-2 1/1 Running 0 28m job-c-test-3 1/1 Running 0 28m job-c-test-4 0/1 Pending 0 28m
相关文档
- 了解更多队列信息,请参见队列资源管理调度(Capacity)。
- 了解更多Volcano调度信息,请参见Volcano调度概述。




