
工作负载伸缩原理
|
伸缩策略 |
HPA策略 |
CronHPA策略 |
CustomedHPA策略 |
VPA策略 |
AHPA策略 |
|---|---|---|---|---|---|
|
策略介绍 |
Kubernetes中实现POD水平自动伸缩的功能,即Horizontal Pod Autoscaling。 |
基于HPA策略的增强能力,主要面向应用资源使用率存在周期性变化的场景。 |
CCE自研的弹性伸缩增强能力,可实现基于指标触发或定时触发弹性伸缩。 |
Kubernetes中实现POD垂直自动伸缩的功能,即Vertical Pod Autoscaling。 |
AHPA策略即Advanced Horizontal Pod Autoscaling,可以根据历史数据提前进行扩缩容动作。 |
|
策略规则 |
基于指标(CPU利用率、内存利用率),对无状态工作负载的副本数进行弹性扩缩容。 |
基于周期(每天、每周、每月或每年的具体时间点),对无状态工作负载的副本数进行弹性扩缩容。 |
基于指标(CPU利用率、内存利用率)或周期(每天、每周、每月或每年的具体时间点),对无状态工作负载的副本数进行弹性扩缩容。 |
基于容器资源(CPU、内存)历史使用情况,对工作负载的资源申请量进行扩缩容。 |
基于容器资源(CPU、内存)历史使用情况进行预测,提前对工作负载副本数进行弹性扩缩容。 |
|
主要功能 |
在Kubernetes社区HPA功能的基础上,增加了应用级别的冷却时间窗和扩缩容阈值等功能。 |
CronHPA提供HPA对象的兼容能力,您可以同时使用CronHPA与HPA。
|
指标触发
周期触发 支持选择天、周、月或年的具体时间点或周期作为触发时间 |
根据CPU、内存历史使用情况自动计算建议值,并调整Pod资源申请量。 |
根据业务历史指标,识别工作负载弹性周期并对未来波动进行预测,提前进行扩缩容动作,解决原生HPA的滞后问题。 |
|
使用方式 |
HPA工作原理
HPA(Horizontal Pod Autoscaler)是用来控制Pod水平伸缩的控制器,HPA周期性检查Pod的度量数据,计算满足HPA资源所配置的目标数值所需的副本数量,进而调整目标资源(如Deployment)的replicas字段。
想要做到自动弹性伸缩,先决条件就是能感知到各种运行数据,例如集群节点、Pod、容器的CPU、内存使用率等等。而这些数据的监控能力Kubernetes也没有自己实现,而是通过其他项目来扩展Kubernetes的能力,Kubernetes提供Prometheus和Metrics Server插件来实现该能力:
- Prometheus是一套开源的系统监控报警框架,能够采集丰富的Metrics(度量数据),目前已经基本是Kubernetes的标准监控方案。
- Metrics Server是Kubernetes集群范围资源使用数据的聚合器。Metrics Server从kubelet公开的Summary API中采集度量数据,能够收集包括了Pod、Node、容器、Service等主要Kubernetes核心资源的度量数据,且对外提供一套标准的API。
使用HPA(Horizontal Pod Autoscaler)配合Metrics Server可以实现基于CPU和内存的自动弹性伸缩,再配合Prometheus还可以实现自定义监控指标的自动弹性伸缩。
HPA主要流程如图1所示。

HPA的核心有如下2个部分:
- 监控数据来源
最早社区只提供基于CPU和内存的HPA,随着应用越来越多搬迁到K8s上以及Prometheus的发展,开发者已经不满足于CPU和内存,开发者需要应用自身的业务指标,或者是一些接入层的监控信息,例如:Load Balancer的QPS、网站的实时在线人数等。社区经过思考之后,定义了一套标准的Metrics API,通过聚合API对外提供服务。
- metrics.k8s.io: 主要提供Pod和Node的CPU和Memory相关的监控指标。
- custom.metrics.k8s.io: 主要提供Kubernetes Object相关的自定义监控指标。
- external.metrics.k8s.io:指标来源外部,与任何的Kubernetes资源的指标无关。
- 扩缩容决策算法
HPA controller根据当前指标和期望指标来计算缩放比例,计算公式如下:
期望实例数 = 向上取整[当前实例数 * ( 当前的指标值 / 目标值 )]
例如当前的指标值是200m,目标值是100m,那么按照公式计算期望的实例数就会翻倍。那么在实际过程中,可能会遇到实例数值反复伸缩,导致集群震荡。为了保证稳定性,HPA controller从以下几个方面进行优化:
- 冷却时间:在1.11版本以及之前的版本,社区引入了horizontal-pod-autoscaler-downscale-stabilization-window和horizontal-pod-autoScaler-upscale-stabilization-window这两个启动参数代表缩容冷却时间和扩容冷却时间,这样保证在冷却时间内,跳过扩缩容。1.14版本之后引入延迟队列,保存一段时间内每一次检测的决策建议,然后根据当前所有有效的决策建议来进行决策,从而保证期望的副本数尽量少地发生变更,保证稳定性。
- 忍受度:可以看成一个缓冲区,当实例变化范围在忍受范围之内的话,保持原有的实例数不变。
当|ratio – 1.0| <= 忍受度时,则会忽略,跳过scale。
当|ratio – 1.0| > 忍受度时, 就会根据之前的公式计算期望值。
当前社区版本中默认值为0.1。
HPA是基于指标阈值进行伸缩的,常见的指标主要是 CPU、内存,也可以通过自定义指标,例如QPS、连接数等进行伸缩。但是存在一个问题:基于指标的伸缩存在一定的时延,这个时延主要包含:采集时延(分钟级) + 判断时延(分钟级) + 伸缩时延(分钟级)。这个分钟级的时延,可能会导致应用CPU飚高,响应时间变慢。为了解决这个问题,CCE提供了定时策略,对于一些有周期性变化的应用,提前扩容资源,而业务低谷时,定时回收资源。
CronHPA工作原理
CronHPA(Cron Horizontal Pod Autoscaler)是Kubernetes中的一种基于时间的自动扩展机制,用于在特定时间段内根据预设的规则自动调整Pod的数量。
- 用户定义CronHPA CRD
用户通过Kubernetes YAML文件定义CronHPA资源,指定时间规则、最小/最大副本数等。
- CronHPA Controller 监控
CronHPA Controller会定期检查当前时间和定义的Cron表达式,判断是否需要执行扩缩容操作。
- 时间匹配
当前时间与Cron表达式匹配时,CronHPA Controller会触发扩缩容操作。
- 调整副本数量
CronHPA Controller通过Kubernetes API调用,调整ReplicaSet、Deployment或StatefulSet的副本数量。
- Pod数量变化
目标控制器(如Deployment)根据新的副本数量创建或删除Pod,以实现自动扩缩容。
VPA工作原理
Vertical Pod Autoscaler(VPA)是Kubernetes中的一种自动扩展机制,用于根据Pod的资源使用情况动态调整Pod的资源请求和限制。与HPA主要通过增加或减少Pod的数量来应对负载变化不同,VPA通过调整单个Pod的资源请求和限制,确保每个Pod能够获得更合适的资源分配。
VPA主要包含三个组件:
- VPA Recommender:根据历史数据给出Pod资源调整建议。
- VPA Updater:对比建议值和当前值,不一致时重建Pod。
- VPA Admission Controller:在Pod重建时将Pod的资源申请量修改为建议值。

VPA生效的主要流程如下:
- 首先VPA Recommender组件会根据Pod的资源使用情况历史数据计算出Pod资源调整建议值。
- VPA Updater对比Pod资源当前值与VPA建议值是否一致。
- VPA Updater检测到Pod资源当前值与建议值不一致时,重建Pod以根据建议值调整规格。
- Pod发生重建时,VPA Admission Controller会进行拦截,确保资源请求和限制与建议值一致。
- 完成VPA调整,使用VPA建议值作为Pod的资源申请值。
AHPA工作原理
Advanced Horizontal Pod Autoscaler (AHPA) 是一种更高级的自动扩缩容策略,它在传统的Horizontal Pod Autoscaler (HPA) 基础上增加了更多的功能和灵活性,解决更复杂的扩缩容需求,比如预测性扩缩容等。
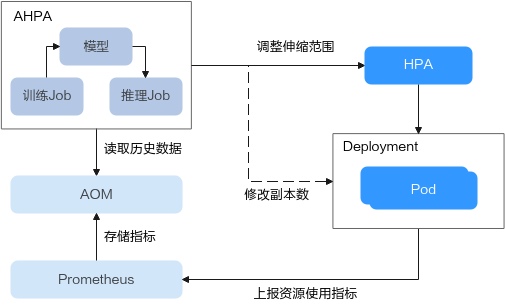
AHPA工作生效流程如下:
- Prometheus采集Deployment资源使用数据,并上报至AOM进行储存。
- 训练Job:周期性读取AOM中各Deployment的数据,并更新模型,为推理Job提供引擎。
- 推理Job:根据模型推理,调整HPA伸缩范围或Deployment副本数,默认调整周期为1分钟。




