
更新时间:2024-05-07 GMT+08:00
record
record类型的变量
创建一个record变量的方式:
定义一个record类型 ,然后使用该类型来声明一个变量。
语法
record类型的语法参见图1。
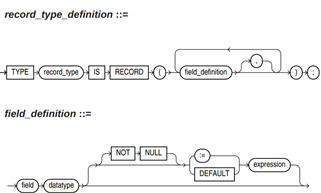
对以上语法格式的解释如下:
- record_type:声明的类型名称。
- field:record类型中的成员名称。
- datatype:record类型中成员的类型。
- expression:设置默认值的表达式。

在GaussDB中:
- record类型变量的赋值支持:
- 在函数或存储过程的声明阶段,声明一个record类型,并且可以在该类型中定义成员变量。
- 一个record变量到另一个record变量的赋值。
- SELECT INTO和FETCH向一个record类型的变量中赋值。
- 将一个NULL值赋值给一个record变量。
- 不支持INSERT和UPDATE语句使用record变量进行插入数据和更新数据。
- 不支持record类型的构造器作为函数或存储过程参数的默认值。
- 通过package_name.record_type声明record变量时,record类型的默认值功能会失效,建议不要在record类型有默认值时使用package_name.record_type声明record变量。
- 如果成员有复合类型,在声明阶段不支持指定默认值,该行为同声明阶段的变量一样。
- 如果成员有record类型,则内层record类型的默认值不会传递至外层record类型中。
- 设置enable_recordtype_check_strict = on后,成员是record类型,且record类型有列具有not null属性或defalut属性,在存储过程或PACKAGE编译时会报错。
- 设置enable_recordtype_check_strict = on后,当PACKAGE里有record类型,且record类型有列具有not null属性或defalut属性会在创建或编译时报错。
- 设置enable_recordtype_check_strict = on后,存储过程里的record类型not null功能生效。
- datatype可以为存储过程中定义record类型、数组类型和集合类型(匿名块不支持)。
- 打开guc参数 set behavior_compat_options = 'proc_outparam_override' 后:
- 带有out出参且返回record的函数,支持在外部SQL使用SELECT、CALL调用,在存储过程内支持使用PERFORM、表达式调用。
- 在函数直接返回未定义的record类型时,至少需要带有一个out参数;如果返回的是已经定义的record类型,则可以不带out参数。详见示例。
- 带out出参返回复合类型或record的函数,需要保持函数的预期返回类型与实际返回类型一致。
示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 |
下面示例中用到的表定义如下: gaussdb=# \d emp_rec Table "public.emp_rec" Column | Type | Modifiers ----------+--------------------------------+----------- empno | numeric(4,0) | not null ename | character varying(10) | job | character varying(9) | mgr | numeric(4,0) | hiredate | timestamp(0) without time zone | sal | numeric(7,2) | comm | numeric(7,2) | deptno | numeric(2,0) | --演示在函数中对数组进行操作。 gaussdb=# CREATE OR REPLACE FUNCTION regress_record(p_w VARCHAR2) RETURNS VARCHAR2 AS $$ DECLARE --声明一个record类型. type rec_type is record (name varchar2(100), epno int); employer rec_type; --使用%type声明record类型 type rec_type1 is record (name emp_rec.ename%type, epno int not null :=10); employer1 rec_type1; --声明带有默认值的record类型 type rec_type2 is record ( name varchar2 not null := 'SCOTT', epno int not null :=10); employer2 rec_type2; CURSOR C1 IS select ename,empno from emp_rec order by 1 limit 1; BEGIN --对一个record类型的变量的成员赋值。 employer.name := 'WARD'; employer.epno = 18; raise info 'employer name: % , epno:%', employer.name, employer.epno; --将一个record类型的变量赋值给另一个变量。 employer1 := employer; raise info 'employer1 name: % , epno: %',employer1.name, employer1.epno; --将一个record类型变量赋值为NULL。 employer1 := NULL; raise info 'employer1 name: % , epno: %',employer1.name, employer1.epno; --获取record变量的默认值。 raise info 'employer2 name: % ,epno: %', employer2.name, employer2.epno; --在for循环中使用record变量 for employer in select ename,empno from emp_rec order by 1 limit 1 loop raise info 'employer name: % , epno: %', employer.name, employer.epno; end loop; --在select into 中使用record变量。 select ename,empno into employer2 from emp_rec order by 1 limit 1; raise info 'employer name: % , epno: %', employer2.name, employer2.epno; --在cursor中使用record变量。 OPEN C1; FETCH C1 INTO employer2; raise info 'employer name: % , epno: %', employer2.name, employer2.epno; CLOSE C1; RETURN employer.name; END; $$ LANGUAGE plpgsql; --调用该函数。 gaussdb=# CALL regress_record('abc'); --删除函数。 gaussdb=# DROP FUNCTION regress_record; --函数表达式return record示例(必须打开兼容性参数proc_outparam_override) set behavior_compat_options = 'proc_outparam_override'; create or replace package pkg is type rec_type is record(c1 int, c2 int); function test1(col1 out int,col2 out int) return rec_type; end pkg; / create or replace package body pkg as function test1(col1 out int, col2 out int) return rec_type is r rec_type; begin r.c1:=300; r.c2:=400; col1:=100; col2:=200; return r; end; end pkg; / declare res pkg.rec_type:=pkg.rec_type(); a int; b int; begin res:=pkg.test1(a,b); raise info 'a: %, b: %',a,b; raise info '%', res; end; / -- 打开兼容性参数proc_outparam_override时,返回已定义的record类型,函数可以不需out参数 create type rec_type is (c1 int, c2 int); create or replace function func(a in int) return rec_type as declare r rec_type; begin r.c1:=1; r.c2:=2; return r; end; / call func(0); -- 打开兼容性参数proc_outparam_override时,函数直接返回未定义的record类型时,至少需要带有一个out参数 create or replace function func(a in int) return record as declare type rc is record(c1 int); r rc; begin r.c1:=1; a:=1; return r; end; / call func(1); |
父主题: 数组、集合和record




