
Creating a Voice Modeling Task (with Third-party Models)
You can view the preset voices of MetaStudio on the Video Production or Livestreams page. If the preset voices cannot meet your requirements, you can use the third-party model DupDub to customize a voice:
- Chinese, English, Cantonese, German, French, Turkish, Tagalog, Japanese, Italian, Malay, Russian, Korean, Finnish, Dutch, Spanish, Indonesian, Arabic, and Portuguese can be input for voice modeling. See Procedure (for DupDub).
- 17 languages (Chinese, English, German, French, Turkish, Tagalog, Japanese, Italian, Malay, Russian, Korean, Finnish, Spanish, Indonesian, Arabic, Portuguese, and Dutch; Thai not available yet) are supported in an output voice model that uses a non-preset voice for speech synthesis.
Constraints
Only enterprise users can customize voices on MetaStudio.
Preparations
Before creating a voice modeling task, see Procedure (for DupDub).
- If you select Script Upload, record an audio in advance by referring to the recording guide on the voice modeling page.
- Purchase and activate a DupDub non-English/Chinese language cloning package by referring to Purchasing a DupDub Voice Package.
Procedure (for DupDub)
- Log in to the MetaStudio console and go to the Overview page.
- Click Go to MetaStudio Console to go to the MetaStudio console.
- Click the Voice Modeling card to go to the voice modeling page.
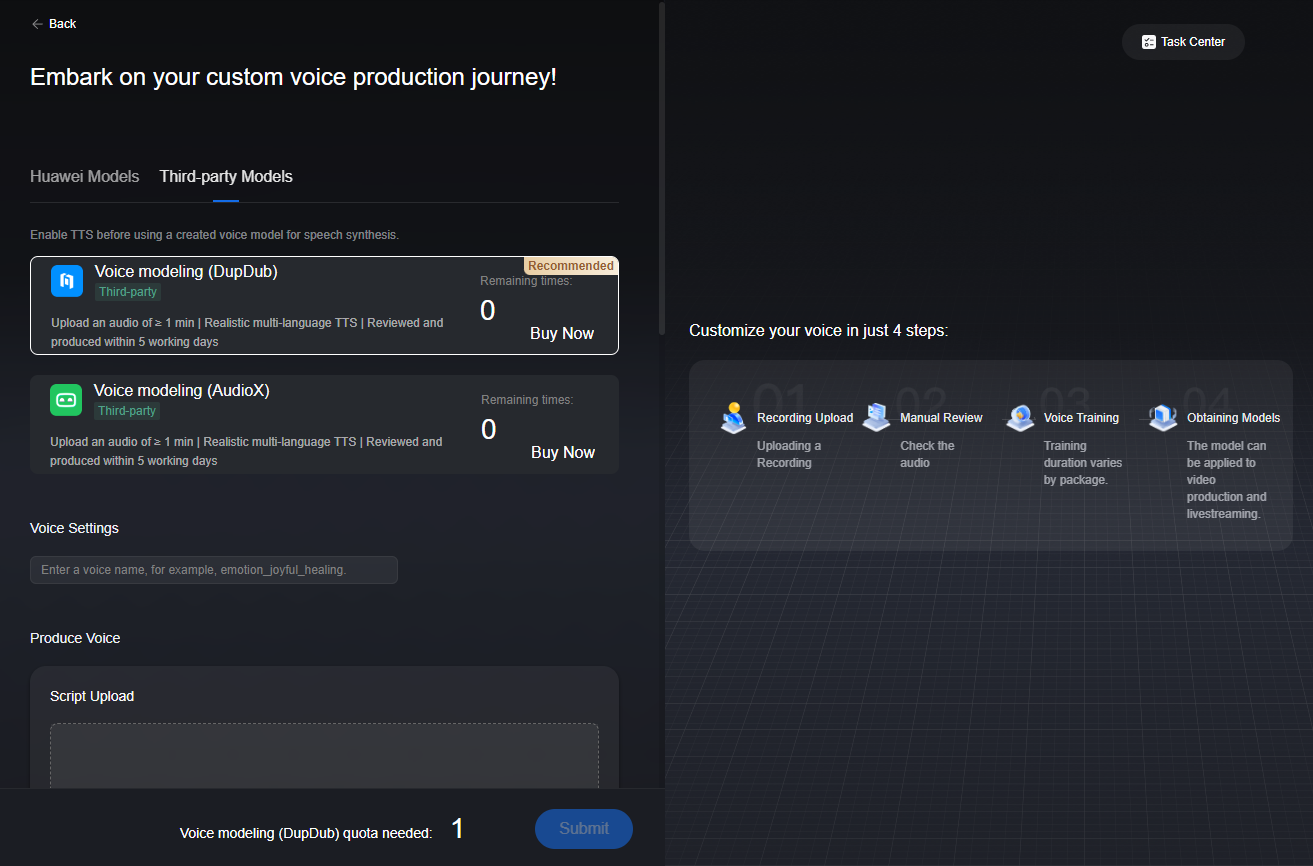
- Click the Third-party Models tab and select Voice modeling (DupDub), as shown in Figure 1.
On the page displayed, the area on the left is for voice modeling, and the area on the right shows the voice modeling process.
- Configure voice modeling parameters.
For details, see Table 1.
Table 1 GUI operations Parameter
Description
Voice modeling (DupDub)
Select Voice modeling (DupDub). Upload a WAV or MP3 audio file of 0.5–180 minutes (recommended: 5 minutes) for voice modeling in 19 languages.
If remaining quota is 0, click Buy Now to purchase a non-English/Chinese language cloning package by referring to Process of Purchasing a DupDub Non-English/Chinese Language Cloning Package.
Voice Settings
Enter a voice name.
Example: emotion_joyful_healing
Produce Voice
You can follow the audio recording guide on the page to record a one-minute WAV or MP3 audio file. WAV or MP3 audio files can be uploaded without being compressed or containing TXT files.
If no preset script is used, the voice tag is used only to indicate the voice application scenario.
Voice Gender
Gender of the voice. Specify this parameter to improve voice model precision.
Options:
- Male
- Female
Input Language
Language of the uploaded script.
Options: Chinese, English, Cantonese, German, French, Turkish, Tagalog, Japanese, Italian, Malay, Russian, Korean, Finnish, Dutch, Spanish, Indonesian, Arabic, Portuguese, and Thai.
Note: The current parameter setting is only an identifier and does not influence the training result.
Output Language
Language of the output voice model.
Options:
- An output voice model can be in Chinese, English, German, French, Turkish, Tagalog, Japanese, Italian, Malay, Russian, Korean, Finnish, Spanish, Indonesian, Arabic, Portuguese, or Dutch.
- Cantonese
Voice Field
Field to which a voice applies. You can select a field to quickly find the desired voice.
There is preset text of different styles for different fields. After voice training is completed, you can choose Assets > My Models > Voices to preview how the voice reads text in the selected field. You can also enter text to preview how the voice reads the text. For details, see the parameter setting of Text to Preview.
Script of each of the preceding tags is preset in MetaStudio, as shown in Script Examples (Advanced Edition). When using the preset script, you must select the corresponding tag.
Text to Preview
Enter the text to preview. After the voice training is complete, you can preview the text you entered.
Mobile Number (Optional)
Enter a mobile number.
- Check the box for authorizing the voice use and click Submit.
The Information dialog box appears, notifying you of the remaining voice modeling quota and indicating that one resource will be consumed this time.
- After confirming the information, click Submit.
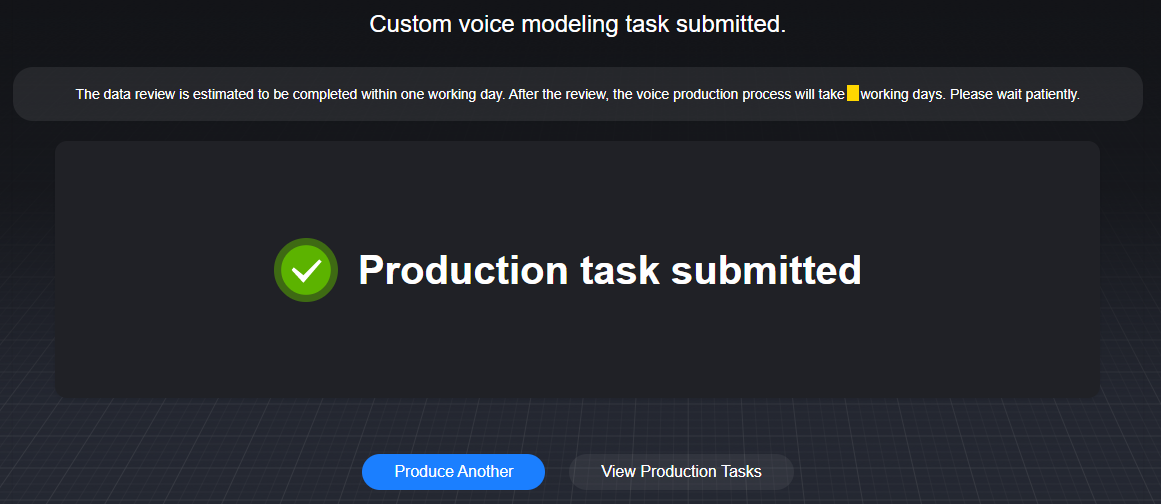
After the voice modeling task is submitted, the message Production task submitted appears, as shown in Figure 2.
- You can click View Production Tasks to view the review progress of the voice modeling task.
When the status changes to Reviewed, algorithm training is automatically started. If there are multiple algorithm training tasks, queuing and delay may occur.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



