
Suggestions on RDS for SQL Server Metric Alarm Configurations
You can set alarm rules on Cloud Eye to customize the monitored objects and notification policies and keep track of the instance status. This topic describes how to configure RDS for SQL Server metric alarm rules.
Creating a Metric Alarm Rule
- Log in to the management console.
- Click
 in the upper left corner and select a region and a project.
in the upper left corner and select a region and a project. - Click Service List. Under Management & Governance, click Cloud Eye.
- In the navigation pane on the left, choose Cloud Service Monitoring > Relational Database Service.
Figure 1 Choosing a monitored object
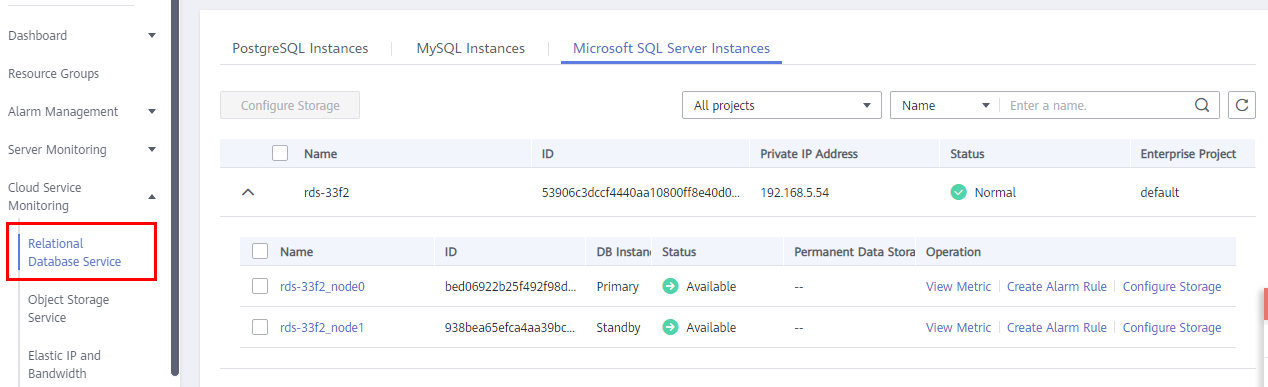
- Locate the DB instance for which you want to create an alarm rule and click Create Alarm Rule in the Operation column.
Figure 2 Creating an alarm rule
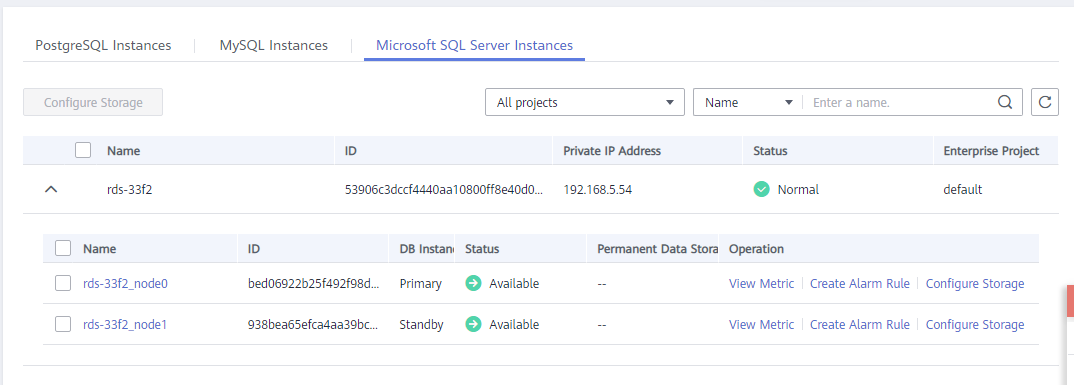
- On the displayed page, set parameters as required.
Figure 3 Configuring alarm information
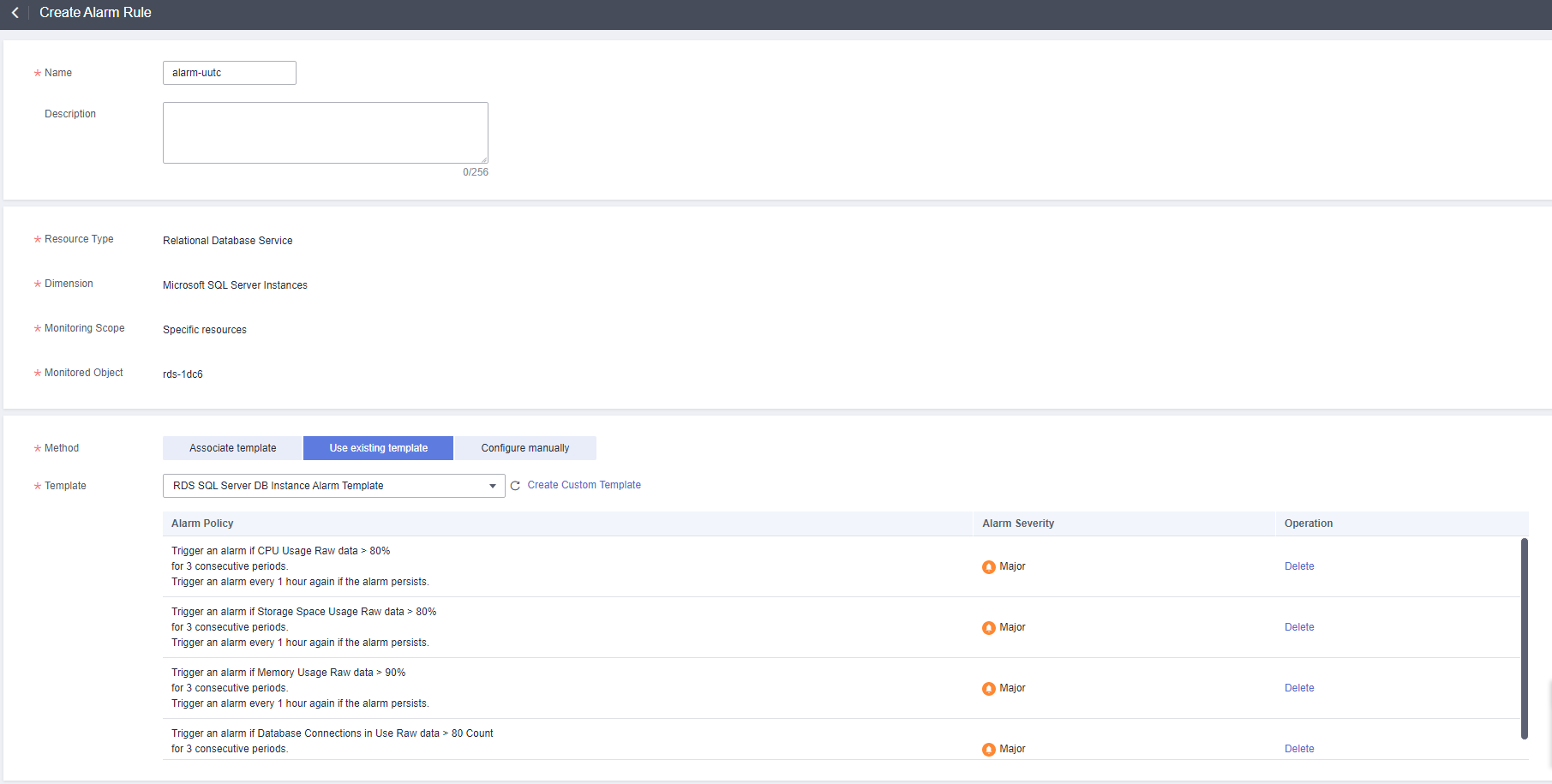
Table 1 Alarm rule information Parameter
Description
Name
Alarm rule name. The system generates a random name, which you can modify.
Description
Description about the rule.
Method
There are three options: Associate template, Use existing template, and Configure manually.
NOTE:If you select Associate template, after the associated template is modified, the policies contained in this alarm rule to be created will be modified accordingly.
You are advised to select Use existing template. The existing templates already contain four common alarm metrics: CPU usage, storage space usage, memory usage, and database connections in use.
Template
Select the template to be used.
You can select a default alarm template or create a custom template.
Alarm Policy
Policy for triggering an alarm.
Whether to trigger an alarm depends on whether the metric data in consecutive periods reaches the threshold. For example, Cloud Eye triggers an alarm if the average CPU usage of the monitored object is 80% or more for three consecutive 5-minute periods.
NOTE:A maximum of 50 alarm policies can be added to an alarm rule. If any one of these alarm policies is met, an alarm is triggered.
Alarm Severity
The alarm severity can be Critical, Major, Minor, or Informational.
Figure 4 Configuring alarm notification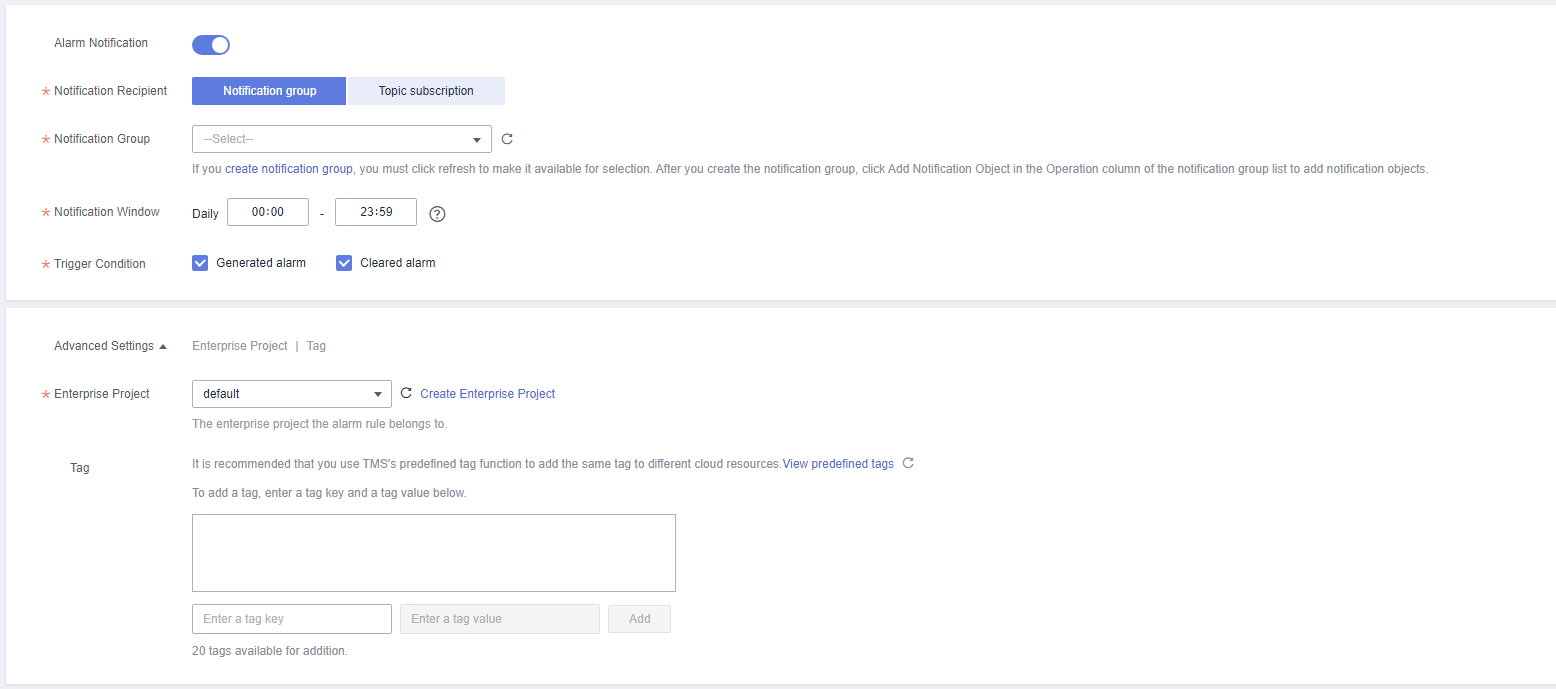
Table 2 Alarm notification Parameter
Description
Alarm Notification
Whether to notify users when alarms are triggered. Notifications can be sent by email, text message, or HTTP/HTTPS message.
Notification Recipient
You can select a notification group or topic subscription as required.
Notification Group
Notification group the alarm notification is to be sent to.
Notification Object
Object the alarm notification is to be sent to. You can select the account contact or a topic.
- The account contact is the mobile phone number and email address of the registered account.
- A topic is used to publish messages and subscribe to notifications.
Notification Window
Cloud Eye sends notifications only within the notification window specified in the alarm rule.
If Notification Window is set to 08:00-20:00, Cloud Eye sends notifications only within 08:00-20:00.
Trigger Condition
Condition for triggering an alarm notification. You can select Generated alarm (when an alarm is generated), Cleared alarm (when an alarm is cleared), or both.
Enterprise Project
Enterprise project that the alarm rule belongs to. Only users with the enterprise project permissions can view and manage the alarm rule.
Tag
A tag is a key-value pair. Tags identify cloud resources so that you can easily categorize and search for your resources.
- Click Create. The alarm rule is created.
For details about how to create alarm rules, see Creating an Alarm Rule in the Cloud Eye User Guide.
Metric Alarm Configuration Suggestions
|
Metric ID |
Name |
Metric Description |
Threshold in Best Practices |
Alarm Severity in Best Practices |
Handling Suggestion |
|---|---|---|---|---|---|
|
rds001_cpu_util |
CPU Usage |
CPU usage of the monitored object |
Raw data > 80% for three consecutive times |
Major |
|
|
rds039_disk_util |
Storage Space Usage |
Storage space usage of the monitored object |
Raw data > 80% for three consecutive times |
Major |
|
|
rds049_disk_read_throughput |
Disk Read Throughput |
Number of bytes read from the disk per second |
Ultra-high I/O or cloud SSD: Raw data > 300 MB for three consecutive times Extreme SSD: Raw data > 900 MB for three consecutive times |
Major |
If the disk read throughput is fully loaded for a long time, check whether indexes need to be rebuilt. For details, see Creating a Job for Scheduled Instance Maintenance. |
|
mssql_worker_threads_usage_rate |
Usage of Worker Threads |
Ratio of the total worker threads to the value of Max Worker Threads. |
Raw data > 90% for three consecutive periods |
Major |
If there are too many worker threads, check the instance load and upgrade the instance specifications. For details, see Changing a DB Instance Class. |
|
rds077_replication_delay |
Replication Delay |
Delay for replication between primary and standby DB instances. The replication delay of RDS for SQL Server DB instances is at the database level because data is synchronized on each database. The instance-level replication delay refers to the maximum replication delay of the databases (the delay 0s for single-node DB instances). |
Raw data ≥ 600s for three consecutive periods |
Major |
If the replay load on the standby node is heavy or the replication is abnormal, upgrade the instance specifications. For details, see Changing a DB Instance Class. |
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.See the reply and handling status in My Cloud VOC.
For any further questions, feel free to contact us through the chatbot.
Chatbot



