
- What's New
- Product Bulletin
- Function Overview
-
Service Overview
- What Is GaussDB(DWS)?
- Data Warehouse Types
- Data Warehouse Flavors
- Advantages
- Application Scenarios
- Functions
- Concepts
- Related Services
- Security
- GaussDB(DWS) Permissions Management
- GaussDB(DWS) Access
- Pricing Details
- Restrictions
- Service Quotas
- Technical Specifications
- Version Description
-
Getting Started
- Checkpoint Vehicle Analysis
- Supply Chain Requirement Analysis of a Company
- Operations Status Analysis of a Retail Department Store
- Creating a Time Series Table
- Best Practices of Hot and Cold Data Management
- Best Practices for Automatic Partition Management
- Creating a Cluster and Connecting to It
- Using CDM to Migrate MySQL Data to the GaussDB(DWS) Cluster
- Using DLI Flink Jobs to Write Kafka Data to GaussDB(DWS) in Real Time
- Basic SQL Operations
-
Database Quick Start
- Before You Start
- Creating and Managing Databases
- Planning a Storage Model
- Creating and Managing Tables
- Loading Sample Data
- Querying System Catalogs
- Creating and Managing Schemas
- Creating and Managing Partitioned Tables
- Creating and Managing Indexes
- Creating and Managing Views
- Creating and Managing Sequences
- Creating and Managing Scheduled Tasks
-
Management Guide
- Process for Using GaussDB(DWS)
- Preparations
- Creating or Deleting a Cluster
-
Cluster Connection
- Methods of Connecting to a Cluster
- Obtaining the Cluster Connection Address
- Using the Data Studio GUI Client to Connect to a Cluster
- Using the gsql CLI Client to Connect to a Cluster
- Using the JDBC and ODBC Drivers to Connect to a Cluster
- Using the Third-Party Function Library psycopg2 of Python to Connect to a Cluster
- Using the Python Library PyGreSQL to Connect to a Cluster
- Managing Database Connections
-
Monitoring and Alarms
- Dashboard
- Databases Monitoring (DMS)
- Monitoring Clusters Using Cloud Eye
-
Alarms
- Alarm Management
- Alarm Rules
- Alarm Subscriptions
-
Alarm Handling
- DWS_2000000001 Node CPU Usage Exceeds the Threshold
- DWS_2000000006 Node Data Disk Usage Exceeds the Threshold
- DWS_2000000009 Node Data Disk I/O Usage Exceeds the Threshold
- DWS_2000000012 Node Data Disk Latency Exceeds the Threshold
- DWS_2000000016 Data Spilled to Disks of the Query Statement Exceeds the Threshold
- DWS_2000000017 Number of Queuing Query Statements Exceeds the Threshold
- DWS_2000000018 Queue Congestion in the Default Cluster Resource Pool
- DWS_2000000020 Long SQL Probe Execution Duration in a Cluster
- DWS_2000000023 A Vacuum Full Operation That Holds a Lock for A Long Time Exists in the Cluster
- Event Notifications
- Specifications Change and Scaling
- Backup and Disaster Recovery
- Intelligent O&M
-
Cluster Management
- Modifying Database Parameters
- Checking the Cluster Status
- Viewing Cluster Details
- Changing a Cluster Name
- O&M Account
- Managing Access Domain Names
- Cluster Topology
- Managing Tags
- Managing Enterprise Projects
- Managing Clusters That Fail to Be Created
- Removing the Read-only Status
- Performing a Primary/Standby Switchback
- Starting and Stopping a Cluster
- Resetting a Password
- Cluster Upgrade
- Associating and Disassociating ELB
- Managing CNs
- Data Integration
- Cluster Log Management
- Database User Management
- Audit Logs
- Cluster Security Management
- Resource Management
- Data Source Management
-
Managing Logical Clusters
- Logical Cluster Overview
- Adding/Deleting a Logical Cluster
- Managing Logical Clusters
- Scheduling GaussDB(DWS) 3.0 Logical Cluster Creation and Deletion
- Tutorial: Converting a Physical Cluster That Contains Data into a Logical Cluster
- Tutorial: Dividing a New Physical Cluster into Logical Clusters
- Tutorial: Setting a Read-Only Logical Cluster and Binding It to a User
-
Best Practices
- Import and Export
-
Data Migration
- Migrating Data From Oracle to GaussDB(DWS)
- Synchronizing MySQL Table Data to GaussDB(DWS) in Real Time
- Using DLI Flink Jobs to Write Kafka Data to GaussDB(DWS) in Real Time
- Practice of Data Interconnection Between Two DWS Clusters Based on GDS
-
Table Optimization Practices
- Table Structure Design
- Table Optimization Overview
- Selecting a Table Model
- Step 1: Creating an Initial Table and Loading Sample Data
- Step 2: Testing System Performance of the Initial Table and Establishing a Baseline
- Step 3: Optimizing a Table
- Step 4: Creating Another Table and Loading Data
- Step 5: Testing System Performance in the New Table
- Step 6: Evaluating the Performance of the Optimized Table
- Appendix: Table Creation Syntax
- Advanced Features
- Database Management
- Sample Data Analysis
- Security Management
-
Data Migration and Synchronization
- Data Migration to GaussDB(DWS)
-
Importing Data
- Importing Data from OBS in Parallel
- Using GDS to Import Data from a Remote Server
- Importing Data from MRS to a Cluster
- Importing Data from One GaussDB(DWS) Cluster to Another
- GDS-based Cross-Cluster Interconnection
- Using a gsql Meta-Command to Import Data
- Running the COPY FROM STDIN Statement to Import Data
- Full Database Migration
- Metadata Migration
- Exporting Data
- Other Operations
-
Developer Guide
-
Standard Data Warehouse (9.1.0.x)
- Before You Start
-
GaussDB(DWS) Development Design Proposal
- Overview
- GaussDB(DWS) Connection Management Specifications
- GaussDB(DWS) Object Design Specifications
- GaussDB(DWS) SQL Statement Development Specifications
- GaussDB(DWS) Stored Procedure Development Specifications
- Detailed Design Rules for GaussDB(DWS) Objects
-
Creating and Managing GaussDB(DWS) Database Objects
- Creating and Managing GaussDB(DWS) Databases
- Creating and Managing GaussDB(DWS) Schemas
- Creating and Managing GaussDB(DWS) Tables
- Selecting a GaussDB(DWS) Table Storage Model
- Creating and Managing GaussDB(DWS) Partitioned Tables
- Creating and Managing GaussDB(DWS) Indexes
- Creating and Using GaussDB(DWS) Sequences
- Creating and Managing GaussDB(DWS) Views
- Creating and Managing GaussDB(DWS) Scheduled Tasks
- Viewing GaussDB(DWS) System Catalogs
- Syntax Compatibility Differences Among Oracle, Teradata, and MySQL
- GaussDB(DWS) Database Security Management
- GaussDB(DWS) Data Query
- GaussDB(DWS) Sorting Rules
- GaussDB(DWS) User-Defined Functions
-
GaussDB(DWS) Stored Procedure
- Overview
- Converting Data Types in GaussDB(DWS) Stored Procedures
- GaussDB(DWS) Stored Procedure Array and Record
- GaussDB(DWS) Stored Procedure Declaration Syntax
- Basic Statements of GaussDB(DWS) Stored Procedures
- Dynamic Statements of GaussDB(DWS) Stored Procedures
- GaussDB(DWS) Stored Procedure Control Statements
- Other Statements in a GaussDB(DWS) Stored Procedure
- GaussDB(DWS) Stored Procedure Cursor
- GaussDB(DWS) Stored Procedure Advanced Package
- GaussDB(DWS) Stored Procedure Debugging
- Using PostGIS Extension
- Using JDBC or ODBC for GaussDB(DWS) Secondary Development
- GaussDB(DWS) Resource Monitoring
-
GaussDB(DWS) Performance Tuning
- Overview
- Performance Diagnosis
- System Optimization
-
SQL Tuning
- SQL Query Execution Process
- SQL Execution Plan
- Execution Plan Operator
- SQL Tuning Process
- Updating Statistics
- Reviewing and Modifying a Table Definition
- Advanced SQL Tuning
- Configuring Optimizer Parameters
- Hint-based Tuning
- Routinely Maintaining Tables
- Routinely Recreating an Index
- Automatic Retry upon SQL Statement Execution Errors
- Query Band Load Identification
-
SQL Tuning Examples
- Case: Selecting an Appropriate Distribution Column
- Case: Creating an Appropriate Index
- Case: Adding NOT NULL for JOIN Columns
- Case: Pushing Down Sort Operations to DNs
- Case: Configuring cost_param for Better Query Performance
- Case: Adjusting the Partial Clustering Key
- Case: Adjusting the Table Storage Mode in a Medium Table
- Case: Reconstructing Partition Tables
- Case: Adjusting the GUC Parameter best_agg_plan
- Case: Rewriting SQL Statements and Eliminating Prune Interference
- Case: Rewriting SQL Statements and Deleting in-clause
- Case: Setting Partial Cluster Keys
- Case: Converting from NOT IN to NOT EXISTS
-
GaussDB(DWS) System Catalogs and Views
- Overview of System Catalogs and System Views
-
System Catalogs
- GS_BLOCKLIST_QUERY
- GS_BLOCKLIST_SQL
- GS_OBSSCANINFO
- GS_RESPOOL_RESOURCE_HISTORY
- GS_WLM_INSTANCE_HISTORY
- GS_WLM_OPERATOR_INFO
- GS_WLM_SESSION_INFO
- GS_WLM_USER_RESOURCE_HISTORY
- PG_AGGREGATE
- PG_AM
- PG_AMOP
- PG_AMPROC
- PG_ATTRDEF
- PG_ATTRIBUTE
- PG_AUTHID
- PG_AUTH_HISTORY
- PG_AUTH_MEMBERS
- PG_BLOCKLISTS
- PG_CAST
- PG_CLASS
- PG_COLLATION
- PG_CONSTRAINT
- PG_CONVERSION
- PG_DATABASE
- PG_DB_ROLE_SETTING
- PG_DEFAULT_ACL
- PG_DEPEND
- PG_DESCRIPTION
- PG_ENUM
- PG_EXCEPT_RULE
- PG_EXTENSION
- PG_EXTENSION_DATA_SOURCE
- PG_FINE_DR_INFO
- PG_FOREIGN_DATA_WRAPPER
- PG_FOREIGN_SERVER
- PG_FOREIGN_TABLE
- PG_INDEX
- PG_INHERITS
- PG_JOB_INFO
- PG_JOBS
- PG_LANGUAGE
- PG_LARGEOBJECT
- PG_LARGEOBJECT_METADATA
- PG_MATVIEW
- PG_NAMESPACE
- PG_OBJECT
- PG_OBSSCANINFO
- PG_OPCLASS
- PG_OPERATOR
- PG_OPFAMILY
- PG_PARTITION
- PG_PLTEMPLATE
- PG_PROC
- PG_PUBLICATION
- PG_PUBLICATION_NAMESPACE
- PG_PUBLICATION_REL
- PG_RANGE
- PG_REDACTION_COLUMN
- PG_REDACTION_POLICY
- PG_RELFILENODE_SIZE
- PG_RLSPOLICY
- PG_RESOURCE_POOL
- PG_REWRITE
- PG_SECLABEL
- PG_SHDEPEND
- PG_SHDESCRIPTION
- PG_SHSECLABEL
- PG_STATISTIC
- PG_STATISTIC_EXT
- PG_STAT_OBJECT
- PG_SUBSCRIPTION
- PG_SYNONYM
- PG_TABLESPACE
- PG_TRIGGER
- PG_TS_CONFIG
- PG_TS_CONFIG_MAP
- PG_TS_DICT
- PG_TS_PARSER
- PG_TS_TEMPLATE
- PG_TYPE
- PG_USER_MAPPING
- PG_USER_STATUS
- PG_WORKLOAD_ACTION
- PGXC_CLASS
- PGXC_GROUP
- PGXC_NODE
- PLAN_TABLE_DATA
- SNAPSHOT
- TABLES_SNAP_TIMESTAMP
- System Catalogs for Performance View Snapshot
-
System Views
- ALL_ALL_TABLES
- ALL_CONSTRAINTS
- ALL_CONS_COLUMNS
- ALL_COL_COMMENTS
- ALL_DEPENDENCIES
- ALL_IND_COLUMNS
- ALL_IND_EXPRESSIONS
- ALL_INDEXES
- ALL_OBJECTS
- ALL_PROCEDURES
- ALL_SEQUENCES
- ALL_SOURCE
- ALL_SYNONYMS
- ALL_TAB_COLUMNS
- ALL_TAB_COMMENTS
- ALL_TABLES
- ALL_USERS
- ALL_VIEWS
- DBA_DATA_FILES
- DBA_USERS
- DBA_COL_COMMENTS
- DBA_CONSTRAINTS
- DBA_CONS_COLUMNS
- DBA_IND_COLUMNS
- DBA_IND_EXPRESSIONS
- DBA_IND_PARTITIONS
- DBA_INDEXES
- DBA_OBJECTS
- DBA_PART_INDEXES
- DBA_PART_TABLES
- DBA_PROCEDURES
- DBA_SEQUENCES
- DBA_SOURCE
- DBA_SYNONYMS
- DBA_TAB_COLUMNS
- DBA_TAB_COMMENTS
- DBA_TAB_PARTITIONS
- DBA_TABLES
- DBA_TABLESPACES
- DBA_TRIGGERS
- DBA_VIEWS
- DUAL
- GET_ALL_TSC_INFO
- GET_TSC_INFO
- GLOBAL_COLUMN_TABLE_IO_STAT
- GLOBAL_REDO_STAT
- GLOBAL_REL_IOSTAT
- GLOBAL_ROW_TABLE_IO_STAT
- GLOBAL_STAT_DATABASE
- GLOBAL_TABLE_CHANGE_STAT
- GLOBAL_TABLE_STAT
- GLOBAL_WORKLOAD_SQL_COUNT
- GLOBAL_WORKLOAD_SQL_ELAPSE_TIME
- GLOBAL_WORKLOAD_TRANSACTION
- GS_ALL_CONTROL_GROUP_INFO
- GS_BLOCKLIST_QUERY
- GS_BLOCKLIST_SQL
- GS_CLUSTER_RESOURCE_INFO
- GS_COLUMN_TABLE_IO_STAT
- GS_OBS_READ_TRAFFIC
- GS_OBS_WRITE_TRAFFIC
- GS_INSTR_UNIQUE_SQL
- GS_NODE_STAT_RESET_TIME
- GS_OBS_LATENCY
- GS_QUERY_MONITOR
- GS_QUERY_RESOURCE_INFO
- GS_REL_IOSTAT
- GS_RESPOOL_RUNTIME_INFO
- GS_RESPOOL_RESOURCE_INFO
- GS_RESPOOL_MONITOR
- GS_ROW_TABLE_IO_STAT
- GS_SESSION_CPU_STATISTICS
- GS_SESSION_MEMORY_STATISTICS
- GS_SQL_COUNT
- GS_STAT_DB_CU
- GS_STAT_SESSION_CU
- GS_TABLE_CHANGE_STAT
- GS_TABLE_STAT
- GS_TOTAL_NODEGROUP_MEMORY_DETAIL
- GS_USER_MONITOR
- GS_USER_TRANSACTION
- GS_VIEW_DEPENDENCY
- GS_VIEW_DEPENDENCY_PATH
- GS_VIEW_INVALID
- GS_WAIT_EVENTS
- GS_WLM_OPERAROR_INFO
- GS_WLM_OPERATOR_HISTORY
- GS_WLM_OPERATOR_STATISTICS
- GS_WLM_SESSION_INFO
- GS_WLM_SESSION_HISTORY
- GS_WLM_SESSION_STATISTICS
- GS_WLM_SQL_ALLOW
- GS_WORKLOAD_SQL_COUNT
- GS_WORKLOAD_SQL_ELAPSE_TIME
- GS_WORKLOAD_TRANSACTION
- MPP_TABLES
- PG_AVAILABLE_EXTENSION_VERSIONS
- PG_AVAILABLE_EXTENSIONS
- PG_BULKLOAD_STATISTICS
- PG_COMM_CLIENT_INFO
- PG_COMM_DELAY
- PG_COMM_STATUS
- PG_COMM_RECV_STREAM
- PG_COMM_SEND_STREAM
- PG_COMM_QUERY_SPEED
- PG_CONTROL_GROUP_CONFIG
- PG_CURSORS
- PG_EXT_STATS
- PG_GET_INVALID_BACKENDS
- PG_GET_SENDERS_CATCHUP_TIME
- PG_GROUP
- PG_INDEXES
- PG_JOB
- PG_JOB_PROC
- PG_JOB_SINGLE
- PG_LIFECYCLE_DATA_DISTRIBUTE
- PG_LOCKS
- PG_LWLOCKS
- PG_NODE_ENV
- PG_OS_THREADS
- PG_POOLER_STATUS
- PG_PREPARED_STATEMENTS
- PG_PREPARED_XACTS
- PG_PUBLICATION_TABLES
- PG_QUERYBAND_ACTION
- PG_REPLICATION_SLOTS
- PG_ROLES
- PG_RULES
- PG_RUNNING_XACTS
- PG_SECLABELS
- PG_SEQUENCES
- PG_SESSION_WLMSTAT
- PG_SESSION_IOSTAT
- PG_SETTINGS
- PG_SHADOW
- PG_SHARED_MEMORY_DETAIL
- PG_STATS
- PG_STAT_ACTIVITY
- PG_STAT_ALL_INDEXES
- PG_STAT_ALL_TABLES
- PG_STAT_BAD_BLOCK
- PG_STAT_BGWRITER
- PG_STAT_DATABASE
- PG_STAT_DATABASE_CONFLICTS
- PG_STAT_GET_MEM_MBYTES_RESERVED
- PG_STAT_USER_FUNCTIONS
- PG_STAT_USER_INDEXES
- PG_STAT_USER_TABLES
- PG_STAT_REPLICATION
- PG_STAT_SYS_INDEXES
- PG_STAT_SYS_TABLES
- PG_STAT_XACT_ALL_TABLES
- PG_STAT_XACT_SYS_TABLES
- PG_STAT_XACT_USER_FUNCTIONS
- PG_STAT_XACT_USER_TABLES
- PG_STATIO_ALL_INDEXES
- PG_STATIO_ALL_SEQUENCES
- PG_STATIO_ALL_TABLES
- PG_STATIO_SYS_INDEXES
- PG_STATIO_SYS_SEQUENCES
- PG_STATIO_SYS_TABLES
- PG_STATIO_USER_INDEXES
- PG_STATIO_USER_SEQUENCES
- PG_STATIO_USER_TABLES
- PG_THREAD_WAIT_STATUS
- PG_TABLES
- PG_TDE_INFO
- PG_TIMEZONE_ABBREVS
- PG_TIMEZONE_NAMES
- PG_TOTAL_MEMORY_DETAIL
- PG_TOTAL_SCHEMA_INFO
- PG_TOTAL_USER_RESOURCE_INFO
- PG_USER
- PG_USER_MAPPINGS
- PG_VIEWS
- PG_WLM_STATISTICS
- PGXC_AIO_RESOURCE_POOL_STATS
- PGXC_BULKLOAD_PROGRESS
- PGXC_BULKLOAD_INFO
- PGXC_BULKLOAD_STATISTICS
- PGXC_COLUMN_TABLE_IO_STAT
- PGXC_COMM_CLIENT_INFO
- PGXC_COMM_DELAY
- PGXC_COMM_RECV_STREAM
- PGXC_COMM_SEND_STREAM
- PGXC_COMM_STATUS
- PGXC_COMM_QUERY_SPEED
- PGXC_DEADLOCK
- PGXC_DISK_CACHE_STATS
- PGXC_DISK_CACHE_ALL_STATS
- PGXC_DISK_CACHE_PATH_INFO
- PGXC_GET_STAT_ALL_TABLES
- PGXC_GET_STAT_ALL_PARTITIONS
- PGXC_GET_TABLE_SKEWNESS
- PGXC_GTM_SNAPSHOT_STATUS
- PGXC_INSTANCE_TIME
- PGXC_LOCKWAIT_DETAIL
- PGXC_INSTR_UNIQUE_SQL
- PGXC_LOCK_CONFLICTS
- PGXC_LWLOCKS
- PGXC_MEMORY_DEBUG_INFO
- PGXC_NODE_ENV
- PGXC_NODE_STAT_RESET_TIME
- PGXC_OBS_IO_SCHEDULER_STATS
- PGXC_OBS_IO_SCHEDULER_PERIODIC_STATS
- PGXC_OS_RUN_INFO
- PGXC_OS_THREADS
- PGXC_POOLER_STATUS
- PGXC_PREPARED_XACTS
- PGXC_REDO_STAT
- PGXC_REL_IOSTAT
- PGXC_REPLICATION_SLOTS
- PGXC_RESPOOL_RUNTIME_INFO
- PGXC_RESPOOL_RESOURCE_INFO
- PGXC_RESPOOL_RESOURCE_HISTORY
- PGXC_ROW_TABLE_IO_STAT
- PGXC_RUNNING_XACTS
- PGXC_SETTINGS
- PGXC_SESSION_WLMSTAT
- PGXC_STAT_ACTIVITY
- PGXC_STAT_BAD_BLOCK
- PGXC_STAT_BGWRITER
- PGXC_STAT_DATABASE
- PGXC_STAT_OBJECT
- PGXC_STAT_REPLICATION
- PGXC_STAT_TABLE_DIRTY
- PGXC_STAT_WAL
- PGXC_SQL_COUNT
- PGXC_TABLE_CHANGE_STAT
- PGXC_TABLE_STAT
- PGXC_THREAD_WAIT_STATUS
- PGXC_TOTAL_MEMORY_DETAIL
- PGXC_TOTAL_SCHEMA_INFO
- PGXC_TOTAL_SCHEMA_INFO_ANALYZE
- PGXC_TOTAL_USER_RESOURCE_INFO
- PGXC_USER_TRANSACTION
- PGXC_VARIABLE_INFO
- PGXC_WAIT_DETAIL
- PGXC_WAIT_EVENTS
- PGXC_WLM_OPERATOR_HISTORY
- PGXC_WLM_OPERATOR_INFO
- PGXC_WLM_OPERATOR_STATISTICS
- PGXC_WLM_SESSION_INFO
- PGXC_WLM_SESSION_HISTORY
- PGXC_WLM_SESSION_STATISTICS
- PGXC_WLM_TABLE_DISTRIBUTION_SKEWNESS
- PGXC_WLM_USER_RESOURCE_HISTORY
- PGXC_WLM_WORKLOAD_RECORDS
- PGXC_WORKLOAD_SQL_COUNT
- PGXC_WORKLOAD_SQL_ELAPSE_TIME
- PGXC_WORKLOAD_TRANSACTION
- PLAN_TABLE
- PV_FILE_STAT
- PV_INSTANCE_TIME
- PV_MATVIEW_DETAIL
- PV_OS_RUN_INFO
- PV_SESSION_MEMORY
- PV_SESSION_MEMORY_DETAIL
- PV_SESSION_STAT
- PV_SESSION_TIME
- PV_TOTAL_MEMORY_DETAIL
- PV_REDO_STAT
- PV_RUNTIME_ATTSTATS
- PV_RUNTIME_RELSTATS
- REDACTION_COLUMNS
- REDACTION_POLICIES
- REMOTE_TABLE_STAT
- SHOW_TSC_INFO
- SHOW_ALL_TSC_INFO
- USER_COL_COMMENTS
- USER_CONSTRAINTS
- USER_CONS_COLUMNS
- USER_INDEXES
- USER_IND_COLUMNS
- USER_IND_EXPRESSIONS
- USER_IND_PARTITIONS
- USER_JOBS
- USER_OBJECTS
- USER_PART_INDEXES
- USER_PART_TABLES
- USER_PROCEDURES
- USER_SEQUENCES
- USER_SOURCE
- USER_SYNONYMS
- USER_TAB_COLUMNS
- USER_TAB_COMMENTS
- USER_TAB_PARTITIONS
- USER_TABLES
- USER_TRIGGERS
- USER_VIEWS
- V$SESSION
- V$SESSION_LONGOPS
-
GUC Parameters of the GaussDB(DWS) Database
- Viewing GUC Parameters
- Configuring GUC Parameters
- GUC Parameter Usage
- Connection and Authentication
- Resource Consumption
- Parallel Data Import
- Write Ahead Logs
- HA Replication
- Query Planning
- Error Reporting and Logging
- Alarm Detection
- Statistics During the Database Running
- Resource Management
- Automatic Cleanup
- Default Settings of Client Connection
- Lock Management
- Version and Platform Compatibility
- Fault Tolerance
- Connection Pool Parameters
- Cluster Transaction Parameters
- Developer Operations
- Auditing
- Transaction Monitoring
- GTM Parameters
- Miscellaneous Parameters
- GaussDB(DWS) Developer Terms
-
Standard Data Warehouse (8.1.3.x)
- Before You Start
-
GaussDB(DWS) Development Design Specifications
- Overview
- GaussDB(DWS) Connection Management Specifications
- GaussDB(DWS) Object Design Specifications
- GaussDB(DWS) SQL Statement Development Specifications
- GaussDB(DWS) Stored Procedure Development Specifications
- Detailed Design Rules for GaussDB(DWS) Objects
-
Creating and Managing GaussDB(DWS) Database Objects
- Creating and Managing GaussDB(DWS) Databases
- Creating and Managing GaussDB(DWS) Schemas
- Selecting a GaussDB(DWS) Table Storage Model
- Creating and Managing GaussDB(DWS) Tables
- Creating and Managing GaussDB(DWS) Partitioned Tables
- Creating and Managing GaussDB(DWS) Indexes
- Creating and Using GaussDB(DWS) Sequences
- Creating and Managing GaussDB(DWS) Views
- Creating and Managing GaussDB(DWS) Scheduled Tasks
- Viewing GaussDB(DWS) System Catalogs
- Syntax Compatibility Differences Among Oracle, Teradata, and MySQL
- GaussDB(DWS) Database Security Management
- GaussDB(DWS) Data Query
- GaussDB(DWS) Sorting Rules
- GaussDB(DWS) User-Defined Functions
-
GaussDB(DWS) Stored Procedure
- Overview
- Converting Data Types in GaussDB(DWS) Stored Procedures
- GaussDB(DWS) Stored Procedure Array and Record
- GaussDB(DWS) Stored Procedure Declaration Syntax
- Basic Statements of GaussDB(DWS) Stored Procedures
- Dynamic Statements of GaussDB(DWS) Stored Procedures
- GaussDB(DWS) Stored Procedure Control Statements
- Other Statements in a GaussDB(DWS) Stored Procedure
- GaussDB(DWS) Stored Procedure Cursor
- GaussDB(DWS) Stored Procedure Advanced Package
- GaussDB(DWS) Stored Procedure Debugging
- Using PostGIS Extension
- Using JDBC or ODBC for GaussDB(DWS) Secondary Development
- GaussDB(DWS) Resource Monitoring
-
GaussDB(DWS) Performance Tuning
- Overview
- Performance Diagnosis
- System Optimization
-
SQL Tuning
- SQL Query Execution Process
- SQL Execution Plan
- Execution Plan Operator
- SQL Tuning Process
- Updating Statistics
- Reviewing and Modifying a Table Definition
- Advanced SQL Tuning
- Hint-based Tuning
- Routinely Maintaining Tables
- Routinely Recreating an Index
- Automatic Retry upon SQL Statement Execution Errors
- query_band Load Identification
-
SQL Tuning Examples
- Case: Selecting an Appropriate Distribution Column
- Case: Creating an Appropriate Index
- Case: Adding NOT NULL for JOIN Columns
- Case: Pushing Down Sort Operations to DNs
- Case: Configuring cost_param for Better Query Performance
- Case: Adjusting the Partial Clustering Key
- Case: Adjusting the Table Storage Mode in a Medium Table
- Case: Reconstructing Partition Tables
- Case: Adjusting the GUC Parameter best_agg_plan
- Case: Rewriting SQL Statements and Eliminating Prune Interference
- Case: Rewriting SQL Statements and Deleting in-clause
- Case: Setting Partial Cluster Keys
- Case: Converting from NOT IN to NOT EXISTS
-
GaussDB(DWS) System Catalogs and Views
- Overview of System Catalogs and System Views
-
System Catalogs
- GS_OBSSCANINFO
- GS_RESPOOL_RESOURCE_HISTORY
- GS_WLM_INSTANCE_HISTORY
- GS_WLM_OPERATOR_INFO
- GS_WLM_SESSION_INFO
- GS_WLM_USER_RESOURCE_HISTORY
- PG_AGGREGATE
- PG_AM
- PG_AMOP
- PG_AMPROC
- PG_ATTRDEF
- PG_ATTRIBUTE
- PG_AUTHID
- PG_AUTH_HISTORY
- PG_AUTH_MEMBERS
- PG_CAST
- PG_CLASS
- PG_COLLATION
- PG_CONSTRAINT
- PG_CONVERSION
- PG_DATABASE
- PG_DB_ROLE_SETTING
- PG_DEFAULT_ACL
- PG_DEPEND
- PG_DESCRIPTION
- PG_ENUM
- PG_EXTENSION
- PG_EXTENSION_DATA_SOURCE
- PG_FOREIGN_DATA_WRAPPER
- PG_FOREIGN_SERVER
- PG_FOREIGN_TABLE
- PG_INDEX
- PG_INHERITS
- PG_JOBS
- PG_LANGUAGE
- PG_LARGEOBJECT
- PG_LARGEOBJECT_METADATA
- PG_NAMESPACE
- PG_OBJECT
- PG_OBSSCANINFO
- PG_OPCLASS
- PG_OPERATOR
- PG_OPFAMILY
- PG_PARTITION
- PG_PLTEMPLATE
- PG_PROC
- PG_RANGE
- PG_REDACTION_COLUMN
- PG_REDACTION_POLICY
- PG_RELFILENODE_SIZE
- PG_RLSPOLICY
- PG_RESOURCE_POOL
- PG_REWRITE
- PG_SECLABEL
- PG_SHDEPEND
- PG_SHDESCRIPTION
- PG_SHSECLABEL
- PG_STATISTIC
- PG_STATISTIC_EXT
- PG_SYNONYM
- PG_TABLESPACE
- PG_TRIGGER
- PG_TS_CONFIG
- PG_TS_CONFIG_MAP
- PG_TS_DICT
- PG_TS_PARSER
- PG_TS_TEMPLATE
- PG_TYPE
- PG_USER_MAPPING
- PG_USER_STATUS
- PG_WORKLOAD_ACTION
- PGXC_CLASS
- PGXC_GROUP
- PGXC_NODE
- PLAN_TABLE_DATA
- SNAPSHOT
- TABLES_SNAP_TIMESTAMP
- System Catalogs for Performance View Snapshot
-
System Views
- ALL_ALL_TABLES
- ALL_CONSTRAINTS
- ALL_CONS_COLUMNS
- ALL_COL_COMMENTS
- ALL_DEPENDENCIES
- ALL_IND_COLUMNS
- ALL_IND_EXPRESSIONS
- ALL_INDEXES
- ALL_OBJECTS
- ALL_PROCEDURES
- ALL_SEQUENCES
- ALL_SOURCE
- ALL_SYNONYMS
- ALL_TAB_COLUMNS
- ALL_TAB_COMMENTS
- ALL_TABLES
- ALL_USERS
- ALL_VIEWS
- DBA_DATA_FILES
- DBA_USERS
- DBA_COL_COMMENTS
- DBA_CONSTRAINTS
- DBA_CONS_COLUMNS
- DBA_IND_COLUMNS
- DBA_IND_EXPRESSIONS
- DBA_IND_PARTITIONS
- DBA_INDEXES
- DBA_OBJECTS
- DBA_PART_INDEXES
- DBA_PART_TABLES
- DBA_PROCEDURES
- DBA_SEQUENCES
- DBA_SOURCE
- DBA_SYNONYMS
- DBA_TAB_COLUMNS
- DBA_TAB_COMMENTS
- DBA_TAB_PARTITIONS
- DBA_TABLES
- DBA_TABLESPACES
- DBA_TRIGGERS
- DBA_VIEWS
- DUAL
- GLOBAL_COLUMN_TABLE_IO_STAT
- GLOBAL_REDO_STAT
- GLOBAL_REL_IOSTAT
- GLOBAL_ROW_TABLE_IO_STAT
- GLOBAL_STAT_DATABASE
- GLOBAL_TABLE_CHANGE_STAT
- GLOBAL_TABLE_STAT
- GLOBAL_WORKLOAD_SQL_COUNT
- GLOBAL_WORKLOAD_SQL_ELAPSE_TIME
- GLOBAL_WORKLOAD_TRANSACTION
- GS_ALL_CONTROL_GROUP_INFO
- GS_CLUSTER_RESOURCE_INFO
- GS_COLUMN_TABLE_IO_STAT
- GS_INSTR_UNIQUE_SQL
- GS_NODE_STAT_RESET_TIME
- GS_REL_IOSTAT
- GS_RESPOOL_RUNTIME_INFO
- GS_RESPOOL_RESOURCE_INFO
- GS_ROW_TABLE_IO_STAT
- GS_SESSION_CPU_STATISTICS
- GS_SESSION_MEMORY_STATISTICS
- GS_SQL_COUNT
- GS_STAT_DB_CU
- GS_STAT_SESSION_CU
- GS_TABLE_CHANGE_STAT
- GS_TABLE_STAT
- GS_TOTAL_NODEGROUP_MEMORY_DETAIL
- GS_USER_TRANSACTION
- GS_VIEW_DEPENDENCY
- GS_VIEW_DEPENDENCY_PATH
- GS_VIEW_INVALID
- GS_WAIT_EVENTS
- GS_WLM_OPERAROR_INFO
- GS_WLM_OPERATOR_HISTORY
- GS_WLM_OPERATOR_STATISTICS
- GS_WLM_SESSION_INFO
- GS_WLM_SESSION_HISTORY
- GS_WLM_SESSION_STATISTICS
- GS_WLM_SQL_ALLOW
- GS_WORKLOAD_SQL_COUNT
- GS_WORKLOAD_SQL_ELAPSE_TIME
- GS_WORKLOAD_TRANSACTION
- MPP_TABLES
- PG_AVAILABLE_EXTENSION_VERSIONS
- PG_AVAILABLE_EXTENSIONS
- PG_BULKLOAD_STATISTICS
- PG_COMM_CLIENT_INFO
- PG_COMM_DELAY
- PG_COMM_STATUS
- PG_COMM_RECV_STREAM
- PG_COMM_SEND_STREAM
- PG_COMM_QUERY_SPEED
- PG_CONTROL_GROUP_CONFIG
- PG_CURSORS
- PG_EXT_STATS
- PG_GET_INVALID_BACKENDS
- PG_GET_SENDERS_CATCHUP_TIME
- PG_GROUP
- PG_INDEXES
- PG_JOB
- PG_JOB_PROC
- PG_JOB_SINGLE
- PG_LIFECYCLE_DATA_DISTRIBUTE
- PG_LOCKS
- PG_NODE_ENV
- PG_OS_THREADS
- PG_POOLER_STATUS
- PG_PREPARED_STATEMENTS
- PG_PREPARED_XACTS
- PG_QUERYBAND_ACTION
- PG_REPLICATION_SLOTS
- PG_ROLES
- PG_RULES
- PG_RUNNING_XACTS
- PG_SECLABELS
- PG_SESSION_WLMSTAT
- PG_SESSION_IOSTAT
- PG_SETTINGS
- PG_SHADOW
- PG_SHARED_MEMORY_DETAIL
- PG_STATS
- PG_STAT_ACTIVITY
- PG_STAT_ALL_INDEXES
- PG_STAT_ALL_TABLES
- PG_STAT_BAD_BLOCK
- PG_STAT_BGWRITER
- PG_STAT_DATABASE
- PG_STAT_DATABASE_CONFLICTS
- PG_STAT_GET_MEM_MBYTES_RESERVED
- PG_STAT_USER_FUNCTIONS
- PG_STAT_USER_INDEXES
- PG_STAT_USER_TABLES
- PG_STAT_REPLICATION
- PG_STAT_SYS_INDEXES
- PG_STAT_SYS_TABLES
- PG_STAT_XACT_ALL_TABLES
- PG_STAT_XACT_SYS_TABLES
- PG_STAT_XACT_USER_FUNCTIONS
- PG_STAT_XACT_USER_TABLES
- PG_STATIO_ALL_INDEXES
- PG_STATIO_ALL_SEQUENCES
- PG_STATIO_ALL_TABLES
- PG_STATIO_SYS_INDEXES
- PG_STATIO_SYS_SEQUENCES
- PG_STATIO_SYS_TABLES
- PG_STATIO_USER_INDEXES
- PG_STATIO_USER_SEQUENCES
- PG_STATIO_USER_TABLES
- PG_THREAD_WAIT_STATUS
- PG_TABLES
- PG_TDE_INFO
- PG_TIMEZONE_ABBREVS
- PG_TIMEZONE_NAMES
- PG_TOTAL_MEMORY_DETAIL
- PG_TOTAL_SCHEMA_INFO
- PG_TOTAL_USER_RESOURCE_INFO
- PG_USER
- PG_USER_MAPPINGS
- PG_VIEWS
- PG_WLM_STATISTICS
- PGXC_BULKLOAD_PROGRESS
- PGXC_BULKLOAD_STATISTICS
- PGXC_COLUMN_TABLE_IO_STAT
- PGXC_COMM_CLIENT_INFO
- PGXC_COMM_DELAY
- PGXC_COMM_RECV_STREAM
- PGXC_COMM_SEND_STREAM
- PGXC_COMM_STATUS
- PGXC_COMM_QUERY_SPEED
- PGXC_DEADLOCK
- PGXC_GET_STAT_ALL_TABLES
- PGXC_GET_STAT_ALL_PARTITIONS
- PGXC_GET_TABLE_SKEWNESS
- PGXC_GTM_SNAPSHOT_STATUS
- PGXC_INSTANCE_TIME
- PGXC_LOCKWAIT_DETAIL
- PGXC_INSTR_UNIQUE_SQL
- PGXC_LOCK_CONFLICTS
- PGXC_NODE_ENV
- PGXC_NODE_STAT_RESET_TIME
- PGXC_OS_RUN_INFO
- PGXC_OS_THREADS
- PGXC_PREPARED_XACTS
- PGXC_REDO_STAT
- PGXC_REL_IOSTAT
- PGXC_REPLICATION_SLOTS
- PGXC_RESPOOL_RUNTIME_INFO
- PGXC_RESPOOL_RESOURCE_INFO
- PGXC_RESPOOL_RESOURCE_HISTORY
- PGXC_ROW_TABLE_IO_STAT
- PGXC_RUNNING_XACTS
- PGXC_SETTINGS
- PGXC_SESSION_WLMSTAT
- PGXC_STAT_ACTIVITY
- PGXC_STAT_BAD_BLOCK
- PGXC_STAT_BGWRITER
- PGXC_STAT_DATABASE
- PGXC_STAT_REPLICATION
- PGXC_STAT_TABLE_DIRTY
- PGXC_SQL_COUNT
- PGXC_TABLE_CHANGE_STAT
- PGXC_TABLE_STAT
- PGXC_THREAD_WAIT_STATUS
- PGXC_TOTAL_MEMORY_DETAIL
- PGXC_TOTAL_SCHEMA_INFO
- PGXC_TOTAL_SCHEMA_INFO_ANALYZE
- PGXC_USER_TRANSACTION
- PGXC_VARIABLE_INFO
- PGXC_WAIT_DETAIL
- PGXC_WAIT_EVENTS
- PGXC_WLM_OPERATOR_HISTORY
- PGXC_WLM_OPERATOR_INFO
- PGXC_WLM_OPERATOR_STATISTICS
- PGXC_WLM_SESSION_INFO
- PGXC_WLM_SESSION_HISTORY
- PGXC_WLM_SESSION_STATISTICS
- PGXC_WLM_WORKLOAD_RECORDS
- PGXC_WORKLOAD_SQL_COUNT
- PGXC_WORKLOAD_SQL_ELAPSE_TIME
- PGXC_WORKLOAD_TRANSACTION
- PLAN_TABLE
- PV_FILE_STAT
- PV_INSTANCE_TIME
- PV_OS_RUN_INFO
- PV_SESSION_MEMORY
- PV_SESSION_MEMORY_DETAIL
- PV_SESSION_STAT
- PV_SESSION_TIME
- PV_TOTAL_MEMORY_DETAIL
- PV_REDO_STAT
- REDACTION_COLUMNS
- REDACTION_POLICIES
- REMOTE_TABLE_STAT
- USER_COL_COMMENTS
- USER_CONSTRAINTS
- USER_CONS_COLUMNS
- USER_INDEXES
- USER_IND_COLUMNS
- USER_IND_EXPRESSIONS
- USER_IND_PARTITIONS
- USER_JOBS
- USER_OBJECTS
- USER_PART_INDEXES
- USER_PART_TABLES
- USER_PROCEDURES
- USER_SEQUENCES
- USER_SOURCE
- USER_SYNONYMS
- USER_TAB_COLUMNS
- USER_TAB_COMMENTS
- USER_TAB_PARTITIONS
- USER_TABLES
- USER_TRIGGERS
- USER_VIEWS
- V$SESSION
- V$SESSION_LONGOPS
-
GUC Parameters of the GaussDB(DWS) Database
- Viewing GUC Parameters
- Configuring GUC Parameters
- GUC Parameter Usage
- Connection and Authentication
- Resource Consumption
- Parallel Data Import
- Write Ahead Logs
- HA Replication
- Query Planning
- Error Reporting and Logging
- Alarm Detection
- Statistics During the Database Running
- Resource Management
- Automatic Cleanup
- Default Settings of Client Connection
- Lock Management
- Version and Platform Compatibility
- Fault Tolerance
- Connection Pool Parameters
- Cluster Transaction Parameters
- Developer Operations
- Auditing
- Transaction Monitoring
- GTM Parameters
- Miscellaneous Parameters
- GaussDB(DWS) Developer Terms
-
Standard Data Warehouse (9.1.0.x)
-
SQL Syntax Reference
-
SQL Syntax Reference (9.1.0.x)
- GaussDB(DWS) SQL Overview
- Differences Between GaussDB(DWS) and PostgreSQL
- Keyword
-
Data Types
- Numeric Types
- Monetary Types
- Boolean Type
- Character Types
- Binary Data Types
- Date/Time Types
- Geometric Types
- Array
- Enumeration Type
- Network Address Types
- Bit String Types
- Text Search Types
- UUID Type
- JSON Types
- RoaringBitmap
- HLL Data Types
- Object Identifier Types
- Pseudo-Types
- Range Types
- Composite Types
- Data Types Supported by Column-Store Tables
- XML
- Constant and Macro
-
Functions and Operators
- Character Processing Functions and Operators
- Binary String Functions and Operators
- Bit String Functions and Operators
- Numeric Functions and Operators
- Date and Time Processing Functions and Operators
- SEQUENCE Functions
- Array Functions and Operators
- Logical Operators
- Comparison Operators
- Pattern Matching Operators
- Aggregate Functions
- Window Functions
- Type Conversion Functions
- JSON/JSONB Functions and Operators
- Security Functions
- Conditional Expression Functions
- Range Functions and Operators
- Data Redaction Functions
- Bitmap Functions and Operators
- UUID Functions
- Text Search Functions and Operators
- HLL Functions and Operators
- Set Returning Functions
- Geometric Functions and Operators
- Network Address Functions and Operators
- System Information Functions
- System Administration Functions
- Backup and Restoration Control Functions
- Database Object Functions
- Residual File Management Functions
- Statistics Information Functions
- Trigger Functions
- XML Functions
- Call Stack Recording Functions
- Hudi System Functions
- Funnel and Retention Functions
- EXTERNAL SCHEMA System Functions
- Storage-Compute Decoupling Functions
- Expressions
- Type Conversion
- Full Text Search
- System Operation
- Transaction Management
-
DDL Syntax
- DDL Syntax Overview
- ALTER BLOCK RULE
- ALTER DATABASE
- ALTER EXCEPT RULE
- ALTER FOREIGN TABLE (GDS Import and Export)
- ALTER FOREIGN TABLE (for HDFS or OBS)
- ALTER FOREIGN TABLE (SQL on other GaussDB(DWS))
- ALTER FUNCTION
- ALTER GROUP
- ALTER INDEX
- ALTER LARGE OBJECT
- ALTER MATERIALIZED VIEW
- ALTER PUBLICATION
- ALTER REDACTION POLICY
- ALTER RESOURCE POOL
- ALTER ROLE
- ALTER SUBSCRIPTION
- ALTER ROW LEVEL SECURITY POLICY
- ALTER SCHEMA
- ALTER SEQUENCE
- ALTER SERVER
- ALTER SESSION
- ALTER SYNONYM
- ALTER SYSTEM KILL SESSION
- ALTER TABLE
- ALTER TABLE PARTITION
- ALTER TEXT SEARCH CONFIGURATION
- ALTER TEXT SEARCH DICTIONARY
- ALTER TRIGGER
- ALTER TYPE
- ALTER USER
- ALTER VIEW
- CLEAN CONNECTION
- CLOSE
- CLUSTER
- COMMENT
- CREATE BARRIER
- CREATE BLOCK RULE
- CREATE DATABASE
- CREATE EXCEPT RULE
- CREATE FOREIGN TABLE (for GDS Import and Export)
- CREATE FOREIGN TABLE (SQL on OBS or Hadoop)
- CREATE FOREIGN TABLE (for OBS Import and Export)
- CREATE FOREIGN TABLE (SQL on other GaussDB(DWS))
- CREATE FUNCTION
- CREATE GROUP
- CREATE INDEX
- CREATE MATERIALIZED VIEW
- CREATE PROCEDURE
- CREATE PUBLICATION
- CREATE REDACTION POLICY
- CREATE ROW LEVEL SECURITY POLICY
- CREATE RESOURCE POOL
- CREATE ROLE
- CREATE SCHEMA
- CREATE SEQUENCE
- CREATE SERVER
- CREATE SUBSCRIPTION
- CREATE SYNONYM
- CREATE TABLE
- CREATE TABLE AS
- CREATE TABLE PARTITION
- CREATE TEXT SEARCH CONFIGURATION
- CREATE TEXT SEARCH DICTIONARY
- CREATE TRIGGER
- CREATE TYPE
- CREATE USER
- CREATE VIEW
- CURSOR
- DISCARD
- DROP BLOCK RULE
- DROP DATABASE
- DROP EXCEPT RULE
- DROP FOREIGN TABLE
- DROP FUNCTION
- DROP GROUP
- DROP INDEX
- DROP MATERIALIZED VIEW
- DROP OWNED
- DROP PUBLICATION
- DROP REDACTION POLICY
- DROP ROW LEVEL SECURITY POLICY
- DROP PROCEDURE
- DROP RESOURCE POOL
- DROP ROLE
- DROP SCHEMA
- DROP SEQUENCE
- DROP SERVER
- DROP SUBSCRIPTION
- DROP SYNONYM
- DROP TABLE
- DROP TEXT SEARCH CONFIGURATION
- DROP TEXT SEARCH DICTIONARY
- DROP TRIGGER
- DROP TYPE
- DROP USER
- DROP VIEW
- FETCH
- MOVE
- REFRESH MATERIALIZED VIEW
- REINDEX
- RENAME TABLE
- RESET
- SET
- SET CONSTRAINTS
- SET ROLE
- SET SESSION AUTHORIZATION
- SHOW
- TRUNCATE
- VACUUM
- DML Syntax
- DCL Syntax
- DQL Syntax
- TCL Syntax
-
SQL Syntax Reference (8.1.3.x)
- GaussDB(DWS) SQL Overview
- Differences Between GaussDB(DWS) and PostgreSQL
- Keyword
-
Data Types
- Numeric Types
- Monetary Types
- Boolean Type
- Character Types
- Binary Data Types
- Date/Time Types
- Geometric Types
- Array
- Enumeration Type
- Network Address Types
- Bit String Types
- Text Search Types
- UUID Type
- JSON Types
- RoaringBitmap
- HLL Data Types
- Object Identifier Types
- Pseudo-Types
- Range Types
- Composite Types
- Data Types Supported by Column-Store Tables
- XML
- Constant and Macro
-
Functions and Operators
- Character Processing Functions and Operators
- Binary String Functions and Operators
- Bit String Functions and Operators
- Mathematical Functions and Operators
- Date and Time Processing Functions and Operators
- SEQUENCE Functions
- Array Functions and Operators
- Logical Operators
- Comparison Operators
- Pattern Matching Operators
- Aggregate Functions
- Window Functions
- Type Conversion Functions
- JSON/JSONB Functions and Operators
- Security Functions
- Conditional Expression Functions
- Range Functions and Operators
- Data Masking Functions
- Roaring Bitmap Functions and Operators
- UUID Functions
- Text Search Functions and Operators
- HLL Functions and Operators
- Set Returning Functions
- Geometric Functions and Operators
- Network Address Functions and Operators
- System Information Functions
- System Administration Functions
- Database Object Functions
- Residual File Management Functions
- Statistics Information Functions
- Trigger Functions
- XML Functions
- Call Stack Recording Functions
- Expressions
- Type Conversion
- Full Text Search
- System Operation
- Transaction Management
-
DDL Syntax
- DDL Syntax Overview
- ALTER DATABASE
- ALTER FOREIGN TABLE (GDS Import and Export)
- ALTER FOREIGN TABLE (for HDFS or OBS)
- ALTER FOREIGN TABLE (SQL on other GaussDB(DWS))
- ALTER FUNCTION
- ALTER GROUP
- ALTER INDEX
- ALTER LARGE OBJECT
- ALTER REDACTION POLICY
- ALTER RESOURCE POOL
- ALTER ROLE
- ALTER ROW LEVEL SECURITY POLICY
- ALTER SCHEMA
- ALTER SEQUENCE
- ALTER SERVER
- ALTER SESSION
- ALTER SYNONYM
- ALTER SYSTEM KILL SESSION
- ALTER TABLE
- ALTER TABLE PARTITION
- ALTER TEXT SEARCH CONFIGURATION
- ALTER TEXT SEARCH DICTIONARY
- ALTER TRIGGER
- ALTER TYPE
- ALTER USER
- ALTER VIEW
- CLEAN CONNECTION
- CLOSE
- CLUSTER
- COMMENT
- CREATE BARRIER
- CREATE DATABASE
- CREATE FOREIGN TABLE (for GDS Import and Export)
- CREATE FOREIGN TABLE (SQL on OBS or Hadoop)
- CREATE FOREIGN TABLE (for OBS Import and Export)
- CREATE FOREIGN TABLE (SQL on other GaussDB(DWS))
- CREATE FUNCTION
- CREATE GROUP
- CREATE INDEX
- CREATE REDACTION POLICY
- CREATE ROW LEVEL SECURITY POLICY
- CREATE PROCEDURE
- CREATE RESOURCE POOL
- CREATE ROLE
- CREATE SCHEMA
- CREATE SEQUENCE
- CREATE SERVER
- CREATE SYNONYM
- CREATE TABLE
- CREATE TABLE AS
- CREATE TABLE PARTITION
- CREATE TEXT SEARCH CONFIGURATION
- CREATE TEXT SEARCH DICTIONARY
- CREATE TRIGGER
- CREATE TYPE
- CREATE USER
- CREATE VIEW
- CURSOR
- DROP DATABASE
- DROP FOREIGN TABLE
- DROP FUNCTION
- DROP GROUP
- DROP INDEX
- DROP OWNED
- DROP REDACTION POLICY
- DROP ROW LEVEL SECURITY POLICY
- DROP PROCEDURE
- DROP RESOURCE POOL
- DROP ROLE
- DROP SCHEMA
- DROP SEQUENCE
- DROP SERVER
- DROP SYNONYM
- DROP TABLE
- DROP TEXT SEARCH CONFIGURATION
- DROP TEXT SEARCH DICTIONARY
- DROP TRIGGER
- DROP TYPE
- DROP USER
- DROP VIEW
- FETCH
- MOVE
- REINDEX
- RENAME TABLE
- RESET
- SET
- SET CONSTRAINTS
- SET ROLE
- SET SESSION AUTHORIZATION
- SHOW
- TRUNCATE
- VACUUM
- DML Syntax
- DCL Syntax
- DQL Syntax
- TCL Syntax
-
SQL Syntax Reference (9.1.0.x)
-
Performance Tuning
- Overview of Query Performance Optimization
- Query Analysis
- Query Improvement
-
Optimization Cases
- Case: Selecting an Appropriate Distribution Column
- Case: Creating an Appropriate Index
- Case: Adding NOT NULL for JOIN Columns
- Case: Pushing Down Sort Operations to DNs
- Case: Configuring cost_param for Better Query Performance
- Case: Adjusting the Distribution Key
- Case: Adjusting the Partial Clustering Key
- Case: Adjusting the Table Storage Mode in a Medium Table
- Case: Adjusting the Local Clustering Column
- Case: Reconstructing Partition Tables
- Case: Adjusting the GUC Parameter best_agg_plan
- Case: Rewriting SQL and Deleting Subqueries (Case 1)
- Case: Rewriting SQL and Deleting Subqueries (Case 2)
- Case: Rewriting SQL Statements and Eliminating Prune Interference
- Case: Rewriting SQL Statements and Deleting in-clause
- Case: Setting Partial Cluster Keys
- SQL Execution Troubleshooting
- query_band Load Identification
-
Tool Guide
- Overview
- Downloading Client Tools
- gsql - CLI Client
-
Data Studio - Integrated Database Development Tool
- About Data Studio
- Installing and Configuring Data Studio
- Quick Start
- Data Studio GUI
- Data Studio Menus
- Data Studio Toolbar
- Data Studio Right-Click Menus
- Connection Profiles
- Databases
- Schemas
- Creating a Function/Procedure
- Editing a Function/Procedure
- Granting/Revoking a Permission (Function/Procedure)
- Debugging a PL/SQL Function
- Working with Functions/Procedures
- GaussDB(DWS) Tables
- Sequences
- Views
- Users/Roles
-
SQL Terminal
- Opening Multiple SQL Terminal Tabs
- Managing the SQL Query Execution History
- Opening and Saving SQL Scripts
- Viewing Object Properties in the SQL Terminal
- Canceling the Execution of SQL Queries
- Formatting of SQL Queries
- Selecting a DB Object in the SQL Terminal
- Viewing the Query Execution Plan and Cost
- Viewing the Query Execution Plan and Cost Graphically
- Working with SQL Terminals
- Exporting Query Results
- Managing SQL Terminal Connections
- Batch Operation
- Personalizing Data Studio
- Performance Specifications
- Security Management
- Troubleshooting
- FAQs
- GDS: Parallel Data Loader
-
DSC: SQL Syntax Migration Tool
- Overview
- Supported Keywords and Features
- Constraints and Limitations
- System Requirements
- Installing DSC
- Configuring DSC
- Using DSC
- Teradata Syntax Migration
-
Oracle Syntax Migration
- Overview
- Schema Objects
- COMPRESS Phrase
- Bitmap Index
- Custom Tablespace
- Supplemental Log Data
- LONG RAW
- SYS_GUID
- DML
- Pseudo Columns
- OUTER JOIN
- OUTER QUERY (+)
- CONNECT BY
- System Functions
- PL/SQL
- PL/SQL Collections (Using User-Defined Types)
- PL/SQL Packages
- VARRAY
- Granting Execution Permissions
- Package Name List
- Data Type
- Chinese Character Support
- Netezza Syntax Migration
- MySQL Syntax Migration
- DB2 Syntax Migration
- Command Reference
- Log Reference
- Troubleshooting
- FAQs
- Security Management
- DWS-Connector
- Server Tool
- API Reference
-
FAQs
-
General Problems
- Why Are Data Warehouses Necessary?
- What Are the Differences Between a Data Warehouse and the Hadoop Big Data Platform?
- Why Should I Use Public Cloud GaussDB(DWS)?
- Should I Choose Public Cloud GaussDB(DWS) or RDS?
- When Should I Use GaussDB(DWS) and MRS?
- What Is the User Quota?
- What Are the Differences Between Users and Roles?
- How Do I Check the Creation Time of a Database User?
- Regions and AZs
- Is My Data Secure in GaussDB(DWS)?
- How Is GaussDB(DWS) Secured?
- Can I Modify the Security Group of a GaussDB(DWS) Cluster?
- How Are LibrA, GaussDB A, and GaussDB(DWS) Related?
- What Is a Database/Data Warehouse/Data Lake/Lakehouse?
-
Cluster Management
- What Do I Do If Creating a GaussDB(DWS) Cluster Failed?
- How Can I Clear and Reclaim the Storage Space?
- Can I Switch My Cluster Nodes to Another Region After Purchase?
- Why Did the Used Storage Shrink After Scale-out?
- How Do I View Node Metrics (CPU, Memory, and Disk Usage)?
- Does GaussDB(DWS) Support BMS?
- How Is the Disk Space or Capacity of GaussDB(DWS) Calculated?
- What Are the gaussdb and postgres Databases of GaussDB(DWS)?
- How Do I Set the Maximum Number of Sessions When Adding an Alarm Rule on Cloud Eye?
- What Should I Do If the Scale-out Check Fails?
- When Should I Add CNs or Scale out a cluster?
- What Are the Scenarios of Resizing a Cluster, Changing the Node Flavor, Scale-out, and Scale-in?
- How Should I Select from a Small-Flavor Many-Node Cluster and a Large-Flavor Three-Node Cluster with Same CPU Cores and Memory?
- What Are the Differences Between Cloud SSDs and Local SSDs?
- What Are the Differences Between Hot Data Storage and Cold Data Storage?
-
Database Connections
- How Applications Communicate with GaussDB(DWS)?
- Does GaussDB(DWS) Support Third-Party Clients and JDBC and ODBC Drivers?
- Can I Connect to GaussDB(DWS) Cluster Nodes Using SSH?
- What Should I Do If I Cannot Connect to a Data Warehouse Cluster?
- Why Was I Not Notified of Failure Unbinding the EIP When GaussDB(DWS) Is Connected Over the Internet?
- How Do I Configure a Whitelist to Protect Clusters Available Through a Public IP Address?
-
Data Import and Export
- What Are the Differences Between Data Formats Supported by OBS and GDS Foreign Tables?
- How Do I Import Incremental Data Using an OBS Foreign Table?
- How Can I Import Data to GaussDB(DWS)?
- How Much Service Data Can a Data Warehouse Store?
- How Do I Use \Copy to Import and Export Data?
- How Do I Implement Fault Tolerance Import Between Different Encoding Libraries
- Can I Import and Export Data to and from OBS Across Regions?
- How Do I Import GaussDB(DWS)/Oracle/MySQL/SQL Server Data to GaussDB(DWS) (Whole Database Migration)?
- Can I Import Data over the Public/External Network Using GDS?
- Which Are the Factors That Affect GaussDB(DWS) Import Performance?
-
Account, Password, and Permissions
- How Does GaussDB(DWS) Implement Workload Isolation?
- How Do I Change the Password of a Database Account When the Password Expires?
- How Do I Grant Table Permissions to a User?
- How Do I Grant Schema Permissions to a User?
- How Do I Create a Database Read-only User?
- How Do I Create Private Database Users and Tables?
- How Do I Revoke the CONNECT ON DATABASE Permission from a User?
- How Do I View the Table Permissions of a User?
- Who Is User Ruby?
-
Database Usage
- How Do I Change Distribution Columns?
- How Do I View and Set the Database Character Encoding?
- What Do I Do If Date Type Is Automatically Converted to the Timestamp Type During Table Creation?
- Do I Need to Run VACUUM FULL and ANALYZE on Common Tables Periodically?
- Do I Need to Set a Distribution Key After Setting a Primary Key?
- Is GaussDB(DWS) Compatible with PostgreSQL Stored Procedures?
- What Are Partitioned Tables, Partitions, and Partition Keys?
- How Can I Export the Table Structure?
- How Can I Delete Table Data Efficiently?
- How Do I View Foreign Table Information?
- If No Distribution Column Is Specified, How Will Data Be Stored?
- How Do I Replace the Null Result with 0?
- How Do I Check Whether a Table Is Row-Stored or Column-Stored?
- How Do I Query the Information About GaussDB(DWS) Column-Store Tables?
- Why Sometimes the GaussDB(DWS) Query Indexes Become Invalid?
- How Do I Use a User-Defined Function to Rewrite the CRC32() Function?
- What Are the Schemas Starting with pg_toast_temp* or pg_temp*?
- Solutions to Inconsistent GaussDB(DWS) Query Results
- Which System Catalogs That the VACUUM FULL Operation Cannot Be Performed on?
- In Which Scenarios Would a Statement Be "idle in transaction"?
- How Does GaussDB(DWS) Implement Row-to-Column and Column-to-Row Conversion?
- What Are the Differences Between Unique Constraints and Unique Indexes?
-
Database Performance
- Why Is SQL Execution Slow After Long GaussDB(DWS) Usage?
- Why Does GaussDB(DWS) Perform Worse Than a Single-Server Database in Extreme Scenarios?
- How Can I View SQL Execution Records in a Certain Period When Read and Write Requests Are Blocked?
- What Do I Do If My Cluster Is Unavailable Because of Insufficient Space?
- What is Operator Spilling in GaussDB(DWS)?
- GaussDB(DWS) CPU Resource Management
- Why the Tasks Executed by an Ordinary User Are Slower Than That Executed by the dbadmin User?
- What Are the Factors Related to the Single-Table Query Performance in GaussDB(DWS)?
- Snapshot Backup and Restoration
-
Billing
- How Do I Renew the Service?
- Is Refund Supported?
- How Am I Billed for Scheduled Synchronization of GaussDB(DWS) Data to a PostgreSQL Database?
- How Can I Try Out GaussDB(DWS) for Free?
- Why Was I Deducted Fees After My GaussDB(DWS) Free Trial Expired?
- Why Can't I See a Cluster After I Subscribe to a Free GaussDB(DWS) Trial?
- How Can I Stop GaussDB(DWS) Billing?
- Does Pay-per-Use Billing Stop When My Cluster Stops?
- Why Is the Purchase Button Unavailable When I Create a Cluster?
- How Do I Unfreeze a Cluster?
- Can I Freeze or Shut Down a GaussDB(DWS) Cluster to Stop Billing?
-
General Problems
-
Troubleshooting
-
Database Connections
- What Do I Do If gsql: command not found Is Displayed When I Run gsql to Connect to the Database?
- Database Cannot Be Connected Using the gsql Client
- An Error Indicating Too Many Client Connections Is Reported When a User Connects to a GaussDB(DWS) Database
- Cluster IP Address Cannot Be Pinged/Accessed
- Error "An I/O error occurred while sending to the backend" Is Reported During Service Execution
- JDBC/ODBC
-
Data Import and Export
- "ERROR: invalid byte sequence for encoding 'UTF8': 0x00" Is Reported When Data Is Imported to GaussDB(DWS) Using COPY FROM
- Data Import and Export Faults with GDS
- Failed to Create a GDS Foreign Table and An Error Is Reported Indicating that ROUNDROBIN Is Not Supported
- When CDM Is Used to Import MySQL Data to GaussDB(DWS), the Column Length Exceeds the Threshold and Data Synchronization Fails
- "Access Denied" Is Displayed When the SQL Statement for Creating an OBS Foreign Table Is Executed
- Disk Usage Increases After Data Fails to Be Imported Using GDS
- Error Message "out of memory" Is Displayed When GDS Is Used to Import Data
- Error Message "connection failure error" Is Displayed During GDS Data Transmission
- Data to Be Imported Contains Chinese When the DataArts Studio Service Is Used to Create a GaussDB(DWS) Foreign Table
- Database Parameter Modification
-
Account/Permission/Password
- How Do I Unlock an Account?
- Account Still Locked After Password Resetting
- After the Permission for Querying Tables in a Schema Is Granted to a User, the User Still Cannot Query the Tables
- How Do I Revoke the Permission of a User If grant select on table t1 to public Has Been Executed on a Table
- An Error Message Is Displayed When a Common User Executes the Statement for Creating or Deleting a GDS or OBS Foreign Table, Indicating that the User Does Not Have the Permission or the Permission Is Insufficient
- After the all Permission Is Granted to the Schema of a User, the Error Message "ERROR: current user does not have privilege to role tom" Persists During Table Creation
- An Error Message Is Reported During Statement Execution, Indicating that the User Does Not Have the Required Permission
- Failed to Run the create extension Command and An Error Indicating No Permission Is Reported
- A User Cannot Be Deleted Due to Its Dependencies
-
Cluster Performance
- Lock Wait Detection
- During SQL Execution, a Table Deadlock Occurs and An Error Stating LOCK_WAIT_TIMEOUT Is Reported
- Error "abort transaction due to concurrent update" Is Reported During SQL Execution
- Solution to High Disk Usage and Cluster Read-Only
- SQL Execution Is Slow with Low Performance and Sometimes Does Not End After a Long Period of Time
- Data Skew Causes Slow SQL Statement Execution and Operations Fail on Large Tables
- Table Size Does not Change After VACUUM FULL Is Executed on the Table
- VACUUM Is Executed After Table Data Deletion, But the Space Is Not Released
- Error LOCK_WAIT_TIMEOUT Is Reported When VACUUM FULL Is Executed
- VACUUM FULL Is Slow
- Table Bloating Causes Slow SQL Query and Failed Data Loading on the GUI
- Memory Overflow Occurs in a Cluster
- Statements with User-defined Functions Cannot Be Pushed Down
- Column-Store Tables Cannot Be Updated or Table Bloat Occurs
- Table Bloat Occurs After Data Is Inserted into a Column-Store Table for Multiple Times
- Writing Data to GaussDB(DWS) Is Slow and Client Data Is Stacked
- Low Query Efficiency
- Poor Query Performance Due to the Lack of Statistics
- Execution of SQL Statements with NOT IN and NOT EXISTS Is Slow Due to Nested Loops in Execution Plans
- SQL Query Is Slow Because Partitions Are Not Pruned
- Optimizer Uses Nested Loop Due to the Small Estimated Number of Rows and the Performance Deteriorates
- SQL Statements Contain the in Constant and No Result Is Returned After SQL Statement Execution
- Performance of Single-Table Point Query Is Poor
- CCN Queuing Under Dynamic Load Management
- Performance Deterioration Due to Data Bloat
- Slow Performance Caused by Too Many Small CUs in Column Storage
- Cluster Exceptions
-
Database Use
- An Error Is Reported When Data Is Inserted or Updated, Indicating that the Distribution Key Cannot Be Updated
- "Connection reset by peer" Is Displayed When a User Executes an SQL Statement
- "value too long for type character varying" Is Displayed When VARCHAR(n) Stores Chinese Characters
- Case Sensitivity in SQL Statements
- cannot drop table test because other objects depend on it Is Displayed When a Table Is Deleted
- Failed to Execute MERGE INTO UPDATE for Multiple Tables
- JDBC Error Occurs Due to session_timeout Settings
- DROP TABLE Fails to Be Executed
- Execution Results of the string_agg Function Are Inconsistent
- Error "could not open relation with OID xxxx" Is Reported During Table Size Query
- DROP TABLE IF EXISTS Syntax Errors
- Different Data Is Displayed for the Same Table Queried By Multiple Users
- When a User Specifies Only an Index Name to Modify the Index, A Message Indicating That the Index Does Not Exist Is Displayed
- An Error Is Reported During SQL Statement Execution, Indicating that the Schema Exists
- Failed to Delete a Database and an Error Is Reported Indicating that a Session Is Connected to the Database
- Byte Type Is Returned After a Table Column of the Character Type Is Read in Java
- "ERROR:start value of partition 'XX' NOT EQUAL up-boundary of last partition." Is Displayed When Operations Related to Table Partitions Are Performed
- Reindexing Fails
- A View Failed to Be Queried
- Global SQL Query
- How Do I Check Whether a Table Has Been Updated or Deleted?
- "Can't fit xid into page" Is Reported
- "unable to get a stable set of rows in the source table" Is Reported
- DWS Metadata Inconsistency - Abnormal Partition Index
- An Error Is Reported When the truncate Command Is Executed on the System Table pg_catalog.gs_wlm_session_info
- "inserted partition key does not map to any table partition" Is Reported When Data Is Inserted into a Partitioned Table
- Error upper boundary of adding partition MUST overtop last existing partition Is Reported When a New Partition Is Added to a Range Partitioned Table
- Error Reported During Table Query: "missing chunk number %d for toast value %u in pg_toast_XXXX"
- When Inserting Data Into a Table, An Error Is Reported: "duplicate key value violates unique constraint "%s""
- Error could not determine which collation to use for string hashing Reported During Service Execution
- When the ODBC Driver of GaussDB(DWS) Is Used, Content of Fields of the Character Type in the SQL Query Result Is Truncated
- Execution Plan Scan Hints Do Not Take Effect
- Error "invalid input syntax for xxx" Is Reported During Data Type Conversion
- Error UNION types %s and %s cannot be matched Is Reported
- "ERROR: Non-deterministic UPDATE" Is Reported During Update
- Error Reported During Data Insertion: null value in column ' %s' violates not-null constraint
- Error "unable to get a stable set of rows in the source table"
- Query Results Are Inconsistent in Oracle, Teradata, and MySQL Compatibility Modes
-
Database Connections
- Videos
-
Error Code Reference
- Management Console Error Code
-
Data Warehouse Service Error Codes
- Description of SQL Error Codes
- Third-Party Library Error Codes
- GAUSS-00001 -- GAUSS-00100
- GAUSS-00101 -- GAUSS-00200
- GAUSS-00201 -- GAUSS-00300
- GAUSS-00301 -- GAUSS-00400
- GAUSS-00401 -- GAUSS-00500
- GAUSS-00501 -- GAUSS-00600
- GAUSS-00601 -- GAUSS-00700
- GAUSS-00701 -- GAUSS-00800
- GAUSS-00801 -- GAUSS-00900
- GAUSS-00901 -- GAUSS-01000
- GAUSS-01001 -- GAUSS-01100
- GAUSS-01101 -- GAUSS-01200
- GAUSS-01201 -- GAUSS-01300
- GAUSS-01301 -- GAUSS-01400
- GAUSS-01401 -- GAUSS-01500
- GAUSS-01501 -- GAUSS-01600
- GAUSS-01601 -- GAUSS-01700
- GAUSS-01701 -- GAUSS-01800
- GAUSS-01801 -- GAUSS-01900
- GAUSS-01901 -- GAUSS-02000
- GAUSS-02001 -- GAUSS-02100
- GAUSS-02101 -- GAUSS-02200
- GAUSS-02201 -- GAUSS-02300
- GAUSS-02301 -- GAUSS-02400
- GAUSS-02401 -- GAUSS-02500
- GAUSS-02501 -- GAUSS-02600
- GAUSS-02601 -- GAUSS-02700
- GAUSS-02701 -- GAUSS-02800
- GAUSS-02801 -- GAUSS-02900
- GAUSS-02901 -- GAUSS-03000
- GAUSS-03001 -- GAUSS-03100
- GAUSS-03101 -- GAUSS-03200
- GAUSS-03201 -- GAUSS-03300
- GAUSS-03301 -- GAUSS-03400
- GAUSS-03401 -- GAUSS-03500
- GAUSS-03501 -- GAUSS-03600
- GAUSS-03601 -- GAUSS-03700
- GAUSS-03701 -- GAUSS-03800
- GAUSS-03801 -- GAUSS-03900
- GAUSS-03901 -- GAUSS-04000
- GAUSS-04001 -- GAUSS-04100
- GAUSS-04101 -- GAUSS-04200
- GAUSS-04201 -- GAUSS-04300
- GAUSS-04301 -- GAUSS-04400
- GAUSS-04401 -- GAUSS-04500
- GAUSS-04501 -- GAUSS-04600
- GAUSS-04601 -- GAUSS-04700
- GAUSS-04701 -- GAUSS-04800
- GAUSS-04901 -- GAUSS-04999
- GAUSS-05101 -- GAUSS-05200
- GAUSS-05201 -- GAUSS-05800
- GAUSS-05801 -- GAUSS-05900
- GAUSS-05901 -- GAUSS-05999
- GAUSS-06101 -- GAUSS-06200
- GAUSS-50000 -- GAUSS-50999
- GAUSS-51000 -- GAUSS-51999
- GAUSS-52000 -- GAUSS-52999
- GAUSS-53000 -- GAUSS-53999
- OE000
-
Technical White Paper
- GaussDB(DWS)
- Platforms and Technical Specifications Supported by GaussDB(DWS)
-
GaussDB(DWS) Core Technologies
- Shared-Nothing Architecture
- Data Distribution in a Distributed System
- Fully Parallel Query
- Vectorized Executor and Hybrid Row-Column Storage Engine
- Resource Monitoring and Management
- Distributed Transactions
- Online Scale-Out
- SQL on Anywhere
- Cluster Management and HA
- SQL Self-Diagnosis
- Transparent Data Encryption
- Data Masking
- Data Backup and Disaster Recovery
- GaussDB(DWS) Tools
- External APIs
Show all
Plan Hint Cases
This section takes the statements in TPC-DS (Q24) as an example to describe how to optimize an execution plan by using hints in 1000X+24DN environments. For example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
select avg(netpaid) from (select c_last_name ,c_first_name ,s_store_name ,ca_state ,s_state ,i_color ,i_current_price ,i_manager_id ,i_units ,i_size ,sum(ss_sales_price) netpaid from store_sales ,store_returns ,store ,item ,customer ,customer_address where ss_ticket_number = sr_ticket_number and ss_item_sk = sr_item_sk and ss_customer_sk = c_customer_sk and ss_item_sk = i_item_sk and ss_store_sk = s_store_sk and c_birth_country = upper(ca_country) and s_zip = ca_zip and s_market_id=7 group by c_last_name ,c_first_name ,s_store_name ,ca_state ,s_state ,i_color ,i_current_price ,i_manager_id ,i_units ,i_size); |
- The original plan of this statement is as follows and the statement execution takes 110s:

In this plan, the performance of the layer-10 broadcast is poor because the estimation result generated at layer 11 is 2140 rows, which is much less than the actual number of rows. The inaccurate estimation is mainly caused by the underestimated number of rows in layer-13 hash join. In this layer, store_sales and store_returns are joined (based on the ss_ticket_number and ss_item_sk columns in store_sales and the sr_ticket_number and sr_item_sk columns in store_returns) but the multi-column correlation is not considered.
2. After the rows hint is used for optimization, the plan is as follows and the statement execution takes 318s:
1 2 |
select avg(netpaid) from (select /*+rows(store_sales store_returns * 11270)*/ c_last_name ... |

The execution takes a longer time because layer-9 redistribute is slow. Considering that data skew does not occur at layer-9 redistribute, the slow redistribution is caused by the slow layer-8 hashjoin due to data skew at layer-18 redistribute.
3. Data skew occurs at layer-18 redistribute because customer_address has a few different values in its two join keys. Therefore, plan customer_address as the last one to be joined. After the hint is used for optimization, the plan is as follows and the statement execution takes 116s:
1 2 3 4 |
select avg(netpaid) from (select /*+rows(store_sales store_returns *11270) leading((store_sales store_returns store item customer) customer_address)*/ c_last_name ... |

Most of the time is spent on layer-6 redistribute. The plan needs to be further optimized.
4. Most of the time is spent on layer-6 redistribute because of data skew. To avoid the data skew, plan the item table as the last one to be joined because the number of rows is not reduced after item is joined. After the hint is used for optimization, the plan is as follows and the statement execution takes 120s:
1 2 3 4 |
select avg(netpaid) from (select /*+rows(store_sales store_returns *11270) leading((customer_address (store_sales store_returns store customer) item)) c_last_name ... |

Data skew occurs after the join of item and customer_address because item is broadcasted at layer-22. As a result, layer-6 redistribute is still slow.
5. Add a hint to disable broadcast for item or add a redistribute hint for the join result of item and customer_address. After the hint is used for optimization, the plan is as follows and the statement execution takes 105s:
1 2 3 4 5 |
select avg(netpaid) from (select /*+rows(store_sales store_returns *11270) leading((customer_address (store_sales store_returns store customer) item)) no broadcast(item)*/ c_last_name ... |
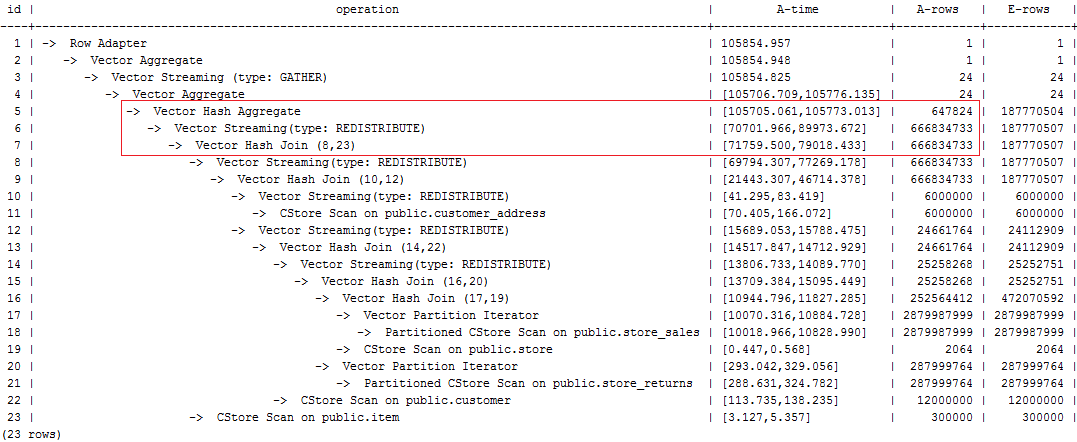
6. The last layer uses single-layer Agg and the number of rows is greatly reduced. Set best_agg_plan to 3 and change the single-layer Agg to a double-layer Agg. The plan is as follows and the statement execution takes 94s. The optimization ends.

If the query performance deteriorates due to statistics changes, you can use hints to optimize the query plan. Take TPCH-Q17 as an example. The query performance deteriorates after the value of default_statistics_target is changed from the default one to –2 for statistics collection.
1. If default_statistics_target is set to the default value 100, the plan is as follows:

2. If default_statistics_target is set to –2, the plan is as follows:

3. After the analysis, the cause is that the stream type is changed from BroadCast to Redistribute during the join of the lineitem and part tables. You can use a hint to change the stream type back to BroadCast. For example:

Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.




