
Cutting Costs by Switching Between Cold and Hot Data Storage in DWS
Scenarios
In massive big data scenarios, with the growing of data, data storage and consumption increase rapidly. The need for data may vary in different time periods, therefore, data is managed in a hierarchical manner, improving data analysis performance and reducing service costs. In some data usage scenarios, data can be classified into hot data and cold data by accessing frequency.
Hot and cold data is classified based on the data access frequency and update frequency.
- Hot data: Data that is frequently accessed and updated and requires fast response.
- Cold data: Data that cannot be updated or is seldom accessed and does not require fast response
You can define cold and hot management tables to switch cold data that meets the specified rules to OBS for storage. Cold and hot data can be automatically determined and migrated by partition.

When data is written to DWS column-store tables, the data is first stored in hot partitions. If there is a large amount of data in the partitions, the data that meets the cold data rules can be manually or automatically migrated to OBS for storage. The metadata, description tables, and indexes of the migrated cold data are stored locally to ensure the read performance.
The hot and cold partitions can be switched based on LMT (Last Modify Time) and HPN (Hot Partition Number) policies. LMT indicates that the switchover is performed based on the last update time of the partition, and HPN indicates that the switchover is performed based on the number of reserved hot partitions.
- LMT: Switch the hot partition data that is not updated in the last [day] days to the OBS tablespace as cold partition data. [day] is an integer ranging from 0 to 36500, in days.
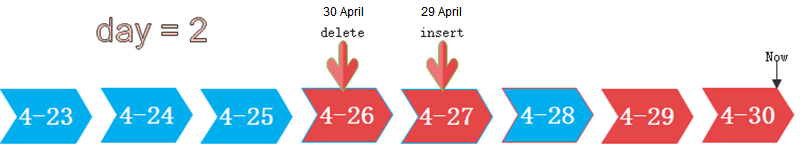
In the following figure, day is set to 2, indicating that the partitions modified in the last two days are retained as the hot partitions, while the rest is retained as the cold partitions. Assume that the current time is April 30. The delete operation is performed on the partition [4-26] on April 30, and the insert operation is performed on the partition [4-27] on April 29. Therefore, partitions [4-26][4-27][4-29][4-30] are retained as hot partitions.
- HPN: indicates the number of hot partitions to be reserved. The partitions are sequenced based on partition sequence IDs. The sequence ID of a partition is a built-in sequence number generated based on the partition boundary values and is not shown. For a range partition, a larger boundary value indicates a larger sequence ID. For a list partition, a larger maximum enumerated value of the partition boundary indicates a larger sequence ID. During the cold and hot switchover, data needs to be migrated to OBS. HPN is an integer ranging from 0 to 1600. If HPN is set to 0, hot partitions are not reserved. During a cold/hot switchover, all partitions with data are converted to cold partitions and stored on OBS.
In the following figure, HPN is set to 3, indicating that the last three partitions with data are retained as the hot partitions with the rest as the cold partitions during hot and cold partition switchover.

Constraints
- Supports DML operations on cold and hot tables, such as INSERT, COPY, DELETE, UPDATE, and SELECT.
- Supports DCL operations such as permission management on cold and hot tables.
- Supports ANALYZE, VACUUM, and MERGE INTO operations on cold and hot tables.
- Supports common column-store partitioned tables to be upgraded to hot and cold data tables.
- Supports upgrade, scale-out, scale-in, and redistribution operations on tables with cold and hot data management enabled.
- 8.3.0 and later versions support mutual conversion between cold and hot partitions. Versions earlier than 8.3.0 support only conversion from hot data to cold data.
- If a table has both cold and hot partitions, the query becomes slow because cold data is stored on OBS and the read/write speed are lower than those of local queries.
- Currently, cold and hot tables support only column-store partitioned tables of version 2.0. Foreign tables do not support cold and hot partitions.
- Only the cold and hot switchover policies can be modified. The tablespace of cold data in cold and hot tables cannot be modified.
- Restrictions on partitioning cold and hot tables:
- Data in cold partitions cannot be exchanged.
- MERGE PARTITION supports only the merge of hot-hot partitions and cold-cold partitions.
- Partition operations, such as ADD, MERGE, and SPLIT, cannot be performed on an OBS tablespace.
- Tablespaces of cold and hot table partitions cannot be specified or modified during table creation.
- Cold and hot data switchover is not performed immediately upon conditions are met. Data switchover is performed only after users manually, or through a scheduler, invoke the switchover command. Currently, the automatic scheduling time is 00:00 every day and can be modified.
- Cold and hot data tables do not support physical fine-grained backup and restoration. Only hot data is backed up during physical backup. Cold data on OBS does not change. The backup and restoration does not support file deletion statements, such as TRUNCATE TABLE and DROP TABLE.
Procedure
This practice takes about 30 minutes. The basic process is as follows:
Creating a cluster
- Create a cluster on the DWS console. For details, see Creating a DWS Storage-Compute Coupled Cluster.
Using the gsql CLI Client to Connect to a Cluster
- Remotely log in to the Linux server where gsql is to be installed as user root, and run the following command in the Linux command window to download the gsql client:
1wget https://obs.eu-west-101.myhuaweicloud.com/dws/download/dws_client_8.1.x_redhat_x64.zip --no-check-certificate
- Decompress the client.
1cd <Path_for_storing_the_client> unzip dws_client_8.1.x_redhat_x64.zip
Where,
- <Path_for_storing_the_client>: Replace it with the actual path.
- dws_client_8.1.x_redhat_x64.zip: This is the client tool package name of RedHat x64. Replace it with the actual name.
- Configure the DWS client.
1source gsql_env.sh
If the following information is displayed, the gsql client is successfully configured:
1All things done.
- Use the gsql client to connect to a DWS database (using the password you defined when creating the cluster).
1gsql -d gaussdb -p 8000 -h 192.168.0.86 -U dbadmin -W password -r
If the following information is displayed, the connection succeeded:
1gaussdb=>
Creating Hot and Cold Tables
1 2 3 4 5 6 7 8 9 | CREATE TABLE lifecycle_table(i int, val text) WITH (ORIENTATION = COLUMN, storage_policy = 'LMT:100') PARTITION BY RANGE (i) ( PARTITION P1 VALUES LESS THAN(5), PARTITION P2 VALUES LESS THAN(10), PARTITION P3 VALUES LESS THAN(15), PARTITION P8 VALUES LESS THAN(MAXVALUE) ) ENABLE ROW MOVEMENT; |
Hot and Cold Data Switchover
- Automatic switchover: The scheduler automatically triggers the switchover at 00:00 every day.
You can use the pg_obs_cold_refresh_time(table_name, time) function to customize the automatic switchover time. For example, set the automatic triggering time to 06:30 every morning.
1 2 3 4 5
SELECT * FROM pg_obs_cold_refresh_time('lifecycle_table', '06:30:00'); pg_obs_cold_refresh_time -------------------------- SUCCESS (1 row)
- Manual
Run the ALTER TABLE statement to manually switch a single table.
1 2
ALTER TABLE lifecycle_table refresh storage; ALTER TABLE
Use the pg_refresh_storage() function to switch all hot and cold tables in batches.
1 2 3 4 5
SELECT pg_catalog.pg_refresh_storage(); pg_refresh_storage -------------------- (1,0) (1 row)
Convert cold partition data into hot partition data. This function is supported only in 8.3.0 or later.
- Convert all cold partitions to hot partitions.
1SELECT pg_catalog.reload_cold_partition('lifecycle_table');
- Convert a specified cold partition to a hot partition:
1SELECT pg_catalog.reload_cold_partition('lifecycle_table', 'cold_partition_name');
Viewing Data Distribution in Hot and Cold Tables
- View the data distribution in a single table:
1 2 3 4 5 6 7
SELECT * FROM pg_catalog.pg_lifecycle_table_data_distribute('lifecycle_table'); schemaname | tablename | nodename | hotpartition | coldpartition | switchablepartition | hotdatasize | colddatasize | switchabledatasize ------------+-----------------+--------------+--------------+---------------+---------------------+-------------+--------------+-------------------- public | lifecycle_table | dn_6001_6002 | p1,p2,p3,p8 | | | 96 KB | 0 bytes | 0 bytes public | lifecycle_table | dn_6003_6004 | p1,p2,p3,p8 | | | 96 KB | 0 bytes | 0 bytes public | lifecycle_table | dn_6005_6006 | p1,p2,p3,p8 | | | 96 KB | 0 bytes | 0 bytes (3 rows)
- View data distribution in all hot and cold tables:
1 2 3 4 5 6 7
SELECT * FROM pg_catalog.pg_lifecycle_node_data_distribute(); schemaname | tablename | nodename | hotpartition | coldpartition | switchablepartition | hotdatasize | colddatasize | switchabledatasize ------------+-----------------+--------------+--------------+---------------+---------------------+-------------+--------------+-------------------- public | lifecycle_table | dn_6001_6002 | p1,p2,p3,p8 | | | 98304 | 0 | 0 public | lifecycle_table | dn_6003_6004 | p1,p2,p3,p8 | | | 98304 | 0 | 0 public | lifecycle_table | dn_6005_6006 | p1,p2,p3,p8 | | | 98304 | 0 | 0 (3 rows)
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.




