
Before Optimization: Learning Table Structure Design
In this practice, you will learn how to optimize the design of your tables. You will start by creating tables without specifying their storage mode, distribution key, distribution mode, or compression mode. Load test data into these tables and test system performance. Then, follow excellent practices to create the tables again using new storage modes, distribution keys, distribution modes, and compression modes. Load the test data and test performance again. Compare the two test results to find out how table design affects the storage space, and the loading and query performance of the tables.
Before you optimize a table, you need to understand the structure of the table. During database design, some key factors about table design will greatly affect the subsequent query performance of the database. Table design affects data storage as well. Scientific table design reduces I/O operations and minimizes memory usage, improving the query performance.
This section describes how to optimize table performance in DWS by properly designing the table structure (for example, by selecting the table model, table storage mode, compression level, distribution mode, distribution column, partitioned tables, and local clustering).
Selecting a Table Model
The most common types of data warehouse table models are star and snowflake models. Consider service and performance requirements when you choose a model for your tables.
- In the star model, a central fact table contains the core data for the database and several dimension tables provide descriptive attribute information for the fact table. The primary key of a dimension table associates a foreign key in a fact table, as shown in Figure 1.
- All facts must have the same granularity.
- Different dimensions are not associated.
- The snowflake model is developed based on the star model. In this model, each dimension can be associated with multiple dimensions and split into tables of different granularities based on the dimension level, as shown in Figure 2.
- Dimension tables can be associated as needed, and the data stored in them is reduced.
- This model has more dimension tables to maintain than the star schema does.
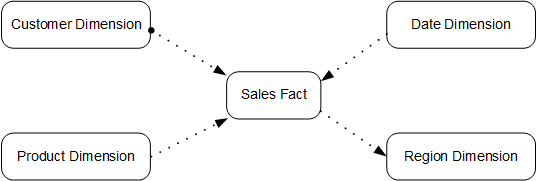
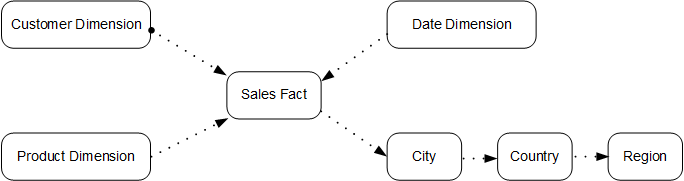
This practice verifies performance using the Store Sales (SS) model of TPC-DS. The model uses the snowflake model. Figure 3 illustrates its structure.
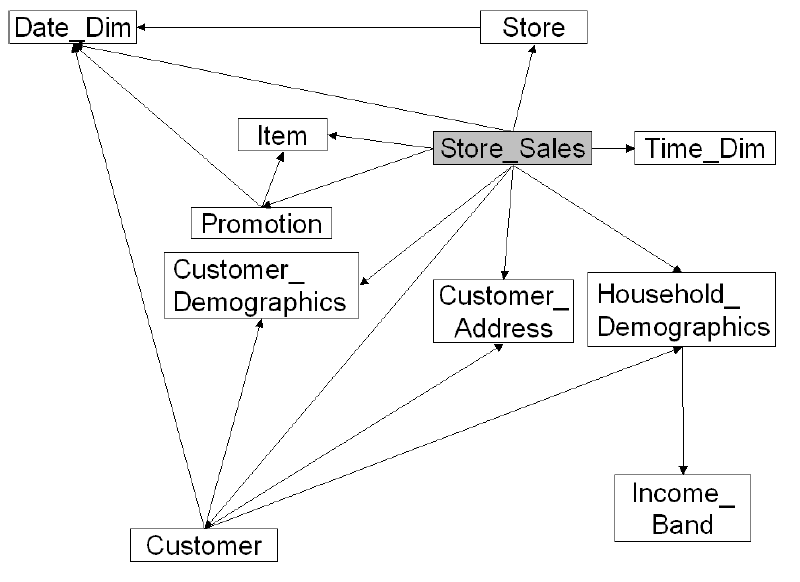
For details about the store_sales fact table and dimension tables in the model, see the official document of TPC-DS at http://www.tpc.org/tpc_documents_current_versions/current_specifications5.asp.
Selecting a Storage Mode
Selecting a model for table storage is the first step of table definition. Select a proper storage model for your service based on the table below.
Generally, if a table contains many columns (called a wide table) and its query involves only a few columns, column storage is recommended. If a table contains only a few columns and a query involves most of the columns, row storage is recommended.
| Storage Model | Application Scenario |
|---|---|
| Row storage | Point query (simple index–based query that returns only a few records). Query involving many INSERT, UPDATE, and DELETE operations. |
| Column storage | Statistical analysis queries. Queries with many groups and joins. |
The row/column storage of a table is specified by the orientation attribute in the table definition. The value row indicates a row-store table and column indicates a column-store table. The default value is row.
Table Compression
Table compression can be enabled when a table is created. Table compression enables data in the table to be stored in compressed format to reduce memory usage.
In scenarios where I/O is large (much data is read and written) and CPU is sufficient (little data is computed), select a high compression ratio. In scenarios where I/O is small and CPU is insufficient, select a low compression ratio. Based on this principle, you are advised to select different compression ratios and test and compare the results to select the optimal compression ratio as required. Specify a compressions ratio using the COMPRESSION parameter. The supported values are as follows:
- The valid value of column-store tables is YES, NO, LOW, MIDDLE, or HIGH, and the default value is LOW.
- The valid values of row-store tables are YES and NO, and the default is NO. (The row-store table compression function is not put into commercial use. To use this function, contact technical support.)
The service scenarios applicable to each compression level are described in the following table.
| Compression Level | Application Scenario |
|---|---|
| LOW | The system CPU usage is high and the disk storage space is sufficient. |
| MIDDLE | The system CPU usage is moderate and the disk storage space is insufficient. |
| HIGH | The system CPU usage is low and the disk storage space is insufficient. |
Selecting a Distribution Mode
DWS supports the following distribution modes: replication, hash, and Round-robin.
Round-robin is supported in cluster 8.1.2 and later.
| Policy | Description | Application Scenario | Advantages/disadvantages |
|---|---|---|---|
| Replication | Full data in a table is stored on each DN in the cluster. | Small tables and dimension tables |
|
| Hash | Table data is distributed on all DNs in the cluster. | Fact tables containing a large amount of data |
|
| Polling (Round-robin) | Each row in the table is sent to each DN in turn. Data can be evenly distributed on each DN. | Fact tables that contain a large amount of data and cannot find a proper distribution key in hash mode |
|
Selecting a Distribution Key
If the hash distribution mode is used, a distribution key must be specified for the user table. If a record is inserted, the system performs hash computing based on values in the distribute column and then stores data on the related DN.
Select a hash distribution key based on the following principles:
- The values of the distribution key should be discrete so that data can be evenly distributed on each DN. You can select the primary key of the table as the distribution key. For example, for a person information table, choose the ID number column as the distribution key.
- Do not select the column where a constant filter exists. For example, if a constant constraint (for example, zqdh= '000001') exists on the zqdh column in some queries on the dwcjk table, you are not advised to use zqdh as the distribution key.
- With the above principles met, you can select join conditions as distribution keys, so that join tasks can be pushed down to DNs for execution, reducing the amount of data transferred between the DNs.
For a hash table, an improper distribution key may cause data skew or poor I/O performance on certain DNs. Therefore, you need to check the table to ensure that data is evenly distributed on each DN. You can run the following SQL statements to check for data skew:
1 2 3 4 5
SELECT xc_node_id, count(1) FROM tablename GROUP BY xc_node_id ORDER BY xc_node_id desc;
xc_node_id corresponds to a DN. Generally, over 5% difference between the amount of data on different DNs is regarded as data skew. If the difference is over 10%, choose another distribution key.
- You are not advised to add a column as a distribution key, especially add a new column and use the SEQUENCE value to fill the column. (Sequences may cause performance bottlenecks and unnecessary maintenance costs.)
Using Partitioned Tables
Partitioning refers to splitting what is logically one large table into smaller physical pieces based on specific schemes. The table based on the logic is called a partitioned table, and a physical piece is called a partition. Data is stored on these smaller physical pieces, namely, partitions, instead of the larger logical partitioned table. A partitioned table has the following advantages over an ordinary table:
- High query performance: The system queries only the concerned partitions rather than the whole table, improving the query efficiency.
- High availability: If a partition is faulty, data in the other partitions is still available.
- Easy maintenance: You only need to fix the faulty partition.
The partitioned tables supported by DWS include range partitioned tables and list partitioned tables. (List partitioned tables are supported only in cluster 8.1.3).
Using Partial Clustering
Partial Cluster Key is the column-based technology. It can minimize or maximize sparse indexes to quickly filter base tables. Partial cluster key can specify multiple columns, but you are advised to specify no more than two columns. Use the following principles to specify columns:
- The selected columns must be restricted by simple expressions in base tables. Such constraints are usually represented by Col, Op, and Const. Col specifies the column name, Op specifies operators, (including =, >, >=, <=, and <) Const specifies constants.
- Select columns that are frequently selected (to filter much more undesired data) in simple expressions.
- List the less frequently selected columns on the top.
- List the columns of the enumerated type at the top.
Selecting a Data type
You can use data types with the following features to improve efficiency:
- Data types that boost execution efficiency
Generally, the calculation of integers (including common comparison calculations, such as =, >, <, ≥, ≤, and ≠ and GROUP BY) is more efficient than that of strings and floating point numbers. For example, if you need to perform a point query on a column-store table whose NUMERIC column is used as a filter criterion, the query will take over 10 seconds. If you change the data type from NUMERIC to INT, the query takes only about 1.8 seconds.
- Selecting data types with a short length
Data types with short length reduce both the data file size and the memory used for computing, improving the I/O and computing performance. For example, use SMALLINT instead of INT, and INT instead of BIGINT.
- Same data type for a join
You are advised to use the same data type for a join. To join columns with different data types, the database needs to convert them to the same type, which leads to additional performance overheads.
Using Indexes
- The purpose of creating indexes is to accelerate queries. Therefore, ensure that indexes can be used in some queries. If an index is not used by any query statement, the index is meaningless. Delete such an index.
- Do not create unnecessary secondary indexes. Useful secondary indexes can accelerate query. However, the space occupied by indexes increases with the number of indexes. Each time an index is added, an additional key-value pair needs to be added when a piece of data is inserted. Therefore, the more indexes, the slower the write speed, and the larger the space usage. In addition, too many indexes affect the optimizer running time, and inappropriate indexes mislead the optimizer. Having more indexes does not necessarily lead to better results.
- Create proper indexes based on service characteristics. In principle, indexes need to be created for columns required in a query to improve performance. Indexes can be created in the following scenarios:
- For columns with high differentiation, indexes can significantly reduce the number of rows after filtering. For example, you are advised to create an index in the ID card number column, but not in the gender column.
- If there are multiple query conditions, you can select a combination index. Note that the column of the equivalent condition must be placed before the combination index. For example, if your query is SELECT * FROM t where c1 = 10 and c2 = 100 and c3 > 10;, create a composite index Index cidx (c1, c2, c3) to optimize scanning.
- When an index column is used as a query condition, do not perform calculation, function, or type conversion on the index column. Otherwise, the optimizer cannot use the index.
- Ensure that the index column contains the query column. Do not always run the SELECT * statement to query all columns.
- Indexes are not utilized when != or NOT IN are used in query conditions.
- When LIKE is used, if the condition starts with the wildcard %, the index cannot be used.
- If multiple indexes are available for a query condition but you know which index is the optimal one, you are advised to use the optimizer hint to force the optimizer to use the index. This prevents the optimizer from selecting an incorrect index due to inaccurate statistics or other problems.
- When the IN expression is used as the query condition, the number of matched conditions should not be too large. Otherwise, the execution efficiency is low.
Feedback
Was this page helpful?
Provide feedbackThank you very much for your feedback. We will continue working to improve the documentation.




