更新时间:2025-04-23 GMT+08:00
血缘关系
自动血缘解析
自动血缘解析无需进行手动配置,当数据开发作业中包含如表1所示节点及场景时,系统支持自动解析血缘关系。

解析SQL节点的血缘时,支持多SQL解析及列级血缘解析,单条SQL语句不支持SQL中含有分号的场景。
| 作业节点 | 支持场景 |
|---|---|
| DLI SQL |
|
| DWS SQL | 支持Insert into等DML操作产生的DWS表之间的血缘。 |
| MRS Hive SQL | 支持Insert into/overwrite等DML操作产生的MRS表之间的血缘。 |
| MRS Spark SQL | 支持Insert into/overwrite等DML操作产生的MRS表之间的血缘。 |
| CDM Job | 支持MRS Hive、DLI、DWS、RDS、OBS以及CSS之间表文件迁移所产生的血缘。 |
| ETL Job | 支持DLI、OBS、MySQL以及DWS之间的ETL任务产生的血缘。 |
手动配置血缘
在DataArts Studio数据开发的作业中,您可以在数据开发作业节点中,自定义血缘关系的输入表和输出表。注意,当手动配置血缘时,此节点的自动血缘解析将不生效。
支持手动配置血缘的作业节点类型如下所示。
- CDM Job
- Rest Client
- DLI SQL
- DLI Spark
- DWS SQL
- MRS Spark SQL
- MRS Hive SQL
- MRS Presto SQL
- MRS Spark
- MRS Spark Python
- ETL Job
- OBS Manager
手动配置血缘时,在节点的“血缘关系”页签,配置血缘的输入和输出表。输入和输出表的所属数据源支持DLI、DWS、Hive、CSS、OBS和CUSTOM。CUSTOM即自定义类型,在手动配置血缘时,对于不支持的数据源,您可以添加为自定义类型。
图1 手动配置血缘关系示例
例如,当需要配置数据开发Pipeline作业中MRS Spark节点的血缘关系时,由于MRS Spark节点不支持自动血缘解析,则需要手动配置MRS Spark节点的血缘关系。操作步骤如下:
- 在数据开发组件,进入“数据开发 > 作业开发”页签,单击需要手动配置血缘关系的作业名,打开作业画布。
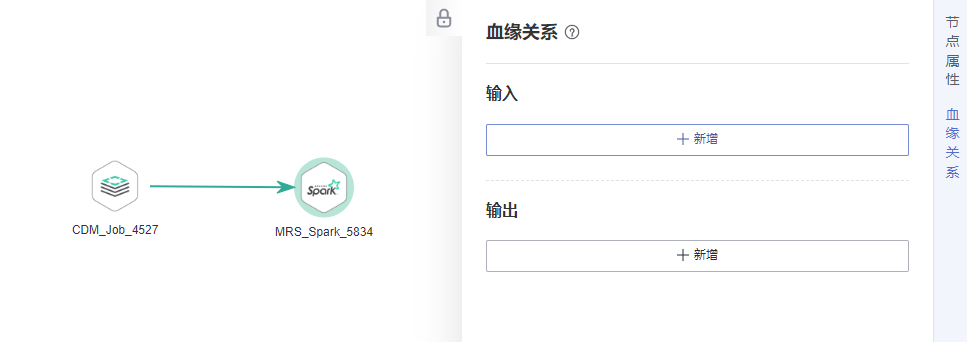
- 单击作业画布中的MRS Spark节点,并切换到“血缘关系”页签。 图2 进入血缘关系页签
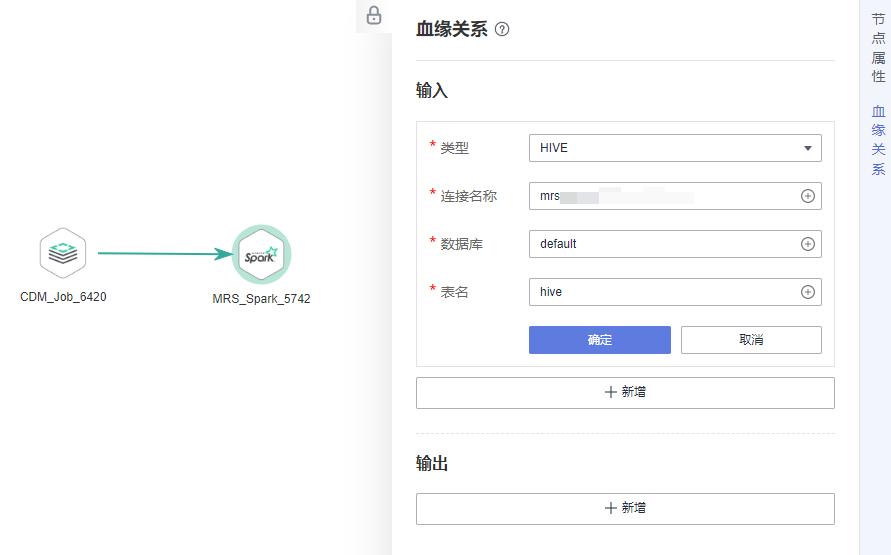
- 在MRS Spark节点的“血缘关系”页签,手动配置血缘的输入表。假如MRS Spark作业中的输入表为“hive”,则血缘输入配置如图3所示。
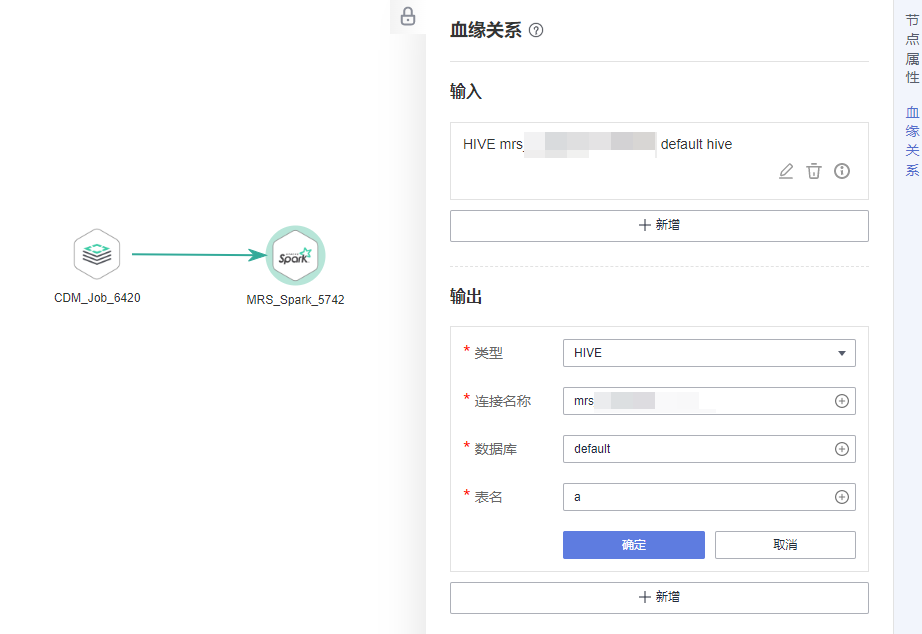
- 完成血缘的输入表配置后,单击确定,继续配置血缘的输出表。假如MRS Spark作业中的输出表为“a”,则血缘输出配置如图4所示。
- 完成血缘的输出表配置后,单击确认,则此MRS Spark节点的血缘关系手动配置成功。后续当需要查看血缘关系时,参考查看数据血缘完成元数据采集,并成功完成作业调度后,即可在数据目录组件查看手动配置的MRS Spark节点血缘关系。