配置NFS Server的HA机制
操作场景

如果您选择使用SFS Turbo实现文件共享存储,此章节可跳过。
在双NFS Server的场景下,需要配置NFS Server之间的同步机制,确保NFS Server能够正常给SAP HANA提供服务。
前提条件
操作步骤
- 初始化集群信息。
- 以“root”帐号和密钥文件登录Jump Host,并通过SSH协议,跳转到待作为主节点的NFS Server,假设其名称为nfs01。
- 在主节点上,执行以下命令,进入集群配置界面。
- 系统弹出下述提示。输入“y”,并按“Enter”键。
WARNING: NTP is not configured to start at system boot. WARNING: No watchdog device found. If SBD is used, the cluster will be unable to start without a watchdog. Do you want to continue anyway? [y/N]
- 系统弹出下述提示。输入“n”,并按“Enter”键。
/root/.ssh/id_rsa already exists - overwrite? [y/N]
- 系统弹出下述提示,请输入NFS Server的心跳网段,并按“Enter”键。
例如,输入网段“10.0.4.0”
Network address to bind to (e.g.: 192.168.1.0) []
- 系统弹出下述提示,采用默认设置,并按“Enter”键。
Multicast address (e.g.: 239.x.x.x) [239.97.171.218]
- 系统弹出下述提示,采用默认设置,并按“Enter”键。
Multicast port [5405]
- 系统弹出下述提示,输入“n”,并按“Enter”键。
Do you wish to use SBD? [y/N]
- 系统弹出下述提示,输入“n”,并按“Enter”键。

为了保证系统安全,可在完成HA机制的全部配置后,修改“hacluster”的密码。
... Log in with username 'hacluster', password 'linux' WARNING: You should change the hacluster password to something more secure! Enabling pacemaker.service Waiting for cluster........done Loading initial configuration ... Do you wish to configure an administration IP? [y/N] - 系统完成集群的初始化过程,提示如下:
Done (log saved to /var/log/ha-cluster-bootstrap.log)
- 将备节点加入集群。
- 在主节点nfs01上,将“corosync.conf”配置文件同步到备节点。
命令行如下
scp /etc/corosync/corosync.conf 备节点主机名称:/etc/corosync/
例如
scp /etc/corosync/corosync.conf nfs02:/etc/corosync/
- 在主节点上,以SSH方式登录到备节点。
- 执行以下命令,将备节点加入集群。
- 系统弹出下述提示。输入“y”,并按“Enter”键。
WARNING: NTP is not configured to start at system boot. WARNING: No watchdog device found. If SBD is used, the cluster will be unable to start without a watchdog. Do you want to continue anyway? [y/N]
- 系统弹出下述提示信息,输入主节点的心跳平面IP地址(例如“10.0.4.101”),并按“Enter”键。
IP address or hostname of existing node (e.g.: 192.168.1.1) []
- 系统弹出下述提示信息,输入“n”,并按“Enter”键。
/root/.ssh/id_rsa already exists - overwrite? [y/N]
- 系统完成备节点加入集群的初始化过程,提示如下:
……
WARNING: You should change the hacluster password to something more secure!
Enabling pacemaker.service
Waiting for cluster........done
Done (log saved to /var/log/ha-cluster-bootstrap.log)
- 在主节点nfs01上,将“corosync.conf”配置文件同步到备节点。
- 配置集群基础参数。
- 以VNC方式,以“root”帐号和密码,登录主节点,并进入命令行界面。
- 执行yast2命令,进入“YaST2 Control Center”界面,如图1所示。
- 选择,系统提示需要安装“hawk”软件包, 如图2所示,选择“Cancel”,按“Enter”。
- 系统提示“If you continue without installing required packages, YaST may not work properly.”,选择“Continue”,按“Enter”。进入Cluster的配置界面。
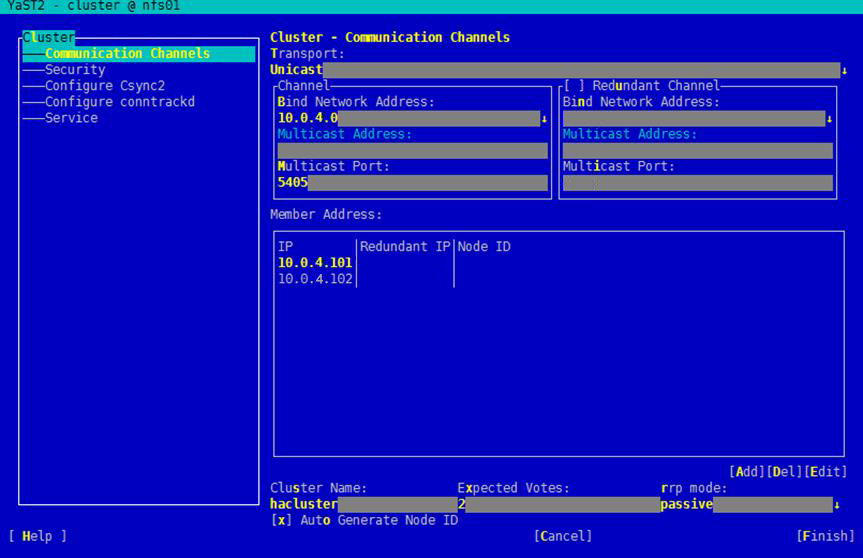
- 选择左侧的导航,并在右侧界面输入配置参数。示例如图3所示。
参数说明如下:
- Transport:选择“Unicast”。
- Channel区域框:“Bind Network Address”参数选择NFS Server心跳链路的网段,在这里为心跳平面的网段,例如“10.0.4.0”;“Multicast Port”参数采用默认值。
- Auto Generate Node ID:确保该参数为选中状态。
- Redundant Channel:无需配置。
- Member Address:通过“Add”添加主备NFS Server的心跳平面IP地址和业务/备份平面的IP地址。
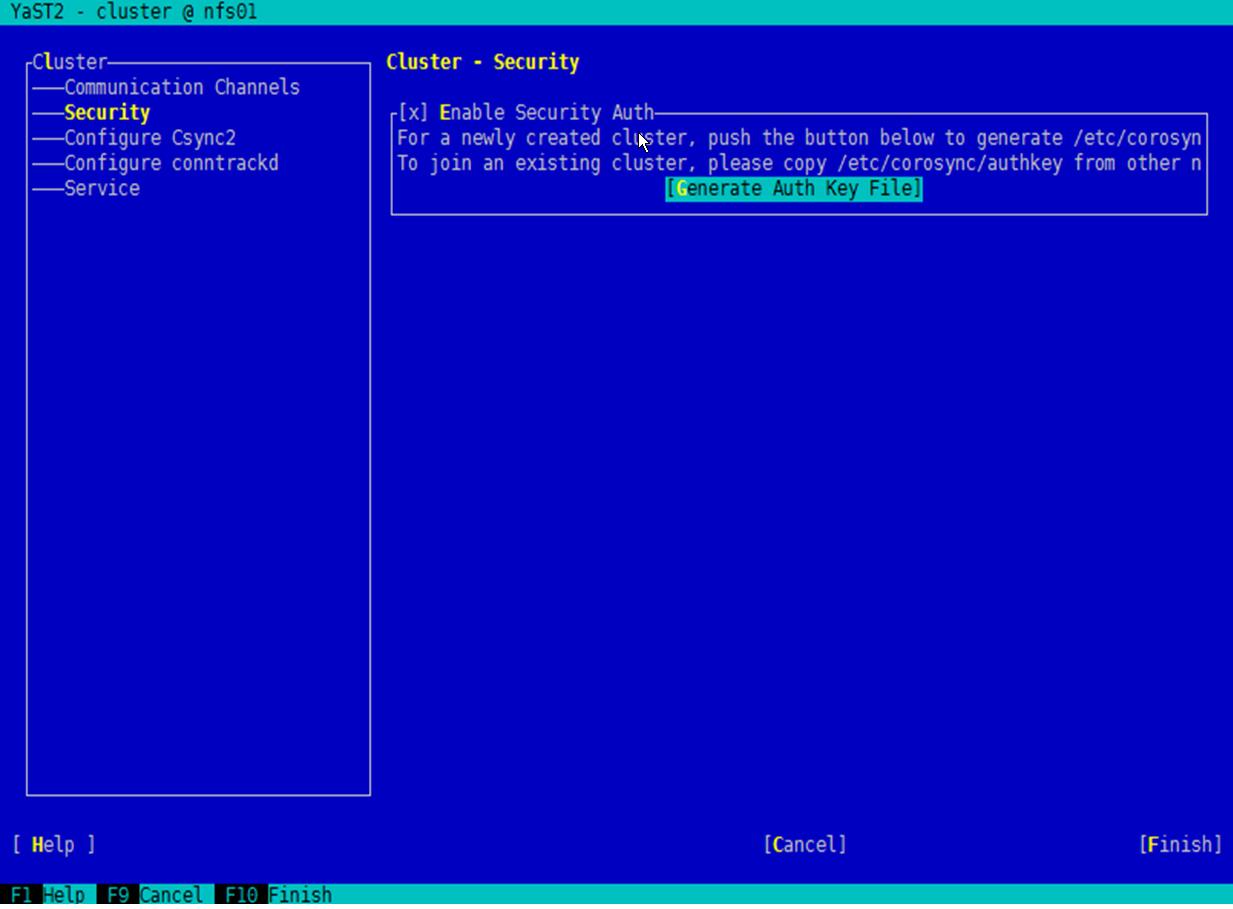
- 选择左侧的导航,并在右侧界面输入配置参数,如图4所示。
参数“Enable Security Auth”确保为选中状态。
然后,选中“Generate Auth Key File”并按“Enter”,系统弹出生成成功的提示信息,选中“OK”并按“Enter”,生成Auth Key文件。
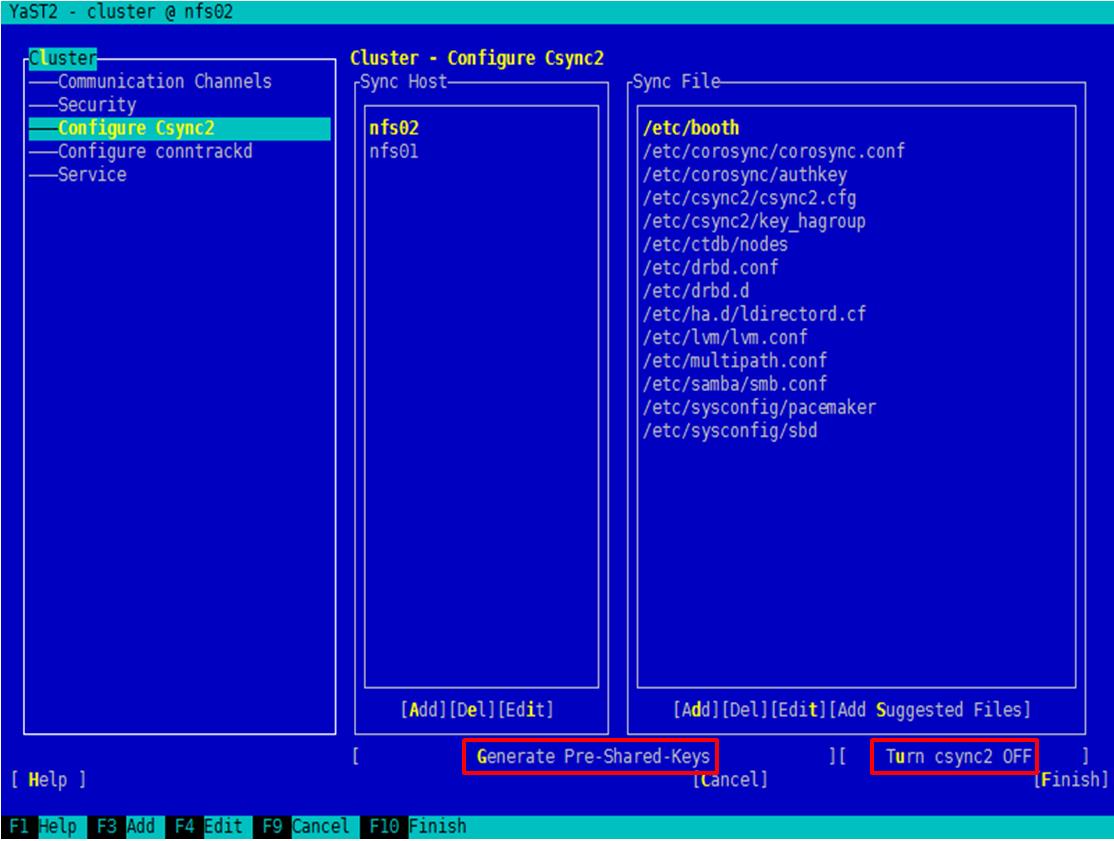
- 选择左侧的导航,并在右侧界面输入配置参数,如图5所示。
选中一个“Sync Host”的节点,然后选中“Generate Pre-Shared-Keys”并按“Enter”生成文件,同时确认右下方的按钮显示为“Turn csync2 OFF”,确保已打开Csync2 功能。
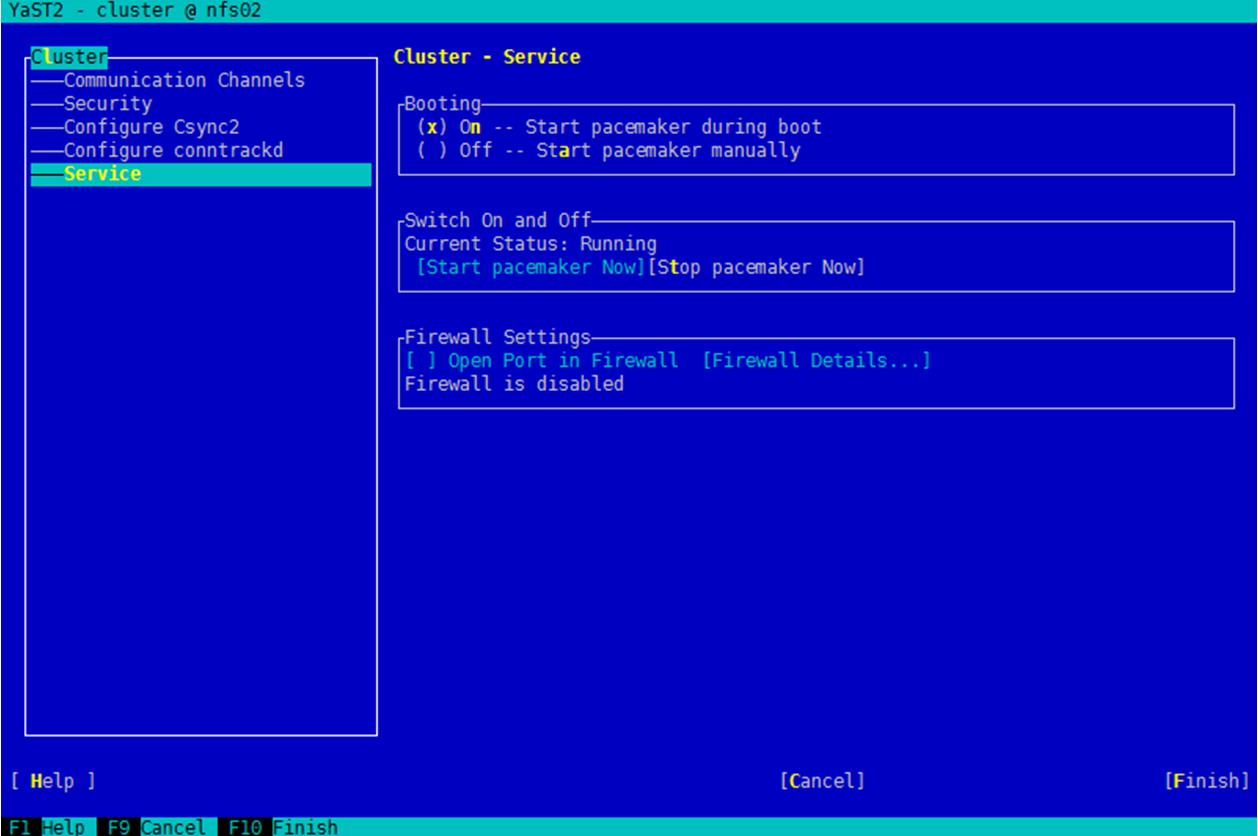
- 选择左侧的导航,并在右侧界面输入配置参数,如图6所示。
参数说明如下:
- Booting:默认选择“On”,服务器启动时启动集群。
- Switch on and off:确保为已启动集群。
- firewall settings:确保“Firewall is disabled”。
- 选中“Finish”并按“Enter”键完成配置。
- 将主节点的“key_hagroup ”和“csync2.cfg”文件复制到备节点。
以 “root”用户登录主节点,执行以下命令
scp /etc/csync2/key_hagroup /etc/csync2/csync2.cfg 备节点主机名称:/etc/csync2
例如
scp /etc/csync2/key_hagroup /etc/csync2/csync2.cfg nfs02:/etc/csync2
- 在主节点执行以下命令。
systemctl enable csync2.socket
systemctl enable xinetd
systemctl restart xinetd
- 在备节点执行以下命令
systemctl enable csync2.socket
systemctl enable xinetd
systemctl restart xinetd
- 重新在主节点执行以下命令,同步主备服务器配置文件。
- 在主节点检查集群状态
执行以下为命令,确保状态为“active (running)”。
如果回显的信息提示stonith磁盘未配置,此为正常现象。在后续的步骤中将配置stonith。
systemctl status pacemaker
- 在主节点重启集群
systemctl start pacemaker
- 在备节点检查集群状态
执行以下为命令,确保状态为“active (running)”。
如果回显的信息提示stonith磁盘未配置,此为正常现象。在后续的步骤中将配置stonith。
systemctl status pacemaker
- 在备节点重启集群
systemctl start pacemaker
- 在主节点查看集群心跳网络状态
可查看到主备心跳链路的心跳信息,请确保配置正常。示例如下:
Printing ring status. Local node ID 167772739 RING ID 0 id= 10.0.4.101 status= ring 0 active with no faults RING ID 1 id= 10.0.5.101 status= ring 1 active with no faults
- 在主节点查看集群是否正常。
系统返回的提示示例如下,两个NFS Server节点处于“Online”状态,表示集群正常。
Last updated: Wed Oct 19 17:40:31 2016 Last change: Tue Oct 18 15:32:00 2016 by root via cibadmin on hana01 Stack: classic openais (with plugin) Current DC: nfs01 - partition with quorum Version: 1.1.12-f47ea56 2 Nodes configured, 2 expected votes 0 Resources configured Online: [ nfs01 nfs02 ]
- 配置softdog。
- Fence设备上配置SBD信息。
- 在主备节点上设置sbd服务开机自启动
- 在主节点上,创建SBD分区
sbd -d /dev/disk/by-id/磁盘分区的ID create
使用ll /dev/disk/by-id |grep 分区名称|grep scsi-3命令查询SDB盘的ID。例如,磁盘分区为/dev/sdb1,则使用ll /dev/disk/by-id |grep sdb|grep scsi-3找到sdb1对应的ID。
例如
sbd -d /dev/disk/by-id/scsi-36888603000000db7fa179ea56210049-part1 create
- 将该分区分配给主节点
sbd -d /dev/disk/by-id/磁盘分区的ID allocate 主节点的主机名称
例如
sbd -d /dev/disk/by-id/scsi-36888603000000db7fa179ea56210049-part1 allocate nfs01
- 将该分区分配给备节点
sbd -d /dev/disk/by-id/磁盘分区的ID allocate 备节点的主机名称
例如
sbd -d /dev/disk/by-id/scsi-36888603000000db7fa179ea56210049-part1 allocate nfs02
- 查询分配信息
sbd -d /dev/disk/by-id/磁盘分区的ID list
例如
sbd -d /dev/disk/by-id/scsi-36888603000000db7fa179ea56210049-part1 list
回显如下:
0 nfs01 clear 1 nfs02 clear
- 执行以下命令
sbd -d /dev/disk/by-id/磁盘分区的ID dump
例如
sbd -d /dev/disk/by-id/scsi-36888603000000db7fa179ea56210049-part1 dump
- 打开SBD文件。
执行vi /etc/sysconfig/sbd命令打开文件,并在文件中添加信息。
示例如下:
SBD_DEVICE信息中的路径,以SBD磁盘的分区信息为准,下面内容为示例。
SBD_DEVICE="/dev/disk/by-id/scsi-36888603000000db7fa179ea56210049-part1" SBD_OPTS="-W"
- 在主节点上将配置文件同步到备节点。
scp /etc/sysconfig/sbd 备节点主机名称:/etc/sysconfig
例如
scp /etc/sysconfig/sbd nfs02:/etc/sysconfig
- 在主节点重启集群服务
systemctl start pacemaker
- 在备节点重启集群服务
systemctl start pacemaker
- 检查集群配置
系统返回的提示示例如下,两个NFS Server节点处于“Online”状态,表示集群正常。
Last updated: Wed Oct 19 17:40:31 2016 Last change: Tue Oct 18 15:32:00 2016 by root via cibadmin on hana01 Stack: classic openais (with plugin) Current DC: nfs01 - partition with quorum Version: 1.1.12-f47ea56 2 Nodes configured, 2 expected votes 0 Resources configured Online: [ nfs01 nfs02 ]
- 添加Fence SBD资源。
- 创建虚拟业务IP。
- 在管理控制台,单击,进入“弹性云服务器”管理界面。
- 找到一台NFS Server对应的云服务器,并单击云服务器的名称,弹出云服务器的详细信息。
- 单击“网卡”页签,在云服务器的业务/管理平面网卡后,单击“管理私有IP地址”,弹出“虚拟IP地址”界面。
- 单击“申请虚拟IP地址”分配规划的浮动IP地址,在分配好的浮动IP栏单击“绑定服务器”,绑定给所需的云服务器,重复执行绑定操作给其他云服务器。
- 在主节点的命令行界面,CRM的配置模式下,执行以下命令
命令中,params ip即为NFS Server的虚拟业务IP,应按照实际填写。
primitive nfs_vip ocf:heartbeat:IPaddr2 params ip=10.0.1.103 op monitor interval="10" timeout="20" on-fail=restart
commit
- 创建集群共享卷文件系统
在主节点,执行以下命令,分别为Shared卷和Backup卷创建集群共享卷文件系统。
命令中params device和directory为磁盘ID及路径,应按照实际填写。查看磁盘ID的方法可参见5.b中的相关描述。
primitive nfs_shared ocf:heartbeat:Filesystem params device="/dev/disk/by-id/磁盘分区的ID" directory="/shared" fstype=xfs op monitor interval="10" timeout="40" on-fail=restart
primitive nfs_bak ocf:heartbeat:Filesystem params device="/dev/disk/by-id/磁盘分区的ID" directory="/backup" fstype=ext3 op monitor interval="10" timeout="40" on-fail=restart
primitive nfs_sapmnt ocf:heartbeat:Filesystem params device="/dev/disk/by-id/磁盘分区的ID" directory="/sapmnt " fstype=ext3 op monitor interval="10" timeout="40" on-fail=restart
primitive nfs_sys ocf:heartbeat:Filesystem params device="/dev/disk/by-id/磁盘分区的ID" directory="/usr/sap/A01/SYS" fstype=ext3 op monitor interval="10" timeout="40" on-fail=restart
primitive nfs_sapcd ocf:heartbeat:Filesystem params device="/dev/disk/by-id/磁盘分区的ID" directory="/sapcd" fstype=ext3 op monitor interval="10" timeout="40" on-fail=restart
commit
- 创建NFS资源。
在主节点的CRM的配置模式下,创建名称为“nfsserver”的资源,执行以下命令。
其中,nfs_ip为NFS Server的浮动IP地址。
primitive nfsserver nfsserver params nfs_ip=10.0.5.103 nfs_shared_infodir="/shared" nfs_shared_infodir="/backup" nfs_shared_infodir="/sapmnt" nfs_shared_infodir="/usr/sap/A01/SYS" nfs_shared_infodir="/sapcd" operations $id=nfsserver-operations op monitor interval="10" timeout="20" on-fail=restart
commit
- 创建资源组。
在主节点的CRM的配置模式下,将7.e~9创建的资源,创建为名称为“nfs_group”的资源组
group nfs_group nfs_vip nfs_shared nfs_bak nfs_sapmnt nfs_sys nfs_sapcd nfsserver
commit
- 创建Clone Ping。
在主节点的CRM的配置模式下,执行以下命令,创建Clone Ping
primitive r_ping ocf:pacemaker:ping params multiplier="100" dampen="5" host_list="10.0.5.1" op monitor interval="15" timeout="60" start="60" op start interval="0" timeout="60"
clone PING r_ping
commit
参数说明如下:
- r_ping表示clone ping的资源名称。
- Multiplier是一个增效器,以100这个值为基准,两个节点ping数据包有丢失时就会从100减去相应的值,以此来判断节点的业务网卡的通迅情况。
- dampen表示每5秒ping一次
- 10.0.5.1代表NFS Server的业务/备份平面的网段的网关。
- monitor表示监控资源;interval表示若15秒ping不到上层交换设备,最迟60秒(timeout)就会迁移资源(start)。
- 创建约束条件
在主节点的CRM的配置模式下,执行以下命令,为资源组“nfs_group”创建约束条件名称为“nfs_conn”
location nfs_conn nfs_group rule -inf: not_defined pingd or pingd lte 0
commit
- 配置其他信息