LDA
概述
LDA主题分析模型(Latent Dirichlet Allocation),由Blei等人于2003年提出的无监督学习算法,可以按照概率分布的形式给出文档集中每篇文档的主题,在文本挖掘领域,应用于文本主题识别、文本分类和文本相似度计算等方面。
输入
参数 |
子参数 |
参数说明 |
|---|---|---|
inputs |
dataframe |
inputs为字典类型,dataframe为pyspark中的DataFrame类型对象。如果文本为中文则需要先以空格为分隔符对原始文本进行分词。 |
输出
参数 |
子参数 |
参数说明 |
|---|---|---|
output |
P(Z) |
主题概率 |
P(Z|D) |
主题-文档概率 |
|
P(D|Z) |
文档-主题概率 |
|
P(Z|W) |
主题-词汇概率 |
|
vocab |
词汇表 |
参数说明
参数 |
是否必选 |
参数说明 |
默认值 |
|---|---|---|---|
sentence_col |
是 |
文本列 |
"sentence" |
topics_k |
是 |
主题数目>=2 |
2 |
min_doc_freq |
否 |
最小词数阈值 |
0 |
words_col |
否 |
分词后的words列 |
"words" |
feature_col |
否 |
features列 |
"features" |
raw_features_col |
否 |
raw features列 |
"rawFeatures" |
topic_distribution_col |
否 |
topic distribution列 |
"topicDistributionCol" |
max_iter |
是 |
最大迭代次数 |
50 |
idf_or_not |
否 |
是否使用idf |
False |
topic_concentration |
是 |
超参数\eta |
1.1 |
doc_concentration |
是 |
超参数\alpha |
1.1 |
样例
数据样本
id |
sentence |
|---|---|
1 |
ball ball fun planet galaxy |
2 |
referendum referendum fun planet planet |
3 |
planet planet planet galaxy ball |
4 |
planet galaxy planet referendum ball |
配置流程
运行流程

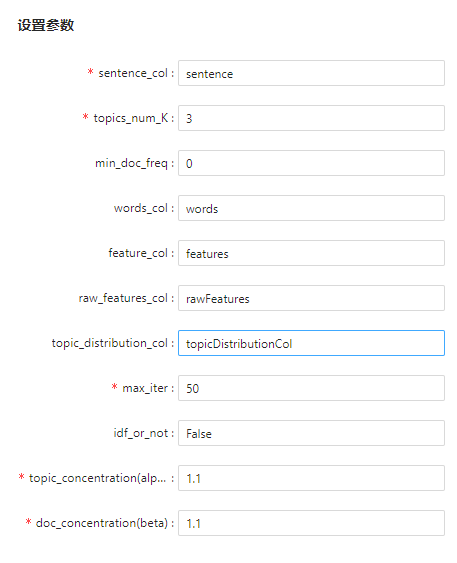
参数设置
结果查看
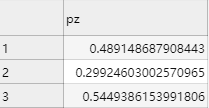
P(Z)
P(Z|D)

P(D|Z)

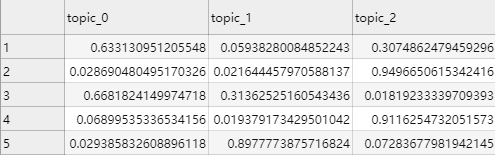
P(Z|W)
vocab