

文本分类
概述
文本分类通过TF-IDF和多项式朴素贝叶斯进行文本分类,以原始文本和标签作为输入,输出文本分类模型。
输入
参数 |
子参数 |
参数说明 |
|---|---|---|
inputs |
dataframe |
inputs为字典类型,dataframe为pyspark中的DataFrame类型对象。如果文本为中文则需要先以空格为分隔符对原始文本进行分词。 |
输出
参数 |
子参数 |
参数说明 |
|---|---|---|
output |
output_port_1 |
output为字典类型,output_port_1为pyspark中的PipelineModel模型类型。 |
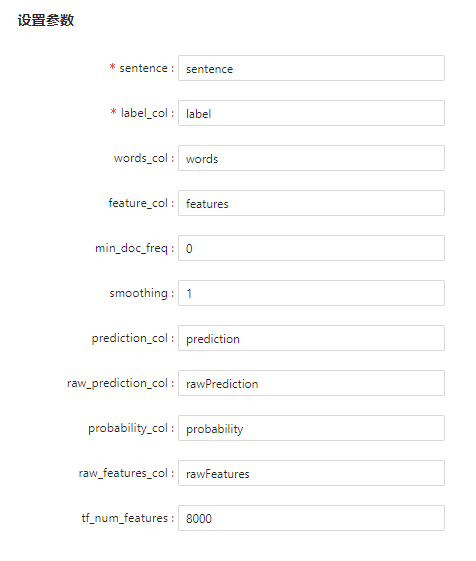
参数说明
参数 |
是否必选 |
参数说明 |
默认值 |
|---|---|---|---|
sentence_col |
是 |
文本列 |
"sentence" |
label_col |
是 |
标签列(标签值需整数或浮点型) |
"label" |
words_col |
否 |
用于分词后保存words的列名 |
"words" |
feature_col |
否 |
用于保存feature的列名 |
"features" |
min_doc_freq |
否 |
最小词数阈值 |
0 |
smoothing |
否 |
平滑指数 |
1.0 |
prediction_col |
否 |
用于保存prediction的列名 |
"prediction" |
raw_prediction_col |
否 |
用于保存raw_prediction的列名 |
"raw_prediction" |
probability_col |
否 |
用于保存probability的列名 |
"probability" |
raw_features_col |
否 |
用于保存raw_features的列名 |
"raw_features" |
tf_num_features |
否 |
tf-idf时用于保存的词的数量,建议不小于词汇种类 |
8000 |
样例
数据样本
id |
sentence |
label |
|---|---|---|
1 |
ball ball fun planet galaxy |
1 |
2 |
referendum referendum fun planet planet |
0 |
3 |
planet planet planet galaxy ball |
1 |
4 |
planet galaxy planet referendum ball |
1 |
sentence |
|---|
ball ball ball |
referendum referendum |
planet planet ball |
配置流程
运行流程

参数设置
结果查看
sentence |
words |
rawFeatures |
features |
rawPrediction |
probability |
prediction |
|---|---|---|---|---|---|---|
ball ball ball |
['ball', 'ball', 'ball'] |
(8000,[5492],[3.0]) |
(8000,[5492],[0.6694306539426294]) |
[-7.115045557028399,-5.9949311191899355] |
[0.24599005712406302,0.7540099428759369] |
1 |
referendum referendum |
['referendum', 'referendum'] |
(8000,[999],[2.0]) |
(8000,[999],[1.0216512475319814]) |
[-9.561433564101923,-9.165985052719044] |
[0.402406373461625,0.5975936265383749] |
1 |
planet planet ball |
['planet', 'planet', 'ball'] |
(8000,[5492,6309],[1.0,2.0]) |
(8000,[5492,6309],[0.22314355131420976,0.0]) |
[-3.104090044788206,-2.2686204451354213] |
[0.3024897957164007,0.6975102042835993] |
1 |








