

更新时间:2024-05-27 GMT+08:00
加权采样
概述
加权采样是一种数据采样算法,依据数据集中权重列进行数据采样,权重越大的样本被采样的概率越大。
输入
参数 |
子参数 |
参数说明 |
|---|---|---|
inputs |
dataframe |
inputs为字典类型,dataframe为pyspark中的DataFrame类型。 |
输出
参数 |
子参数 |
参数说明 |
|---|---|---|
output |
output_port_1 |
output为字典类型,output_port_1为pyspark中的DataFrame类型对象,为加权采样结果。 |
参数说明
参数 |
是否必选 |
参数说明 |
默认值 |
|---|---|---|---|
weight_col |
是 |
权重列。 |
"weight" |
sample_size |
否 |
采样数量。 |
100 |
sample_ratio |
否 |
采样比例,范围(0,1),如果sample_size和sample_ratio同时设置,以sample_size为准。 |
0.2 |
with_replacement |
是 |
是否有放回采样。 |
True |
partitions |
否 |
分区数,有放回采样需设置该参数,数据量较大时可将该参数调大。 |
10 |
random_seed |
否 |
随机种子。 |
1234 |
样例
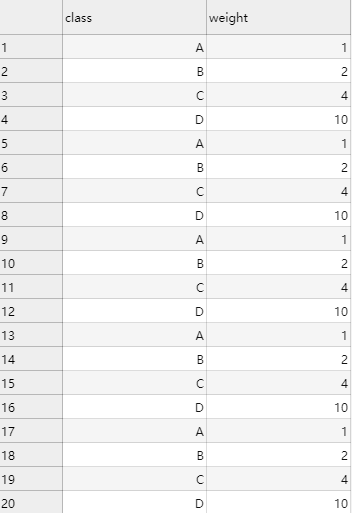
截取部分样例数据如下,weight为权重列,class列中包括A,B,C,D四种类别,权重分别为1,2,4,10。
配置流程
运行流程

参数设置
以按比例采样为例,设置有放回采样

查看结果
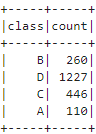
将最终采样结果分组统计,查看A,B,C,D四种类别数据的采样数据量,结果如下,符合权重越大采样概率越大
父主题: 数据处理








