

更新时间:2024-05-27 GMT+08:00
分层采样
概述
分层采样是一种数据采样算法,依据数据集中某一代表数据类别的列,按照数量或比例对不同类别的数据进行采样。

算法实现采用spark自带的sample函数,采样数量会存在一定误差(按比例采样和按数量采样均会存在)。
输入
参数 |
子参数 |
参数说明 |
|---|---|---|
inputs |
dataframe |
inputs为字典类型,dataframe为pyspark中的DataFrame类型。 |
输出
参数 |
子参数 |
参数说明 |
|---|---|---|
output |
output_port_1 |
output为字典类型,output_port_1为pyspark中的DataFrame类型对象,为分层采样结果。 |
参数说明
参数 |
是否必选 |
参数说明 |
默认值 |
|---|---|---|---|
strata_col |
是 |
分层列, 按此列进行分层采样。 |
无 |
sample_size |
否 |
采样个数。为整数时:表示每个层的采样个数;为字符串时:格式为strata0:n0,strata1:n1,…表示每个层分别设置的采样个数。 |
无 |
sample_ratio |
否 |
采样比例。为数字时:范围(0,1) 表示每个层的采样比例;字符串时:格式为strata0:r0,strata1:r1,…表示每个层分别设置的采样比例。 |
0.2 |
random_seed |
是 |
随机种子。 |
123 |
样例
数据样本
鸢尾花数据集,species列代表鸢尾花种类,共有Iris-setosa、Iris-versicolor和Iris-virginica三种类别,每种类别样本数量为50。

配置流程
运行流程

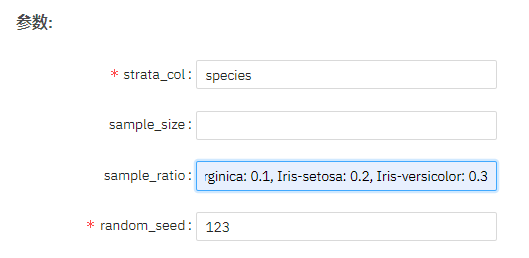
参数设置
按比例采样,并分别指定每个种类的采样比例,如果sample_ratio为数字例如0.3,则所有类别数据均采样30%
父主题: 数据处理








