

孤立森林[PySpark版]
概述
孤立森林(Isolation Forest),简称为iForest,用于挖掘异常(Anomaly)数据,从数据中找出与其它数据的规律不符合的数据。通常用于网络安全中的攻击检测和流量异常等分析,金融机构则用于挖掘出欺诈行为。
输入
参数 |
子参数 |
参数说明 |
|---|---|---|
inputs |
dataframe |
inputs为字典类型,dataframe为pyspark中的DataFrame类型对象。 |
输出
参数 |
子参数 |
参数说明 |
|---|---|---|
output |
output_port_1 |
output为字典类型,output_port_1为pyspark中的PipelineModel类型对象,为训练出的孤立森林模型。 |
output |
output_port_2 |
output为字典类型,output_port_1为pyspark中的DataFrame类型对象,孤立森林算法的检测结果。 |
参数说明
参数 |
是否必选 |
参数说明 |
默认值 |
|---|---|---|---|
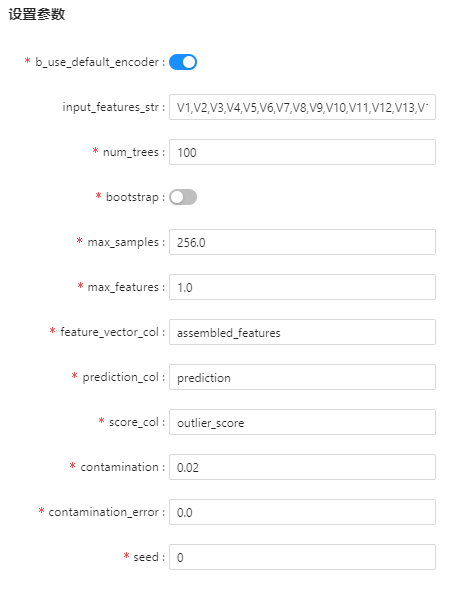
b_use_default_encoder |
是 |
是否对数据中的类别型特征列进行编码处理。 |
True |
input_features_str |
否 |
选择特征列,逗号分隔。 |
无 |
num_trees |
是 |
孤立森林中树的个数。 |
100 |
bootstrap |
是 |
采样数据构建孤立树时是否为有放回采样。 |
False |
max_samples |
是 |
训练单棵孤立树的最大样本个数,该值小于1.0时该值乘以总样本数取整得到单棵孤立树的训练样本数,大于1.0时取整得到单棵数的训练样本数。 |
256.0 |
max_features |
是 |
参与训练的特征数,小于等于1.0时特征为该值乘以总特征个数。 |
1.0 |
feature_vector_col |
是 |
input_features_str中的特征列处理为向量列后的列名。 |
"assembled_features" |
prediction_col |
是 |
预测结果列名。 |
"prediction" |
score_col |
是 |
异常分数列,该列数值为孤立森林算法中每个样本的分数值,值越大异常可能越大。 |
"outlier_score" |
contamination |
是 |
异常值比例,取值0到1浮点数,score_col列中数值大于contamination * 100%分位数值的样本视为异常值, 如果为0.0则prediction_col列输出均为0.0非异常。 |
0.0 |
contamination_error |
是 |
计算分位数时允许的误差,如果为0.0则实际计算时为contamination * 0.01。 |
0.0 |
seed |
是 |
随机种子。 |
0 |
样例
数据样本为信用卡欺诈检测数据,包含Time,V1,V2,V3,V4,V5,V6,V7,V8,V9,V10,V11,V12,V13,V14,V15,V16,V17,V18,V19,V20,V21,V22,V23,V24,V25,V26,V27,V28,Amount等特征。

配置流程
下图上边部分运行孤立森林算子,得到异常检测结果和孤立森林模型,下边部分加载保存的模型和新的数据进行预测。

参数设置
查看结果









