

使用WAF阻止爬虫攻击
应用场景
网络爬虫为网络信息收集与查询提供了极大的便利,但同时也对网络安全产生以下负面影响:
- 网络爬虫会根据特定策略尽可能多地“爬过”网站中的高价值信息,占用服务器带宽,增加服务器的负载
- 恶意用户利用网络爬虫对Web服务发动DoS攻击,可能使Web服务资源耗尽而不能提供正常服务
- 恶意用户利用网络爬虫抓取各种敏感信息,造成网站的核心数据被窃取,损害企业经济利益
Web应用防火墙可以通过常规检测和Webshell检测(识别User-Agent)、网站反爬虫(检查浏览器合法性)和CC攻击防护(限制访问频率)三个反爬虫策略,全方位帮您解决业务网站遭受的爬虫问题。
方案概述
爬虫检测流程如图1所示,其中,①和②称为“js挑战”,③称为“js验证”。
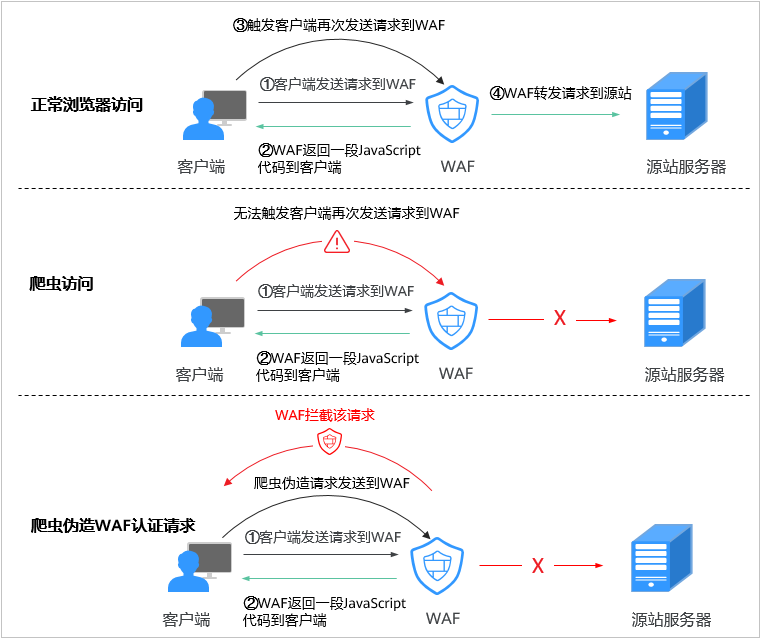
- 如果客户端是正常浏览器访问,就可以触发这段JavaScript代码再发送一次请求到WAF,即WAF完成js验证,并将该请求转发给源站。
- 如果客户端是爬虫访问,就无法触发这段JavaScript代码再发送一次请求到WAF,即WAF无法完成js验证。
- 如果客户端爬虫伪造了WAF的认证请求,发送到WAF时,WAF将拦截该请求,js验证失败。
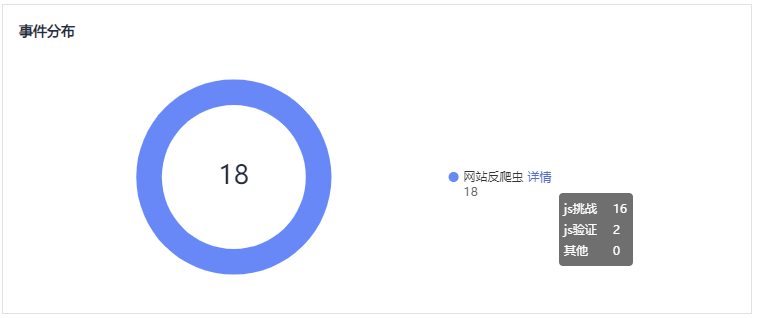
通过统计“js挑战”和“js验证”,就可以汇总出JS脚本反爬虫防御的请求次数。例如,图2中JS脚本反爬虫共记录了18次事件,其中,“js挑战”(WAF返回JS代码)为16次,“js验证”(WAF完成JS验证)为2次,“其他”(即爬虫伪造WAF认证请求)为0次。
约束与限制
资源与成本规划
| 资源 | 资源说明 | 每月费用 |
|---|---|---|
| Web应用防火墙 | 云模式-专业版:
| 具体的计费方式及标准请参考计费说明。 |
步骤一:购买云模式专业版
以购买WAF云模式标准版为例进行介绍。
- 登录Web应用防火墙控制台。
- 在页面右上角,单击“购买WAF实例”,进入购买页面,“WAF模式”选择“云模式”。
- “区域”:根据防护业务的所在区域就近选择购买的WAF区域。
- “版本规格”:选择“专业版”。
- “扩展包”及“购买时长”:根据具体情况进行选择。
- 确认参数配置无误后,在页面右下角单击“立即购买”。
- 确认订单详情无误后,阅读并勾选《Web应用防火墙免责声明》,单击“去支付”,完成购买操作。
- 进入“付款”页面,选择付款方式进行付款。
订单支付成功后,单击“进入Web应用防火墙控制台”,进入WAF“总览”页面。将鼠标悬停在“产品信息”区域,查看已购实例版本及其详细规格。
步骤二:将网站信息添加到WAF
此处以云模式-CNAME接入为例进行介绍。
- 云模式-ELB接入方式请参见将网站接入WAF防护(云模式-ELB接入)。
- 独享模式接入方式请参见将网站接入WAF防护(独享模式)。
- 在左侧导航树中,选择“网站设置”,进入网站设置列表。
- 在网站列表的左上角,单击“添加防护网站”。
- 选择“云模式-CNAME接入”并单击“开始配置”。
- 根据界面提示,配置网站信息,如表2所示。 图3 基础信息配置

表2 重点参数说明 参数
参数说明
取值样例
防护域名
需要添加到WAF中防护的域名。
- 域名已完成备案
- 支持单域名(例如,一级域名example.com,二级域名www.example.com等)和泛域名(例如,*.example.com)。
www.example.com
防护端口
需要防护的域名对应的业务端口。
标准端口
服务器配置
网站服务器地址的配置。包括对外协议、源站协议、源站地址、源站端口和权重。
- 对外协议:客户端请求访问服务器的协议类型。包括“HTTP”、“HTTPS”两种协议类型。
- 源站协议:Web应用防火墙转发客户端请求的协议类型。包括“HTTP”、“HTTPS”两种协议类型。
- 源站地址:客户端访问的网站服务器的公网IP地址(一般对应该域名在DNS服务商处配置的A记录)或者域名(一般对应该域名在DNS服务商处配置的CNAME)。
- 源站端口:WAF转发客户端请求到服务器的业务端口。
- 权重:负载均衡算法将按权重将请求分配给源站。
对外协议:HTTP
源站协议:HTTP
源站地址:IPv4 XXX.XXX.1.1
源站端口:80
是否使用七层代理
在WAF前是否使用了七层代理产品。
根据实际情况进行选择。
是
- 单击“下一步”,完成防护网站基本信息填写。根据“添加防护网站”面板提示,完成如下操作: 图4 添加域名完成

完成上述步骤后,您可以在域名列表,查看已添加的域名“接入状态”。此时,域名“接入状态”为“未接入”,原因为“修改DNS解析”。
步骤三:开启常规检测和Webshell检测(识别User-Agent)
开启常规检测和Webshell检测后,WAF可以检测和拦截恶意爬虫、网马等威胁。
- 登录Web应用防火墙控制台。
- 在控制台左上角,单击
 图标,选择区域或项目。
图标,选择区域或项目。 - 在左侧导航树中,选择“网站设置”,进入“网站设置”页面。
- 在目标域名所在行的“防护策略”栏中,单击“已开启N项防护”,进入“防护策略”页面。
- 确认“Web基础防护”的状态为
 。 图5 Web基础防护配置框
。 图5 Web基础防护配置框
- 在“防护配置”页面,开启“常规检测”和“Webshell检测”开关。 图6 防护配置

完成以上配置后,您可以模拟恶意爬虫攻击,查看请求是否被拦截。当WAF检测到恶意爬虫对网站进行爬取时,将立即拦截并记录该事件,您可以在“防护事件”页面查看爬虫防护日志。

步骤四:开启网站反爬虫(检查浏览器合法性)
开启网站反爬虫,WAF可以动态分析网站业务模型,结合人机识别技术和数据风控手段,精准识别爬虫行为。
- 选择“网站反爬虫”配置框,开启网站反爬虫。
 :开启状态。
:开启状态。 :关闭状态。
:关闭状态。
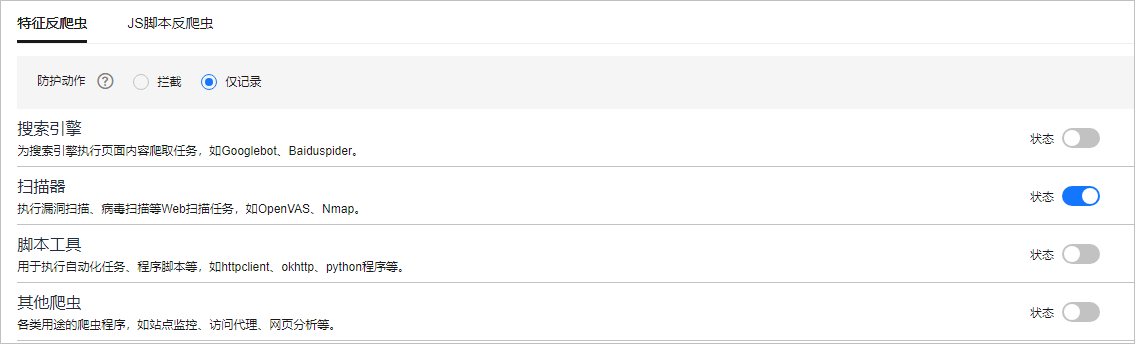
- 在“特征反爬虫”页面,开启“扫描器”,其他选项根据业务需要进行选择。 图7 特征反爬虫防护
- 在“JS脚本反爬虫”页签,配置JS脚本反爬虫规则。
 图8 JavaScript
图8 JavaScript
- 状态:配置“JS脚本反爬虫”启用状态。
 :开启状态。
:开启状态。 (默认):关闭状态。
(默认):关闭状态。
- 防护动作:设置请求命中规则时要执行的处置动作。
- 拦截:表示拦截命中规则的请求,并向发起请求的客户端返回拦截响应页面。
- 仅记录:表示不拦截命中规则的请求,只通过日志记录防护信息。
- 人机验证:表示JavaScript挑战失败,弹出验证码提示,输入正确的验证码,请求将不受访问限制。
- 防护模式:选择“JS脚本反爬虫”的防护模式。
- 防护所有请求:除了指定请求规则以外,防护其他所有请求,即规则状态为开启的防护规则不在防护范围内。单击“添加排除请求规则”,添加要排除的规则,相关参数说明如表3所示。
- 防护指定请求:只防护指定请求,即没有添加指定防护路径“/”请求或规则状态为关闭的,则表示所有路径“/”请求不在防护范围内。单击“防护指定请求”,添加要防护的规则,相关参数说明如表3所示。
表3 JS脚本反爬虫参数说明 参数
参数说明
示例
规则名称
自定义规则名称。
waf
规则描述
设置该规则的备注信息。
-
条件列表
配置要匹配的请求特征。请求一旦命中该特征,WAF则按照配置的规则处置该请求。
- 至少需要配置一项,本条规则才能生效。配置多个条件时,需同时满足,本条规则才生效。
- 单击“添加条件”增加新的条件,最多可添加30个条件。
条件设置参数说明如下:
- 字段:在下拉列表中选择需要检测的字段,当前仅支持“路径”、“User Agent”。
- 子字段:“路径”、“User Agent”字段无需设置子字段。
- 逻辑:在“逻辑”下拉列表中选择需要的逻辑关系。
- 内容:输入或者选择条件匹配的内容。
当“逻辑”关系选择“包含任意一个”、“不包含任意一个”、“等于任意一个”、“不等于任意一个”、“前缀为任意一个”、“前缀不为任意一个”、“后缀为任意一个”或者“后缀不为任意一个”时,需要选择引用表。
- 大小写敏感:“字段”选择“路径”时,可配置该参数。开启后,系统在检测配置的路径时,将区分大小写。能够帮助系统更准确地识别和处理各种爬虫请求,从而有效提升反爬虫策略的精确度和有效性。
“路径”包含“/admin/”
生效时间
规则添加后,立即生效。
立即生效
优先级
设置该条件规则检测的顺序值。如果您设置了多条规则,则多条规则间有先后匹配顺序,即访问请求将根据您设定的优先级依次进行匹配,优先级较小的规则优先匹配。
5
完成以上配置后,您还可以执行以下操作:
- 查看规则状态:在防护规则列表,查看已添加的规则。此时,“规则状态”默认为“已开启”。
- 关闭规则:如果您暂时不想使该规则生效,可在目标规则“操作”列,单击“关闭”。
- 删除或修改规则:您也可以在目标规则“操作”列,单击“删除”或“修改”,删除或修改已添加的防护规则。
- 状态:配置“JS脚本反爬虫”启用状态。
开启该防护后,非浏览器的访问将不能获取业务页面。

步骤五:配置CC攻击防护(限制访问频率)
开启CC攻击防护,限制单个IP/Cookie/Referer访问者对您的网站上特定路径(URL)的访问频率,缓解CC攻击对业务的影响。
- 确认“CC攻击防护”的“状态”为“开启”
 。 图9 CC防护规则配置框
。 图9 CC防护规则配置框
- 在“CC攻击防护”规则配置列表的左上方,单击“添加规则”。以IP限速和人机验证为例,添加IP限速规则,如图10所示。
设置成功后,当用户访问超过限制后需要输入验证码才能继续访问。






