

更新时间:2024-06-06 GMT+08:00
ClickHouse表字段设计
规则
- 不允许用字符类型存放时间或日期类数据,尤其是需要对该日期字段进行运算或者比较的时候。
- 不允许用字符类型存放数值类型的数据,尤其是需要对该数值字段进行运算或者比较的时候。字符串的过滤效率相对于整型或者特定时间类型有下降。
建议
- 不建议表中存储过多的Nullable列,可以考虑字符串使用“NA”,数值型用0作为缺省值。过多使用Nullable将消耗更多内存。
- 建议规划好业务所需的列,必要时可提前预置一些属性列,避免频繁的增删列。
- 数值类型:UInt8/UInt16/UInt32/UInt64、Int8/Int16/Int32/Int64, Float32/Float64等,选择不同长度,性能差别较大。
建议根据业务场景所需选择最小满足的类型使用。
- 示例
CREATE TABLE counter ON CLUSTER default_cluster ( `when` DateTime DEFAULT now(), `device` UInt32, `value` Float32, `value64` Float64 ) ENGINE = MergeTree PARTITION BY toYYYYMM(when) ORDER BY (device, when)
表中有Float32类型的字段value和Float64的字段value64插入数据的查询表现如下:
INSERT INTO counter SELECT toDateTime('2019-01-01 00:00:00') + toInt64(number / 10) AS when, (number % 10) + 1 AS device, (device * 3) + (number / 10000) AS value, value FROM system.numbers LIMIT 100000000;往value和value64插入相同的数据,总数据量1亿条。
- 查询Float32字段
耗时:0.750秒。
- 查询Float64字段
耗时:0.929秒。
结果:Float32类型的查询时间比Float64更快。
- 示例
- 低基数维度(基数1万内),建议使用LowCardinality修饰符,提升查询性能。
- 维度的基数(Cardinality):指的是该维度在数据集中出现的不同值的个数。例如“国家”是一个维度,如果有200个不同的值,那么此维度的基数就是200。
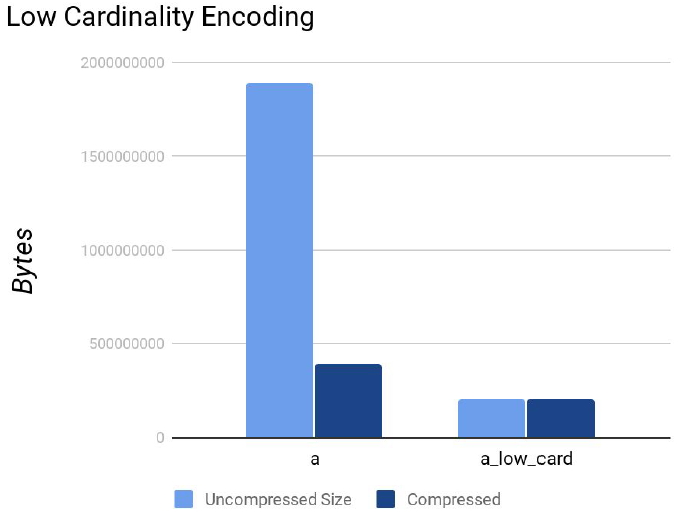
- 根据官方建议和实践经验,在维度基数小于1万的时候,对维度字段做LowCardinality编码,导入性能会有略微下降,查询性能提升明显,数据存储空间下降明显。
- 在默认的情况下,声明了LowCardinality的字段会基于数据生成一个全局字典,并利用倒排索引建立Key和位置的对应关系。如果数据的基数大于8192,也就是说不同的值多于8192个,则会将一个全局字典拆分成多个局部字典(low_cardinality_max_dictionary_size参数控制,默认8192)。
- 示例
CREATE TABLE test_codecs ON CLUSTER default_cluster ( `a` String, `a_low_card` LowCardinality(String) DEFAULT a ) ENGINE = MergeTree PARTITION BY tuple() ORDER BY tuple();
其中,字段a是原生字符串,字段a_low_card基于a做了低基维编码。
- 数据存储的对比
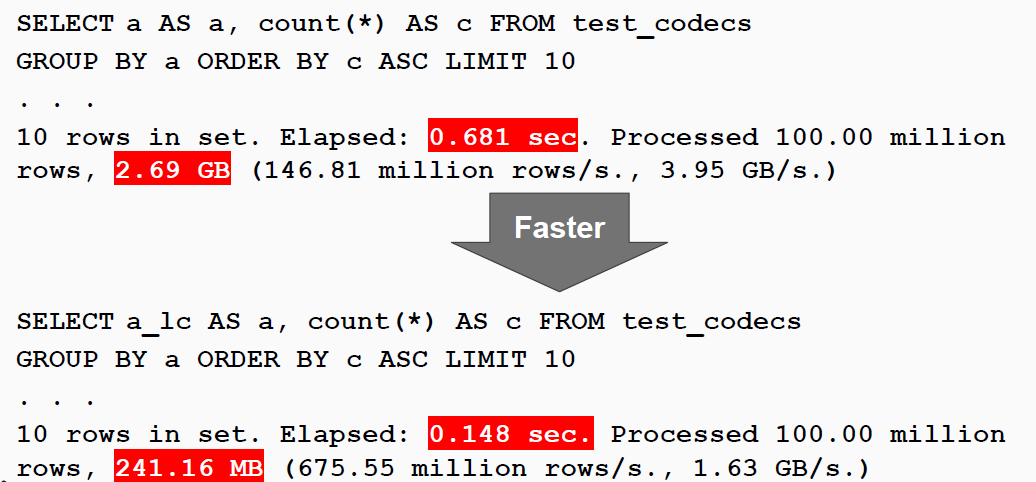
- 查询性能对比
查询性能有5倍的提升。


父主题: ClickHouse宽表设计








