

获取模型推理的Profiler 数据
PyTorch Profiler 是 PyTorch 官方提供的性能分析工具,用于深度剖析模型训练/推理过程中的性能瓶颈,帮助开发者优化计算效率、内存占用和硬件利用率。
Ascend PyTorch Profiler 完全对标 PyTorch-GPU场景下的使用方式,支持采集PyTorch层算子信息、CANN层算子信息、底层NPU算子信息、以及算子内存占用信息等,可以全方位分析PyTorch AI任务的性能状态。
然而使用PyTorch Profiler 会存在数据量大,采集接口耗时较长,性能膨胀可能导致数据不准确,结果失真等问题,为此引入轻量级性能分析工具 Service Profiler,用于分析服务请求级别的性能问题。目前 Service Profiler 通过在服务框架内部进行预埋点,可以采集到用户关注的 profile 数据。当前支持观测的能力包括服务内部请求组 batch大小、sequence length 大小以及单次 batch 迭代执行耗时等信息。
约束限制
使用Service Profiler之前先确保推理服务能正常拉起和处理请求。当前 Service Profiler 已经以 python 三方库方式集成到昇腾云版本对应的镜像中。
Ascend Pytorch Profiler 和 Service profiler均为开发态性能调优阶段使能的特性,在生产服务状态下不建议开启。使用 Ascend Pytorch Profiler 一般采集少量请求数据(一到两条请求)即可分析,Service Profiler 采集一段请求周期内(数百条或者数千条)进行分析。
检查Service Profiler工具是否安装
可以通过如下命令查看是否已经安装acs-service-profiler工具。
pip show acs-service-profiler
如果未安装,请参考以下步骤执行。
- 获取acs-service-profiler工具的whl包。
whl包存放在软件包AscendCloud-LLM-xxx.zip/AscendCloud-LLM-xxx的llm_tools目录中。软件包获取路径:Support-E,在此路径中查找下载ModelArts 6.5.907 版本。
- 配置pip源,按实际需要配置pip源。(可选)
mkdir -p ~/.pip vim ~/.pip/pip.conf
配置文件填入如下内容,下述命令以华为源为例:
[global] index-url = https://mirrors.huaweicloud.com/repository/pypi/simple trusted-host = mirrors.huaweicloud.com timeout = 120
- 在whl包所在文件夹下,执行如下命令安装acs-bench工具。
pip install acs_service_profiler-*-py3-none-any.whl

使用上述命令安装时,acs_service_profiler-*-py3-none-any.whl 中的 `*` 需替换为实际版本号,如:pip install acs_service_profiler-1.2.0-py3-none-any.whl
RestApi启停方式采集Ascend Pytorch Profiler
- 推理服务启动之前设置环境变量
export VLLM_TORCH_PROFILER_DIR=/home/ma-user/AscendCloud/profiler_dir # 开启 Ascend PyTorch Profiler
VLLM_TORCH_PROFILER_DIR 指定 profiler 数据采集目录
- 在设置完环境变量之后,拉起推理服务。
启动推理服务详细请参考启动推理服务(大语言模型)。
- 发送start profile的POST请求
curl -X POST http://${IP}:${PORT}/start_profile参数说明
- IP: 服务部署的IP地址
- PORT服务部署的端口
- 发送实际 Request
请求发送方式可参考语言模型性能测试小节。
- 发送stop profile的POST请求
curl -X POST http://${IP}:${PORT}/stop_profile参数说明同 start_profile POST 请求
- 后处理离线解析。在当前容器环境下创建 python 脚本并执行 (如 parse.py) , 脚本内容参考如下:
from torch_npu.profiler.profiler import analyse if __name__ == "__main__": analyse(profiler_path="/home/ma-user/AscendCloud/profiler_dir")其中 profiler_path 参数表示profiler 数据的采集目录,和步骤1中 VLLM_TORCH_PROFILER_DIR 环境变量指定目录为同一路径。更多离线解析能力请参考昇腾 Ascend PyTorch Profiler 离线解析。
- 后处理及可视化
Ascend PyTorch Profiler 采集数据建议使用MindStudio Insight工具可视化,可视化效果如下图。
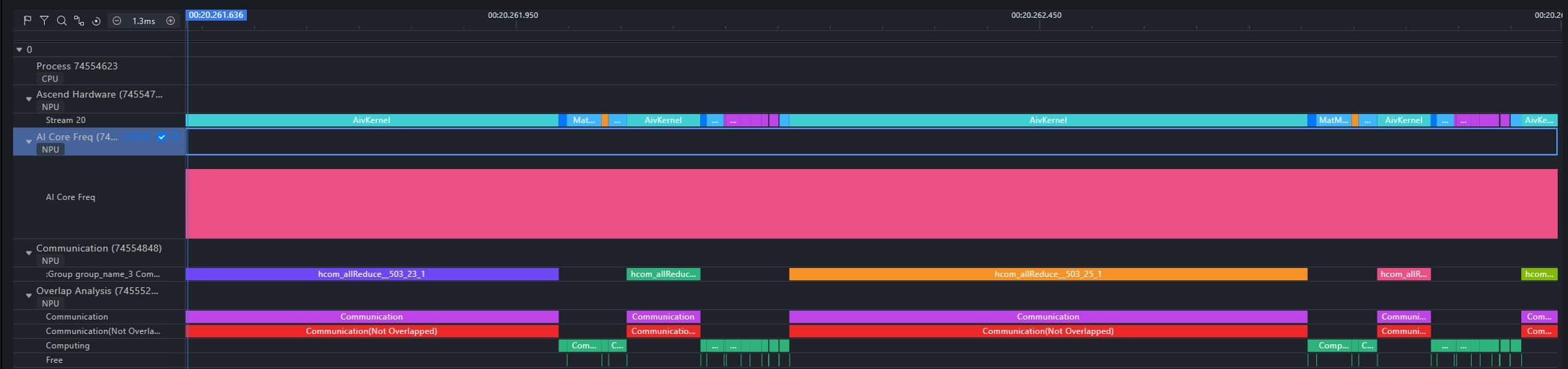
更多 MindStudio Insight 功能请参考 MindStudio Insight 工具。
Service Profiler 采集
- 推理服务启动之前设置环境变量。
export VLLM_SERVICE_PROFILER_DIR =/home/ma-user/profiler_dir # 开启 Service Profiler
VLLM_SERVICE_PROFILER_DIR指定Service pPofiler数据采集目录,注意不能和Ascend Pytorch Profiler同时开启。
- 在设置完环境变量之后,拉起推理服务。
启动推理服务详细请参考启动推理服务(大语言模型)。
- 发送start profile的POST请求
curl -X POST http://${IP}:${PORT}/start_profile参数说明
- IP: 服务部署的IP地址
- PORT服务部署的端口
- 发送实际 Request
请求发送方式可参考语言模型性能测试小节。
- 发送stop profile的POST请求
curl -X POST http://${IP}:${PORT}/stop_profile参数说明同 start_profile POST 请求
- 后处理离线解析。
后处理操作会对profiler data进行解析二次处理,支持导出服务框架的TTFT、TPOT、吞吐量等指标,同时会在文件夹目录下生成可视化文件 trace_view.json。也支持多实例下merge各个实例的timeline数据生成总体的overview_trace_view.json。生成的trace_view.json/overview_trace_view.json可拖拽到网页 chrome://tracing/或者https://ui.perfetto.dev/网页中可视化分析。
执行如下cli命令acsprof export -i ${input_path}参数说明如下表所示。
参数名称
类型
参数功能
是否必选
-i / --input_path
String
指定Service Profiler采集文件夹路径,支持父文件夹和子文件夹。
是
-o / --output_path
String
指定后处理解析文件的输出路径,默认为输入文件夹路径。
否
-f / --force_reparse
Bool
针对已经解析的文件夹是否需要强制重新解析,默认为False,表示不做强制重新解析。多批次做数据采集的场景,首次做数据采集会自动解析,后边批次的数据不会自动解析需要设置为 True 做重新解析
否
例如:
acsprof export -i /home/ma-user/profiler_dir
正常回显日志如下:

- 结果可视化。







