

投机推理使用说明
什么是投机推理
传统LLM推理主要依赖于自回归式(auto-regressive)的解码(decoding)方式,每步解码只能够产生一个输出token,并且需要将历史输出内容拼接后重新作为LLM的输入,才能进行下一步的解码。为了解决上述问题,提出了一种投机式推理方式,其核心思想是通过计算代价远低于LLM的小模型替代LLM进行投机式的推理(Speculative Inference)。即每次先使用小模型试探性地推理多步,再将这些推理结果收集到一起,一次交由LLM进行验证。
如下图所示,在投机模式下,先由小模型依次推理出token 1、2、3,并将这3个token一次性输入大模型LLM推理,得到1'、2'、3'、4',将1、2、3与1'、2'、3'依次校验,即可用三次小模型推理(相较于大模型,耗时极短),以及一次大模型推理的时间,得到1~4个token,大幅提升推理性能。
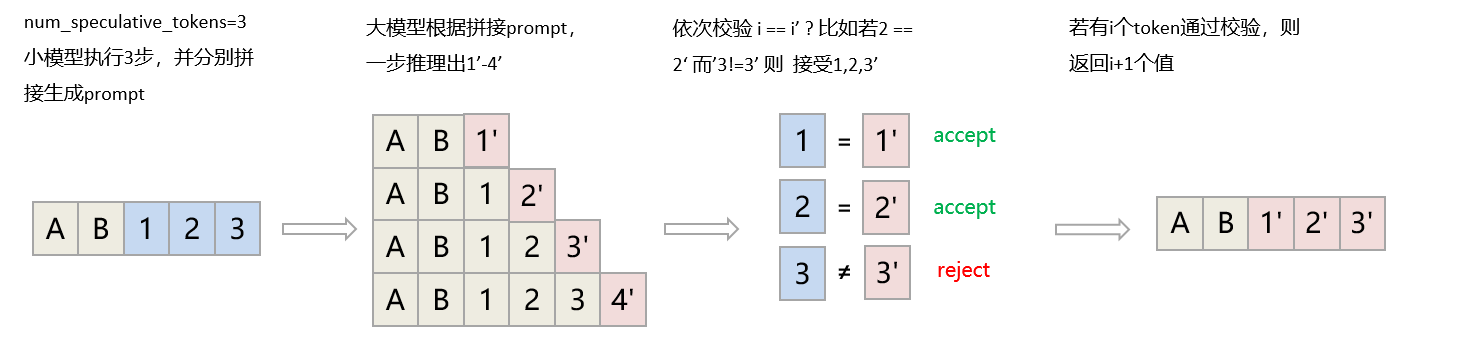
如此一来,投机推理可以带来如下优势:
更短的decode平均时间:以qwen2-72b作为LLM大模型、qwen2-0.5b作为小模型为例,小模型推理一次的时间不足大模型的1/5,加上校验后,执行一次完整投机流程的时间也仅为大模型的1.5倍左右(投机步数设置为3步)。而这一次投机流程,平均可以生成3个有效token,即用1.5倍的时间代价,生成了3倍的token数量,性能提升了100%。
投机推理参数设置
在启动离线或在线推理服务时参考表1所示配置参数,使用投机推理功能。
| 配置项 | 配置参数 | 取值类型 | 配置说明 |
|---|---|---|---|
| --speculative-config | num_speculative_tokens | int | 每次预测的 token 数量,取值为大于等于1的正整数;且若设置过大会导致性能劣化,推荐根据接受率设置1/2/3,其中推荐先设置为1,若接受率高于70%,可尝试设置为2对比性能收益。 |
| method | str | 投机方法:当前仅支持"ngram"。 | |
| prompt_lookup_min | int | 最小匹配长度,仅在method选择"ngram"的时候生效。 | |
| prompt_lookup_max | int | 最大匹配长度,仅在method选择"ngram"的时候生效。 |
投机推理端到端推理示例
以Qwen3-32B模型作为LLM大模型,启用openai接口服务为例。
- 使用下面命令启动推理服务。
base_model=/path/to/base_model export VLLM_PLUGINS=ascend_vllm export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True python -m vllm.entrypoints.openai.api_server --model=${base_model} \ --max-num-seqs=256 \ --max-model-len=8192 \ --max-num-batched-tokens=8192 \ --dtype=bfloat16 \ --tensor-parallel-size=4 \ --host=0.0.0.0 \ --port=18080 \ --gpu-memory-utilization=0.8 \ --trust-remote-code \ --additional-config='{"ascend_turbo_graph_config": {"enabled": true}}' \ --speculative-config '{"num_speculative_tokens":1,"method":"ngram","prompt_lookup_min":1,"prompt_lookup_max":8}' - curl请求
curl --request POST \ --url http://0.0.0.0:18080/v1/chat/completions \ --header 'content-type: application/json' \ --data '{ "model": "${base_model}", "messages": [ { "role": "user", "content": "现任美国总统是谁?" } ], "max_tokens": 128, "top_k": -1, "top_p": 0.1, "temperature": 0, "stream": false, "repetition_penalty": 1.0 } '
执行推理参考
- 配置服务化参数。Ascend-vLLM使用该特性需参考表1,其它参数请参考启动推理服务(大语言模型)。
- 启动服务。具体请参考启动推理服务(大语言模型)。
- 精度评测和性能评测。具体请参考推理服务精度评测和推理服务性能评测。




