

训练代码迁移
前提条件
- 要迁移的训练任务代码在GPU上多次训练稳定可收敛。训练业务代码和数据,应该确保在GPU环境中能够运行,并且训练任务有稳定的收敛效果。
- 本文只针对基于PyTorch的训练代码迁移。这里假设用户使用的是基于PyTorch的训练代码进行迁移。其他的AI引擎如TensorFlow、Caffe等不在本指导的讨论范围中。
- 已经完成环境准备(参考迁移环境准备),并且代码、预训练模型、数据等训练必需内容已经上传到环境中。
约束和限制
- 安装插件后,大部分能力能够对标在GPU上的使用,但并不是所有行为和GPU上是一一对应的,例如在torch_npu下,当PyTorch版本低于2.1.0时,一个进程只能操作一张昇腾卡,不支持一个进程操作多卡的能力,在PyTorch2.1.0及以上版本中torch_npu才支持一个进程中使用多张昇腾卡。
- 基于PyTorch上的第三方开发库非常多,例如transformers、accelerate、deepspeed以及Megatron-LM等,这些三方库昇腾也做了类似PyTorch Adapter的适配插件库,可以在Gitee的昇腾官方仓库中找到,请按需进行使用。部分三方库例如最新版本deepspeed已原生支持NPU,可以直接在昇腾设备上运行。
代码迁移基础知识
- PyTorch 2.1以下版本时,PyTorch官方并不直接支持昇腾的后端,仅直接支持CUDA和AMD ROCm,因此PyTorch在GPU上的训练代码无法直接在昇腾设备运行。PyTorch2.1版本提供了新硬件适配的插件机制,通过昇腾提供的Ascend Extension for PyTorch 插件,NPU可以成为PyTorch支持的硬件直接使用。
- Ascend Extension for PyTorch 作为一个PyTorch插件,支持在不改变PyTorch表达层的基础上,动态添加昇腾后端适配,包含增加了NPU设备、hccl等一系列能力的支持。安装后可以直接使用PyTorch的表达层来运行在NPU设备上。
- 当前提供了自动迁移工具进行GPU到昇腾适配,原理是通过monkey-patch的方式将torch下的CUDA、nccl等操作映射为NPU和hccl对应的操作。如果没有用到GPU的高阶能力,例如自定义算子、直接操作GPU显存等操作,简单场景下可以直接使用自动迁移。
图1 torch_npu工作原理示意图
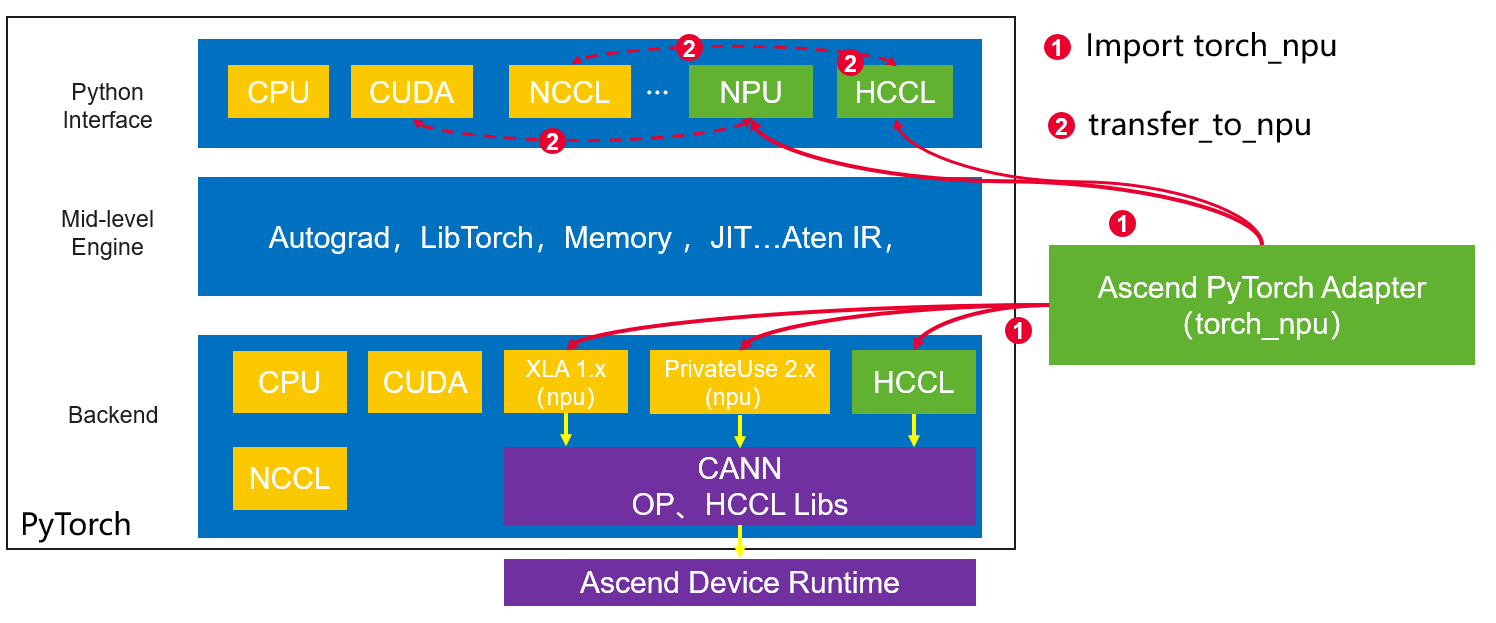
- NPU(Neural Network Processing Unit)和GPU在构造结构上存在差异,因此迁移过程并不是完全平替的关系。昇腾训练芯片属于NPU的范畴,虽然在表达层可以通过torch.cuda和torch.npu的形式来替代,但是真实的算子下发、显存管理、集合通信等存在差异,用户需要了解NPU的运行机制才能更好的使用NPU设备,同时在遇到问题时快速找到原因。
代码迁移操作步骤
- 在训练任务启动的Python脚本入口初始化Ascend Extension for PyTorch(torch_npu)。
在torch_npu安装后,该部分并没有直接植入到PyTorch中生效,需要用户显式调用。
#torch npu初始化 import torch_npu
调用后,前端会通过monkey-patch的方式注入到torch对象中,后端会注册NPU设备以及HCCL的参数面通信能力,这样就可以运行torch.npu相关接口。
图2 torch_npu导入
- 自动迁移完成GPU代码到昇腾的快速适配。
torch_npu初始化后,原则上需要用户将原来代码中CUDA相关的内容迁移到NPU相关的接口上,包含算子API、显存操作、数据集操作、分布式训练的参数面通信nccl等,手动操作修改点较多且较为分散,因此昇腾提供了自动迁移工具transfer_to_npu帮助用户快速迁移。
自动迁移的原理是:通过注入的方式将当前Python运行环境中,运行时的torch.cuda等需要适配的接口和操作都映射成为torch.npu对应的接口。所以理论上常见场景下的代码不需要额外手工适配就可以运行到昇腾设备上了。
#自动映射cuda API到npu的代码 from torch_npu.contrib import transfer_to_npu
图3 自动迁移后cuda映射为npu相关的API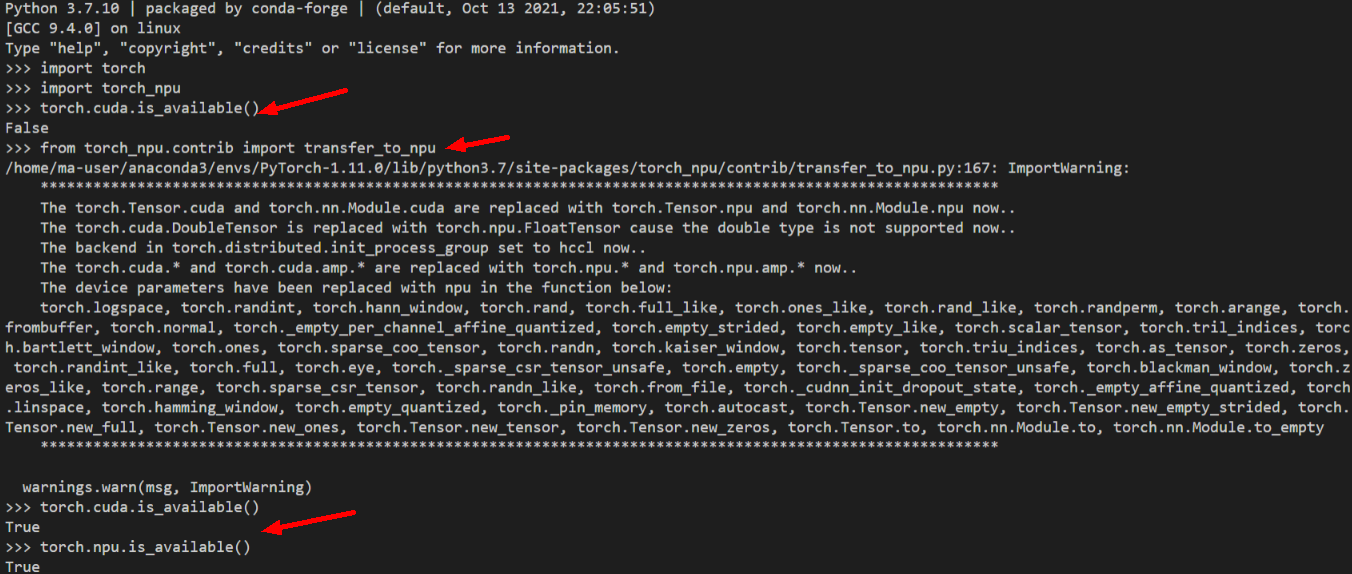
以chatGLM-6b为示例,在使用自动迁移时,在开发环境中克隆对应的代码,假设数据和预训练权重已经配置好,可以直接在ptuning目录下,训练入口代码main.py中添加两行代码来完成昇腾适配,注意添加位置为导入torch之后。启动训练脚本可以观察运行效果。
图4 chatGLM-6b pTuning训练入口导入自动迁移工具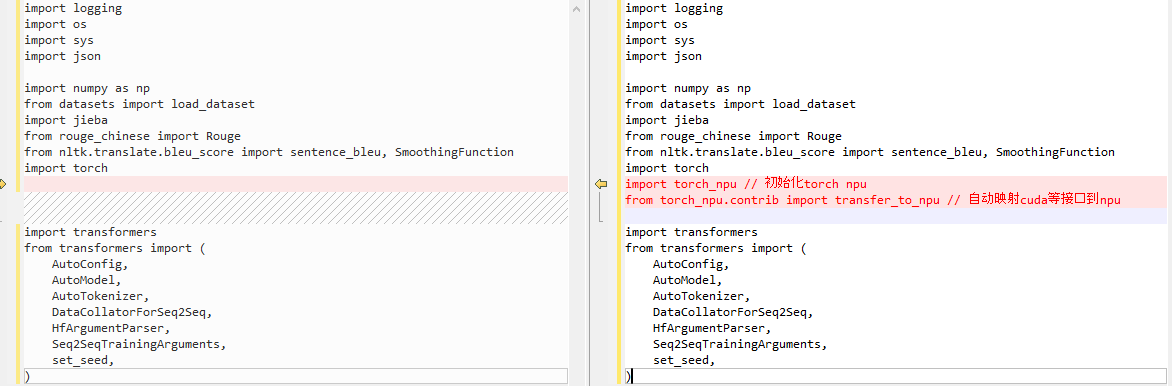

自动迁移适合没有使用CUDA高阶能力的简单场景,如果涉及自定义算子、主动申请GPU显存等操作,则需要额外进行手动迁移适配。
- 手动迁移解决报错问题。
在完成代码自动迁移后,如果训练代码运行时还出现错误,则代表需要手动迁移适配。针对代码报错处,需要用户分析定位后将自动迁移未能迁移的GPU相关的代码调用修改为NPU对应的接口,可参考昇腾手工迁移文档进行操作。
常见问题
- 如何检测当前的torch_npu是否正确安装?
可以用如下的python命令在对应的运行环境中初步校验torch_npu是否正常安装。
python3 -c "import torch;import torch_npu;print(torch_npu.npu.is_available())"
- torch_npu使用报错看不懂怎么办?应该怎么求助?
如果报错可以首先在昇腾社区论坛以及Gitee的PyTorchissues中查看是否有类似的问题找到一些线索。如果还无法解决可以通过提交工单的形式从华为云ModelArts入口来进行咨询以及求助对应的专业服务。
- 自动迁移似乎还是要改很多脚本才能运行起来?
因为自动迁移其实是对于torch运行环境中常用的GPU上的接口进行和昇腾设备的映射,原有的训练任务代码逻辑中例如数据集导入、预训练权重、GPU自定义算子的内容,以及对应的环境的超参数等内容都需要在实际的昇腾环境中进行调整。





