

SDXL基于DevServer适配MindSpore-Lite NPU推理指导(6.3.T041)
方案概览
本文档的源码是基于Stable Diffusion XL图像生成模型的开源仓进行MindSpore-Lite适配,并在ModelArts DevServer上部署,支持文生图的NPU推理场景。本文档从模型部署的环境配置、模型转换、模型推理等方面进行介绍。
本方案目前仅适用于部分企业客户,完成本方案的部署,需要先联系您所在企业的华为方技术支持。
资源规格要求
推理部署推荐使用DevServer资源和Ascend Snt9B单机单卡。
名称 |
版本 |
|---|---|
显卡 |
Snt9B |
CANN |
8.0.RC1 |
Python |
3.9.10 |
MindSpore Lite |
2.3 |
获取软件和镜像
分类 |
名称 |
获取路径 |
|---|---|---|
插件代码包 |
ascendcloud-aigc-6.3.T041-*.tar.gz 文件名中的*表示具体的时间戳,以包名的实际时间为准。 |
请联系您所在企业的华为方技术支持下载获取。 |
基础镜像Beta包 |
mindspore_2.3.0-cann_8.0.rc1-py_3.9-euler_2.10.7-aarch64-snt9b-20240422202644-39b975b.tar.partxx |
Step1 准备环境
- 请参考DevServer资源开通,购买DevServer资源,并确保机器已开通,密码已获取,能通过SSH登录,不同机器之间网络互通。

购买DevServer资源时如果无可选资源规格,需要联系华为云技术支持申请开通。
当容器需要提供服务给多个用户,或者多个用户共享使用该容器时,应限制容器访问Openstack的管理地址(169.254.169.254),以防止容器获取宿主机的元数据。具体操作请参见禁止容器获取宿主机元数据。
- 检查环境。
- SSH登录机器后,检查NPU设备检查。运行如下命令,返回NPU设备信息。
npu-smi info # 在每个实例节点上运行此命令可以看到NPU卡状态 npu-smi info -l | grep Total # 在每个实例节点上运行此命令可以看到总卡数
如出现错误,可能是机器上的NPU设备没有正常安装,或者NPU镜像被其他容器挂载。请先正常安装NPU设备和驱动,或释放被挂载的NPU。
- 检查docker是否安装。
docker -v #检查docker是否安装
如尚未安装,运行以下命令安装docker。
yum install -y docker-engine.aarch64 docker-engine-selinux.noarch docker-runc.aarch64
- 配置IP转发,用于容器内的网络访问。执行以下命令查看net.ipv4.ip_forward配置项的值,如果为1,可跳过此步骤。
sysctl -p | grep net.ipv4.ip_forward
如果net.ipv4.ip_forward配置项的值不为1,执行以下命令配置IP转发。sed -i 's/net\.ipv4\.ip_forward=0/net\.ipv4\.ip_forward=1/g' /etc/sysctl.conf sysctl -p | grep net.ipv4.ip_forward
- SSH登录机器后,检查NPU设备检查。运行如下命令,返回NPU设备信息。
- 获取基础镜像。建议使用官方提供的镜像部署推理服务,获取方式参见获取软件和镜像。
将获取到的基础镜像推到SWR上,再通过docker pull拉到容器中。
- 启动容器镜像。启动前请先按照参数说明修改${}中的参数。可以根据实际需要增加修改参数。
docker run -itd \ --device=/dev/davinci1 \ --device=/dev/davinci_manager \ --device=/dev/devmm_svm \ --device=/dev/hisi_hdc \ -v /usr/local/sbin/npu-smi:/usr/local/sbin/npu-smi \ -v /usr/local/dcmi:/usr/local/dcmi \ -v /etc/ascend_install.info:/etc/ascend_install.info \ -v /sys/fs/cgroup:/sys/fs/cgroup:ro \ -v /usr/local/Ascend/driver:/usr/local/Ascend/driver \ --shm-size 32g \ --net=host \ -v ${work_dir}:${container_work_dir} \ --name ${container_name} \ ${image_name} bash参数说明:
- -v ${work_dir}:${container_work_dir} 容器挂载宿主机目录,work_dir代表宿主机上的目录,container_work_dir代表挂载至容器中的工作目录,将解压后的代码放在宿主机工作目录下并挂载至容器内。由于此镜像的/home/ma-user为用户家目录,不要将容器内/home目录替换掉。
- --name ${container_name} 容器名称,进入容器时会用到,此处可以自己定义一个容器名称。
- --device=/dev/davinci1:1为卡号,具体使用哪张卡视情况而定,选择空闲卡号即可。卡是否空闲可在创建容器后进入容器执行npu-smi info命令查看。
- 进入容器。需要将${container_name}替换为实际的容器名称。
docker exec -it ${container_name} bash
Step2 安装模型插件代码包
cd /home/ma-user/ mkdir sdxl_ms cd sdxl_ms/ tar -zxvf ascendcloud-aigc-6.3.T041-*.tar.gz tar -zxvf ascendcloud-aigc-poc-sdxl_ms.tar.gz rm -rf ascendcloud-aigc-6.3.T041-*
ascendcloud-aigc-6.3.T041-*.tar.gz后面的*表示时间戳,请按照实际替换。
/home/ma-user/sdxl_ms路径下的文件如下图所示。
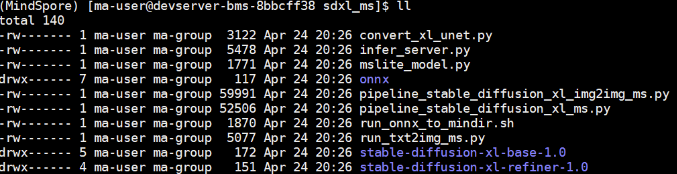
Step3 下载原始模型
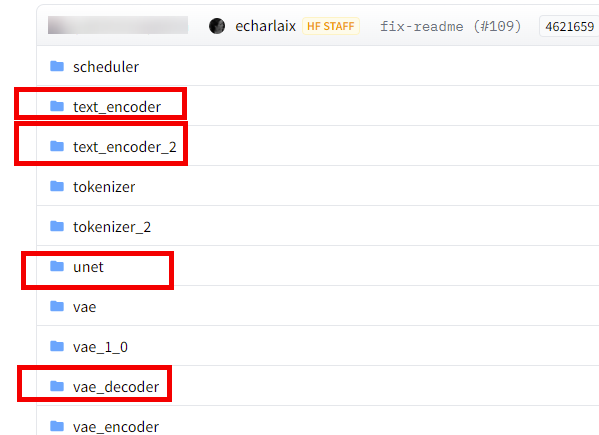
SDXL主要涉及5个模型,分别是text_encoder,text_encoder2,unet,unet2和vae_decoder。这里unet2表示refiner line下的unet模型。除了unet2,其他模型都可以从HuggingFace网站直接下载到onnx模型文件。
- 下载text_encoder,text_encoder2,unet和vae_decoder模型。下载地址:stable-diffusion-xl-base-1.0,下载如图2所示4个文件。
- 将下载的模型放到/home/ma-user/sdxl_ms/onnx的对应文件夹中,容器内外文件拷贝的命令参考如下。
docker cp model.onnx container_name:/home/ma-user/sdxl_ms/onnx/text_encoder/
拷贝完模型文件后目录结构如下所示
/home/ma-user/sdxl_ms/onnx / |- || text_encoder |-- config.ini |-- config.json |-- model.onnx |- || text_encoder2 |-- config.ini |-- config.json |-- model.onnx |-- model.onnx_data |- || unet |-- config.ini |-- config.json |-- model.onnx |-- model.onnx_data |- || unet_2 |-- config.ini |-- config.json |- || vae_decoder |-- config.ini |-- config.json |-- model.onnx - 下载unet2模型。这里unet2表示refiner line下的unet模型。下载地址:stable-diffusion-xl-refiner-1.0。这里需要把整个stable-diffusion-xl-refiner-1.0模型文件下载下来,可以在sdxl_ms下创建一个temp文件夹,将下载好的stable-diffusion-xl-refiner-1.0模型文件拷贝到temp文件夹中。
由于启动容器时默认用户为ma-user用户。如果需要切换到root用户可以执行以下命令:
sudo su source /home/ma-user/.bashrc
如果继续使用ma-user,在使用其他属组如root用户上传的数据和文件时,可能会存在权限不足的问题,因此需要执行如下命令统一文件属主。
sudo chown -R ma-user:ma-group ${container_work_dir} # ${container_work_dir}:/home/ma-user/ws 容器内挂载的目录例如:
sudo chown -R ma-user:ma-group /home/ma-user/ws
- unet_2转换。unet2模型使用前需要先转换为onnx文件。
- 进入temp文件夹,将/home/ma-user/sdxl_ms/convert_xl_unet.py复制到文件夹中。
cd temp/ cp ../convert_xl_unet.py ./
- 修改转换脚本convert_xl_unet.py第63行为如下内容并保存。
unet_path = "./unet.onnx"
- 安装依赖。
pip install transformers torch diffusers
- 执行转换脚本。
python convert_xl_unet.py
转换完成后在temp文件夹下有如下文件。
图3 转换后的unet2模型文件
- 将上图中的两个文件unet.onnx和weights.pb都复制到/home/ma-user/sdxl_ms/onnx/unet_2文件夹中,并修改unet.onnx为model.onnx,最终onnx文件夹的目录结构如下:
/home/ma-user/sdxl_ms/onnx / |- || text_encoder |-- config.ini |-- config.json |-- model.onnx |- || text_encoder2 |-- config.ini |-- config.json |-- model.onnx |-- model.onnx_data |- || unet |-- config.ini |-- config.json |-- model.onnx |-- model.onnx_data |- || unet_2 |-- config.ini |-- config.json |-- model.onnx |-- weights.pb |- || vae_decoder |-- config.ini |-- config.json |-- model.onnx
- 进入temp文件夹,将/home/ma-user/sdxl_ms/convert_xl_unet.py复制到文件夹中。
Step4 模型转换
- 在进行模型转换前,需先设置环境变量。
cd /home/ma-user/sdxl_ms export LITE_HOME=/usr/local/mindspore-lite/mindspore-lite-2.3.0rc1-linux-aarch64 export LD_LIBRARY_PATH=$LITE_HOME/runtime/lib:$LITE_HOME/runtime/third_party/dnnl:$LITE_HOME/tools/converter/lib:$LD_LIBRARY_PATH export PATH=$LITE_HOME/tools/converter/converter:$LITE_HOME/tools/benchmark:$PATH
- 修改模型转换脚本。
模型转换的脚本是/home/ma-user/sdxl_ms/run_onnx_to_mindir.sh,脚本内容如下,请根据实际情况修改。
图4 修改模型转换脚本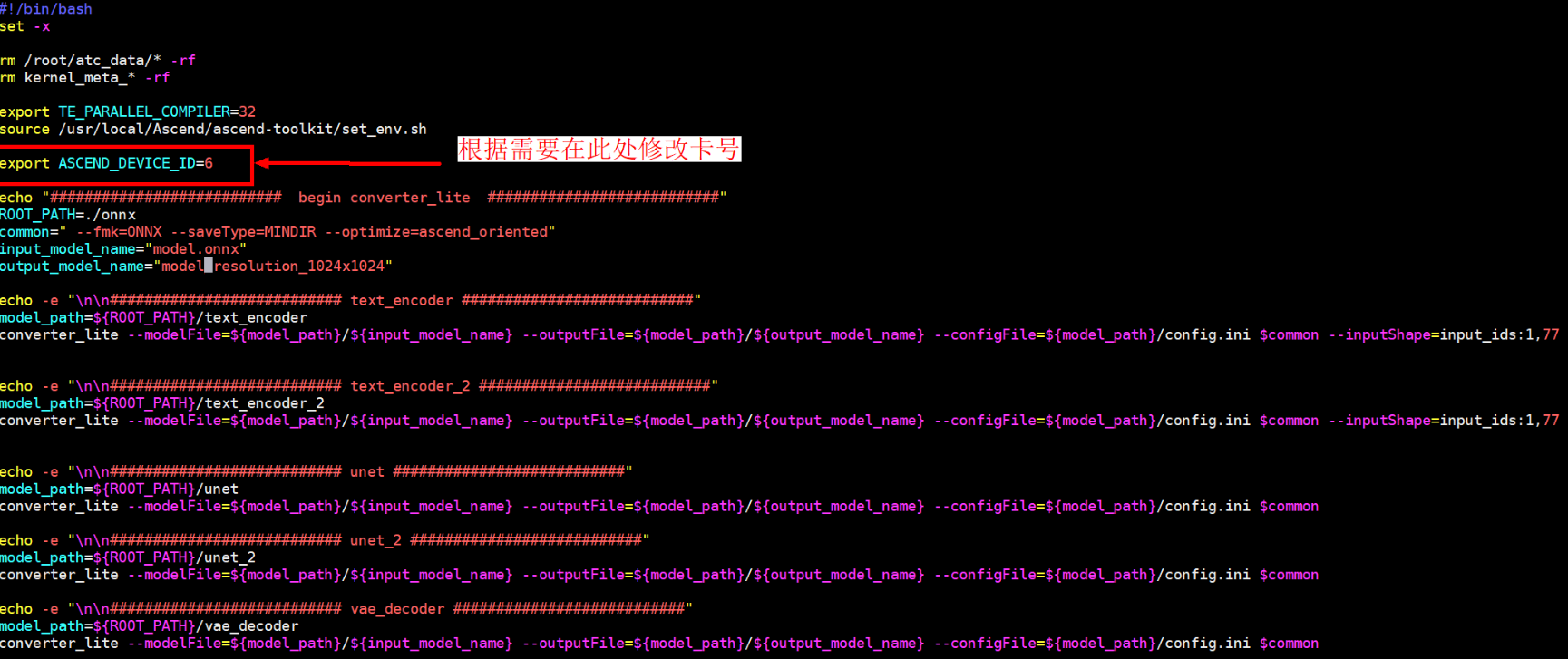
这里提供的模型适配包支持5种分档位图片大小,分别是512x512 768x768 960x960 1024x1024 1280x1280
- 执行如下命令转换模型。
sh run_onnx_to_mindir.sh
出现CONVERT RESULT SUCCESS:0即为转模型成功,这里会自动依次转换5个模型。转换时间较长(大约35min),请耐心等待。
Step5 模型推理
- 先在/home/ma-user/sdxl_ms下面创建outputs文件夹。
mkdir outputs
- 运行/home/ma-user/sdxl_ms路径下的run_txt2img_ms.py进行本地验证。
python run_txt2img_ms.py
最后会打印pipeline推理时间,并且在outputs文件夹下会生成图片。
图5 打印推理时间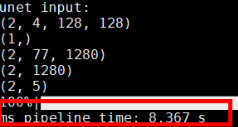 图6 生成图片
图6 生成图片
也可通过在python run_txt2img_ms.py后加上相应参数进行测试,如
python run_txt2img_ms.py --height 512 --width 512
可选参数:
--prompt "在这里写提示词,请用英文"
--num_inference_stepsunet模型执行步数,默认50
--height图片高,默认为1024
--width图片宽,默认1024
--scheduler调度算法,默认为DDIM
--seed随机种子,默认为42
- 安装依赖。
pip install flask
- 启动服务。
运行/home/ma-user/sdxl_ms路径下的infer_server.py部署推理服务。
python infer_server.py
服务启动成功显示如下。
图7 服务启动成功
Step6 使用Python脚本进行测试
使用python脚本进行测试,脚本内容如下。
# coding=utf-8
import requests
import base64
import os
from io import BytesIO
from PIL import Image
def base64_to_image(base64_str):
image = base64.b64decode(base64_str, altchars=None, validate=False)
image = BytesIO(image)
image = Image.open(image)
image.save(os.path.join("./outputs","output_img.png"))
if __name__ == '__main__':
# Config url, token and file path
url = "http://localhost:8446"
# Set body,then send request
headers = {
'Content-Type':'application/json'
}
body = {
"prompt": "a tiger sleep under the tree",
"height": 512,
"width": 512
}
resp = requests.post(url, headers=headers, json=body)
# Print result
#print(resp.content)
base64_to_image(resp.content)
将该脚本内容编辑成test.py文件并运行,服务端会打印推理时间,并在outputs文件夹下生成对应图片,打开图片查看效果。
python test.py








