示例:从0到1制作自定义镜像并用于训练(Horovod-PyTorch+GPU)
本章节介绍如何从0到1制作镜像,并使用该镜像在ModelArts平台上进行训练。镜像中使用的AI引擎是Horovod 0.22.1 + PyTorch 1.8.1,训练使用的资源是GPU。

本实践教程仅适用于新版训练作业。
场景描述
本示例使用Linux x86_64架构的主机,操作系统ubuntu-18.04,通过编写Dockerfile文件制作自定义镜像。
目标:构建安装如下软件的容器镜像,并在ModelArts平台上使用CPU/GPU规格资源运行训练任务。
- ubuntu-18.04
- cuda-11.1
- python-3.7.13
- mlnx ofed-5.4
- pytorch-1.8.1
- horovod-0.22.1
操作流程
使用自定义镜像创建训练作业时,需要您熟悉docker软件的使用,并具备一定的开发经验。详细步骤如下所示:
Step1 创建OBS桶和文件夹
在OBS服务中创建桶和文件夹,用于存放样例数据集以及训练代码。需要创建的文件夹列表如表1所示,示例中的桶名称“test-modelarts”和文件夹名称均为举例,请替换为用户自定义的名称。
请确保您使用的OBS与ModelArts在同一区域。
Step2 准备训练脚本并上传至OBS
准备本案例所需的训练脚本pytorch_synthetic_benchmark.py和run_mpi.sh文件,并上传至OBS桶的“obs://test-modelarts/horovod/demo-code/”文件夹下。
pytorch_synthetic_benchmark.py文件内容如下:
import argparse
import torch.backends.cudnn as cudnn
import torch.nn.functional as F
import torch.optim as optim
import torch.utils.data.distributed
from torchvision import models
import horovod.torch as hvd
import timeit
import numpy as np
# Benchmark settings
parser = argparse.ArgumentParser(description='PyTorch Synthetic Benchmark',
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--fp16-allreduce', action='store_true', default=False,
help='use fp16 compression during allreduce')
parser.add_argument('--model', type=str, default='resnet50',
help='model to benchmark')
parser.add_argument('--batch-size', type=int, default=32,
help='input batch size')
parser.add_argument('--num-warmup-batches', type=int, default=10,
help='number of warm-up batches that don\'t count towards benchmark')
parser.add_argument('--num-batches-per-iter', type=int, default=10,
help='number of batches per benchmark iteration')
parser.add_argument('--num-iters', type=int, default=10,
help='number of benchmark iterations')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--use-adasum', action='store_true', default=False,
help='use adasum algorithm to do reduction')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
hvd.init()
if args.cuda:
# Horovod: pin GPU to local rank.
torch.cuda.set_device(hvd.local_rank())
cudnn.benchmark = True
# Set up standard model.
model = getattr(models, args.model)()
# By default, Adasum doesn't need scaling up learning rate.
lr_scaler = hvd.size() if not args.use_adasum else 1
if args.cuda:
# Move model to GPU.
model.cuda()
# If using GPU Adasum allreduce, scale learning rate by local_size.
if args.use_adasum and hvd.nccl_built():
lr_scaler = hvd.local_size()
optimizer = optim.SGD(model.parameters(), lr=0.01 * lr_scaler)
# Horovod: (optional) compression algorithm.
compression = hvd.Compression.fp16 if args.fp16_allreduce else hvd.Compression.none
# Horovod: wrap optimizer with DistributedOptimizer.
optimizer = hvd.DistributedOptimizer(optimizer,
named_parameters=model.named_parameters(),
compression=compression,
op=hvd.Adasum if args.use_adasum else hvd.Average)
# Horovod: broadcast parameters & optimizer state.
hvd.broadcast_parameters(model.state_dict(), root_rank=0)
hvd.broadcast_optimizer_state(optimizer, root_rank=0)
# Set up fixed fake data
data = torch.randn(args.batch_size, 3, 224, 224)
target = torch.LongTensor(args.batch_size).random_() % 1000
if args.cuda:
data, target = data.cuda(), target.cuda()
def benchmark_step():
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
def log(s, nl=True):
if hvd.rank() != 0:
return
print(s, end='\n' if nl else '')
log('Model: %s' % args.model)
log('Batch size: %d' % args.batch_size)
device = 'GPU' if args.cuda else 'CPU'
log('Number of %ss: %d' % (device, hvd.size()))
# Warm-up
log('Running warmup...')
timeit.timeit(benchmark_step, number=args.num_warmup_batches)
# Benchmark
log('Running benchmark...')
img_secs = []
for x in range(args.num_iters):
time = timeit.timeit(benchmark_step, number=args.num_batches_per_iter)
img_sec = args.batch_size * args.num_batches_per_iter / time
log('Iter #%d: %.1f img/sec per %s' % (x, img_sec, device))
img_secs.append(img_sec)
# Results
img_sec_mean = np.mean(img_secs)
img_sec_conf = 1.96 * np.std(img_secs)
log('Img/sec per %s: %.1f +-%.1f' % (device, img_sec_mean, img_sec_conf))
log('Total img/sec on %d %s(s): %.1f +-%.1f' %
(hvd.size(), device, hvd.size() * img_sec_mean, hvd.size() * img_sec_conf))
run_mpi.sh文件内容如下:
#!/bin/bash
MY_HOME=/home/ma-user
MY_SSHD_PORT=${MY_SSHD_PORT:-"36666"}
MY_MPI_BTL_TCP_IF=${MY_MPI_BTL_TCP_IF:-"eth0,bond0"}
MY_TASK_INDEX=${MA_TASK_INDEX:-${VC_TASK_INDEX:-${VK_TASK_INDEX}}}
MY_MPI_SLOTS=${MY_MPI_SLOTS:-"${MA_NUM_GPUS}"}
MY_MPI_TUNE_FILE="${MY_HOME}/env_for_user_process"
if [ -z ${MY_MPI_SLOTS} ]; then
echo "[run_mpi] MY_MPI_SLOTS is empty, set it be 1"
MY_MPI_SLOTS="1"
fi
printf "MY_HOME: ${MY_HOME}\nMY_SSHD_PORT: ${MY_SSHD_PORT}\nMY_MPI_BTL_TCP_IF: ${MY_MPI_BTL_TCP_IF}\nMY_TASK_INDEX: ${MY_TASK_INDEX}\nMY_MPI_SLOTS: ${MY_MPI_SLOTS}\n"
env | grep -E '^MA_|SHARED_|^S3_|^PATH|^VC_WORKER_|^SCC|^CRED' | grep -v '=$' > ${MY_MPI_TUNE_FILE}
# add -x to each line
sed -i 's/^/-x /' ${MY_MPI_TUNE_FILE}
sed -i "s|{{MY_SSHD_PORT}}|${MY_SSHD_PORT}|g" ${MY_HOME}/etc/ssh/sshd_config
# start sshd service
bash -c "$(which sshd) -f ${MY_HOME}/etc/ssh/sshd_config"
# confirm the sshd is up
netstat -anp | grep LIS | grep ${MY_SSHD_PORT}
if [ $MY_TASK_INDEX -eq 0 ]; then
# generate the hostfile of mpi
for ((i=0; i<$MA_NUM_HOSTS; i++))
do
eval hostname=${MA_VJ_NAME}-${MA_TASK_NAME}-${i}.${MA_VJ_NAME}
echo "[run_mpi] hostname: ${hostname}"
ip=""
while [ -z "$ip" ]; do
ip=$(ping -c 1 ${hostname} | grep "PING" | sed -E 's/PING .* .([0-9.]+). .*/\1/g')
sleep 1
done
echo "[run_mpi] resolved ip: ${ip}"
# test the sshd is up
while :
do
if [ cat < /dev/null >/dev/tcp/${ip}/${MY_SSHD_PORT} ]; then
break
fi
sleep 1
done
echo "[run_mpi] the sshd of ip ${ip} is up"
echo "${ip} slots=$MY_MPI_SLOTS" >> ${MY_HOME}/hostfile
done
printf "[run_mpi] hostfile:\n`cat ${MY_HOME}/hostfile`\n"
fi
RET_CODE=0
if [ $MY_TASK_INDEX -eq 0 ]; then
echo "[run_mpi] start exec command time: "$(date +"%Y-%m-%d-%H:%M:%S")
np=$(( ${MA_NUM_HOSTS} * ${MY_MPI_SLOTS} ))
echo "[run_mpi] command: mpirun -np ${np} -hostfile ${MY_HOME}/hostfile -mca plm_rsh_args \"-p ${MY_SSHD_PORT}\" -tune ${MY_MPI_TUNE_FILE} ... $@"
# execute mpirun at worker-0
# mpirun
mpirun \
-np ${np} \
-hostfile ${MY_HOME}/hostfile \
-mca plm_rsh_args "-p ${MY_SSHD_PORT}" \
-tune ${MY_MPI_TUNE_FILE} \
-bind-to none -map-by slot \
-x NCCL_DEBUG=INFO -x NCCL_SOCKET_IFNAME=${MY_MPI_BTL_TCP_IF} -x NCCL_SOCKET_FAMILY=AF_INET \
-x HOROVOD_MPI_THREADS_DISABLE=1 \
-x LD_LIBRARY_PATH \
-mca pml ob1 -mca btl ^openib -mca plm_rsh_no_tree_spawn true \
"$@"
RET_CODE=$?
if [ $RET_CODE -ne 0 ]; then
echo "[run_mpi] exec command failed, exited with $RET_CODE"
else
echo "[run_mpi] exec command successfully, exited with $RET_CODE"
fi
# stop 1...N worker by killing the sleep proc
sed -i '1d' ${MY_HOME}/hostfile
if [ `cat ${MY_HOME}/hostfile | wc -l` -ne 0 ]; then
echo "[run_mpi] stop 1 to (N - 1) worker by killing the sleep proc"
sed -i 's/${MY_MPI_SLOTS}/1/g' ${MY_HOME}/hostfile
printf "[run_mpi] hostfile:\n`cat ${MY_HOME}/hostfile`\n"
mpirun \
--hostfile ${MY_HOME}/hostfile \
--mca btl_tcp_if_include ${MY_MPI_BTL_TCP_IF} \
--mca plm_rsh_args "-p ${MY_SSHD_PORT}" \
-x PATH -x LD_LIBRARY_PATH \
pkill sleep \
> /dev/null 2>&1
fi
echo "[run_mpi] exit time: "$(date +"%Y-%m-%d-%H:%M:%S")
else
echo "[run_mpi] the training log is in worker-0"
sleep 365d
echo "[run_mpi] exit time: "$(date +"%Y-%m-%d-%H:%M:%S")
fi
exit $RET_CODE
Step3 准备镜像主机
准备一台Linux x86_64架构的主机,操作系统使用ubuntu-18.04。您可以准备相同规格的弹性云服务器ECS或者应用本地已有的主机进行自定义镜像的制作。
购买ECS服务器的具体操作请参考购买并登录Linux弹性云服务器。“CPU架构”选择“x86计算”,“镜像”选择“公共镜像”,推荐使用Ubuntu18.04的镜像。
Step4 制作自定义镜像
目标:构建安装好如下软件的容器镜像,并使用ModelArts训练服务运行。
- ubuntu-18.04
- cuda-11.1
- python-3.7.13
- mlnx ofed-5.4
- pytorch-1.8.1
- horovod-0.22.1
此处介绍如何通过编写Dockerfile文件制作自定义镜像的操作步骤。
- 安装Docker。
以Linux x86_64架构的操作系统为例,获取Docker安装包。您可以使用以下指令安装Docker。关于安装Docker的更多指导内容参见Docker官方文档。
curl -fsSL get.docker.com -o get-docker.sh sh get-docker.sh
如果docker images命令可以执行成功,表示Docker已安装,此步骤可跳过。
- 确认Docker Engine版本。执行如下命令。
docker version | grep -A 1 Engine
命令回显如下。Engine: Version: 18.09.0
推荐使用大于等于该版本的Docker Engine来制作自定义镜像。
- 准备名为context的文件夹。
mkdir -p context
- 准备可用的pip源文件pip.conf。本示例使用华为开源镜像站提供的pip源,其pip.conf文件内容如下。
[global] index-url = https://repo.huaweicloud.com/repository/pypi/simple trusted-host = repo.huaweicloud.com timeout = 120
在华为开源镜像站https://mirrors.huaweicloud.com/home中,搜索pypi,也可以查看pip.conf文件内容。
- 下载horovod源码文件。
进入网站https://pypi.org/project/horovod/0.22.1/#files,下载horovod-0.22.1.tar.gz文件。
- 下载torch*.whl文件。
在网站https://download.pytorch.org/whl/torch_stable.html搜索并下载如下whl文件。
- torch-1.8.1+cu111-cp37-cp37m-linux_x86_64.whl
- torchaudio-0.8.1-cp37-cp37m-linux_x86_64.whl
- torchvision-0.9.1+cu111-cp37-cp37m-linux_x86_64.whl
“+”符号的URL编码为“%2B”;在上述网站中搜索目标文件名时,需要将原文件名中的“+”符号替换为“%2B”。
例如“torch-1.8.1%2Bcu111-cp37-cp37m-linux_x86_64.whl”。
- 下载Miniconda3安装文件。
使用地址https://repo.anaconda.com/miniconda/Miniconda3-py37_4.12.0-Linux-x86_64.sh,下载Miniconda3 py37 4.12.0安装文件(对应python 3.7.13)。
- 编写容器镜像Dockerfile文件。
在context文件夹内新建名为Dockerfile的空文件,并将下述内容写入其中。
# 容器镜像构建主机需要连通公网 # 基础容器镜像, https://github.com/NVIDIA/nvidia-docker/wiki/CUDA # # https://docs.docker.com/develop/develop-images/multistage-build/#use-multi-stage-builds # require Docker Engine >= 17.05 # # builder stage FROM nvidia/cuda:11.1.1-devel-ubuntu18.04 AS builder # 安装 cmake 工具(使用华为开源镜像站) RUN cp -a /etc/apt/sources.list /etc/apt/sources.list.bak && \ sed -i "s@http://.*archive.ubuntu.com@http://repo.huaweicloud.com@g" /etc/apt/sources.list && \ sed -i "s@http://.*security.ubuntu.com@http://repo.huaweicloud.com@g" /etc/apt/sources.list && \ echo > /etc/apt/apt.conf.d/00skip-verify-peer.conf "Acquire { https::Verify-Peer false }" && \ apt-get update && \ apt-get install -y build-essential cmake g++-7 && \ apt-get clean && \ mv /etc/apt/sources.list.bak /etc/apt/sources.list && \ rm /etc/apt/apt.conf.d/00skip-verify-peer.conf # 基础容器镜像的默认用户已经是 root # USER root # 使用华为开源镜像站提供的 pypi 配置 RUN mkdir -p /root/.pip/ COPY pip.conf /root/.pip/pip.conf # 复制待安装文件到基础容器镜像中的 /tmp 目录 COPY Miniconda3-py37_4.12.0-Linux-x86_64.sh /tmp COPY torch-1.8.1+cu111-cp37-cp37m-linux_x86_64.whl /tmp COPY torchvision-0.9.1+cu111-cp37-cp37m-linux_x86_64.whl /tmp COPY torchaudio-0.8.1-cp37-cp37m-linux_x86_64.whl /tmp COPY openmpi-3.0.0-bin.tar.gz /tmp COPY horovod-0.22.1.tar.gz /tmp # https://conda.io/projects/conda/en/latest/user-guide/install/linux.html#installing-on-linux # 安装 Miniconda3 到基础容器镜像的 /home/ma-user/miniconda3 目录中 RUN bash /tmp/Miniconda3-py37_4.12.0-Linux-x86_64.sh -b -p /home/ma-user/miniconda3 # 安装 horovod v0.22.1 已经编译好的 openmpi 3.0.0 文件 # https://github.com/horovod/horovod/blob/v0.22.1/docker/horovod/Dockerfile # https://github.com/horovod/horovod/files/1596799/openmpi-3.0.0-bin.tar.gz RUN cd /usr/local && \ tar -zxf /tmp/openmpi-3.0.0-bin.tar.gz && \ ldconfig && \ mpirun --version # 编译 Horovod with PyTorch 所需的环境变量 ENV HOROVOD_NCCL_INCLUDE=/usr/include \ HOROVOD_NCCL_LIB=/usr/lib/x86_64-linux-gnu \ HOROVOD_MPICXX_SHOW="/usr/local/openmpi/bin/mpicxx -show" \ HOROVOD_GPU_OPERATIONS=NCCL \ HOROVOD_WITH_PYTORCH=1 # 使用 Miniconda3 默认 python 环境 (即 /home/ma-user/miniconda3/bin/pip) 安装 torch*.whl RUN cd /tmp && \ /home/ma-user/miniconda3/bin/pip install --no-cache-dir \ /tmp/torch-1.8.1+cu111-cp37-cp37m-linux_x86_64.whl \ /tmp/torchvision-0.9.1+cu111-cp37-cp37m-linux_x86_64.whl \ /tmp/torchaudio-0.8.1-cp37-cp37m-linux_x86_64.whl # 使用 Miniconda3 默认 python 环境 (即 /home/ma-user/miniconda3/bin/pip) 编译安装 horovod-0.22.1.tar.gz RUN cd /tmp && \ /home/ma-user/miniconda3/bin/pip install --no-cache-dir \ /tmp/horovod-0.22.1.tar.gz # 构建最终容器镜像 FROM nvidia/cuda:11.1.1-runtime-ubuntu18.04 COPY MLNX_OFED_LINUX-5.4-3.5.8.0-ubuntu18.04-x86_64.tgz /tmp # 安装 vim / curl / net-tools / mlnx ofed / ssh 工具(依然使用华为开源镜像站) RUN cp -a /etc/apt/sources.list /etc/apt/sources.list.bak && \ sed -i "s@http://.*archive.ubuntu.com@http://repo.huaweicloud.com@g" /etc/apt/sources.list && \ sed -i "s@http://.*security.ubuntu.com@http://repo.huaweicloud.com@g" /etc/apt/sources.list && \ echo > /etc/apt/apt.conf.d/00skip-verify-peer.conf "Acquire { https::Verify-Peer false }" && \ apt-get update && \ apt-get install -y vim curl net-tools iputils-ping libfile-find-rule-perl-perl \ openssh-client openssh-server && \ ssh -V && \ mkdir -p /run/sshd && \ # mlnx ofed apt-get install -y python libfuse2 dpatch libnl-3-dev autoconf libnl-route-3-dev pciutils libnuma1 libpci3 m4 libelf1 debhelper automake graphviz bison lsof kmod libusb-1.0-0 swig libmnl0 autotools-dev flex chrpath libltdl-dev && \ cd /tmp && \ tar -xvf MLNX_OFED_LINUX-5.4-3.5.8.0-ubuntu18.04-x86_64.tgz && \ MLNX_OFED_LINUX-5.4-3.5.8.0-ubuntu18.04-x86_64/mlnxofedinstall --user-space-only --basic --without-fw-update -q && \ cd - && \ rm -rf /tmp/* && \ apt-get clean && \ mv /etc/apt/sources.list.bak /etc/apt/sources.list && \ rm /etc/apt/apt.conf.d/00skip-verify-peer.conf # 安装 horovod v0.22.1 已经编译好的 openmpi 3.0.0 文件 # https://github.com/horovod/horovod/blob/v0.22.1/docker/horovod/Dockerfile # https://github.com/horovod/horovod/files/1596799/openmpi-3.0.0-bin.tar.gz COPY openmpi-3.0.0-bin.tar.gz /tmp RUN cd /usr/local && \ tar -zxf /tmp/openmpi-3.0.0-bin.tar.gz && \ ldconfig && \ mpirun --version # 增加 ma-user 用户 (uid = 1000, gid = 100) # 注意到基础容器镜像已存在 gid = 100 的组,因此 ma-user 用户可直接使用 RUN useradd -m -d /home/ma-user -s /bin/bash -g 100 -u 1000 ma-user # 从上述 builder stage 中复制 /home/ma-user/miniconda3 目录到当前容器镜像的同名目录 COPY --chown=ma-user:100 --from=builder /home/ma-user/miniconda3 /home/ma-user/miniconda3 # 设置容器镜像默认用户与工作目录 USER ma-user WORKDIR /home/ma-user # 配置 sshd,使得 ssh 可以免密登录 RUN MA_HOME=/home/ma-user && \ # setup sshd dir mkdir -p ${MA_HOME}/etc && \ ssh-keygen -f ${MA_HOME}/etc/ssh_host_rsa_key -N '' -t rsa && \ mkdir -p ${MA_HOME}/etc/ssh ${MA_HOME}/var/run && \ # setup sshd config (listen at {{MY_SSHD_PORT}} port) echo "Port {{MY_SSHD_PORT}}\n\ HostKey ${MA_HOME}/etc/ssh_host_rsa_key\n\ AuthorizedKeysFile ${MA_HOME}/.ssh/authorized_keys\n\ PidFile ${MA_HOME}/var/run/sshd.pid\n\ StrictModes no\n\ UsePAM no" > ${MA_HOME}/etc/ssh/sshd_config && \ # generate ssh key ssh-keygen -t rsa -f ${MA_HOME}/.ssh/id_rsa -P '' && \ cat ${MA_HOME}/.ssh/id_rsa.pub >> ${MA_HOME}/.ssh/authorized_keys && \ # disable ssh host key checking for all hosts echo "Host *\n\ StrictHostKeyChecking no" > ${MA_HOME}/.ssh/config # 设置容器镜像预置环境变量 # 请务必设置 PYTHONUNBUFFERED=1, 以免日志丢失 ENV PATH=/home/ma-user/miniconda3/bin:$PATH \ PYTHONUNBUFFERED=1关于Dockerfile文件编写的更多指导内容参见Docker 官方文档。
- 下载MLNX_OFED安装包。
进入地址,单击“Download”,在“Current Versions”和“Archive Versions”中选择合适的安装包下载。本文示例中选择“Archive Versions”,“Version”选择“5.4-3.5.8.0-LTS”,“OS Distribution”选择“Ubuntu”,“OS Distribution Version”选择“Ubuntu 18.04”,“Architecture”选择“x86_64”,下载MLNX_OFED_LINUX-5.4-3.5.8.0-ubuntu18.04-x86_64.tgz。
- 下载openmpi-3.0.0-bin.tar.gz。
使用地址https://github.com/horovod/horovod/files/1596799/openmpi-3.0.0-bin.tar.gz,下载openmpi-3.0.0-bin.tar.gz文件。
- 将上述pip源文件、torch*.whl文件、Miniconda3安装文件等放置在context文件夹内,context文件夹内容如下。
context ├── Dockerfile ├── MLNX_OFED_LINUX-5.4-3.5.8.0-ubuntu18.04-x86_64.tgz ├── Miniconda3-py37_4.12.0-Linux-x86_64.sh ├── horovod-0.22.1.tar.gz ├── openmpi-3.0.0-bin.tar.gz ├── pip.conf ├── torch-1.8.1+cu111-cp37-cp37m-linux_x86_64.whl ├── torchaudio-0.8.1-cp37-cp37m-linux_x86_64.whl └── torchvision-0.9.1+cu111-cp37-cp37m-linux_x86_64.whl
- 构建容器镜像。在Dockerfile文件所在的目录执行如下命令构建容器镜像horovod-pytorch:0.22.1-1.8.1-ofed-cuda11.1。
1docker build . -t horovod-pytorch:0.22.1-1.8.1-ofed-cuda11.1
构建过程结束时出现如下构建日志说明镜像构建成功。Successfully tagged horovod-pytorch:0.22.1-1.8.1-ofed-cuda11.1
Step5 上传镜像至SWR服务
- 登录容器镜像服务控制台,选择区域,要和ModelArts区域保持一致,否则无法选择到镜像。
- 单击右上角“创建组织”,输入组织名称完成组织创建。请自定义组织名称,本示例使用“deep-learning”,下面的命令中涉及到组织名称“deep-learning”也请替换为自定义的值。
- 单击右上角“登录指令”,获取登录访问指令,本文选择复制临时登录指令。
- 以root用户登录本地环境,输入复制的SWR临时登录指令。
- 上传镜像至容器镜像服务镜像仓库。
- 使用docker tag命令给上传镜像打标签。
#region和domain信息请替换为实际值,组织名称deep-learning也请替换为自定义的值。 sudo docker tag horovod-pytorch:0.22.1-1.8.1-ofed-cuda11.1 swr.{region-id}.{domain}/deep-learning/horovod-pytorch:0.22.1-1.8.1-ofed-cuda11.1 #此处以华为云cn-north-4为例 sudo docker tag horovod-pytorch:0.22.1-1.8.1-ofed-cuda11.1 swr.cn-north-4.myhuaweicloud.com/deep-learning/horovod-pytorch:0.22.1-1.8.1-ofed-cuda11.1 - 使用docker push命令上传镜像。
#region和domain信息请替换为实际值,组织名称deep-learning也请替换为自定义的值。 sudo docker push swr.{region-id}.{domain}/deep-learning/horovod-pytorch:0.22.1-1.8.1-ofed-cuda11.1 #此处以华为云cn-north-4为例 sudo docker push swr.cn-north-4.myhuaweicloud.com/deep-learning/horovod-pytorch:0.22.1-1.8.1-ofed-cuda11.1
- 使用docker tag命令给上传镜像打标签。
- 完成镜像上传后,在“容器镜像服务控制台>我的镜像”页面可查看已上传的自定义镜像。
“swr.cn-north-4.myhuaweicloud.com/deep-learning/horovod-pytorch:0.22.1-1.8.1-ofed-cuda11.1”即为此自定义镜像的“SWR_URL”。
Step6 在ModelArts上创建训练作业
- 登录ModelArts管理控制台,检查当前账号是否已完成访问授权的配置。如未完成,请参考使用委托授权。针对之前使用访问密钥授权的用户,建议清空授权,然后使用委托进行授权。
- 在左侧导航栏中选择“训练管理 > 训练作业”,默认进入“训练作业”列表。
- 在“创建训练作业”页面,填写相关参数信息,然后单击“下一步”。
- 创建方式:选择“自定义算法”
- 镜像来源:选择“自定义”
- 镜像地址:Step5 上传镜像至SWR服务中创建的镜像。“swr.cn-north-4.myhuaweicloud.com/deep-learning/horovod-pytorch:0.22.1-1.8.1-ofed-cuda11.1”
- 代码目录:设置为OBS中存放启动脚本文件的目录,例如:“obs://test-modelarts/pytorch/demo-code/”,训练代码会被自动下载至训练容器的“${MA_JOB_DIR}/demo-code”目录中,“demo-code”为OBS存放代码路径的最后一级目录,可以根据实际修改。
- 启动命令:“bash ${MA_JOB_DIR}/demo-code/run_mpi.sh python ${MA_JOB_DIR}/demo-code/pytorch_synthetic_benchmark.py” ,此处的“demo-code”为用户自定义的OBS存放代码路径的最后一级目录,可以根据实际修改。
- 环境变量:单击“增加环境变量”,增加环境变量:MY_SSHD_PORT=38888。
- 资源池:选择公共资源池。
- 资源类型:选择GPU规格。
- 计算节点个数:1个或者2个。
- 永久保存日志:打开。
- 作业日志路径:设置为OBS中存放训练日志的路径。例如:“obs://test-modelarts/pytorch/log/”
- 在“规格确认”页面,确认训练作业的参数信息,确认无误后单击“提交”。
- 训练作业创建完成后,后台将自动完成容器镜像下载、代码目录下载、执行启动命令等动作。
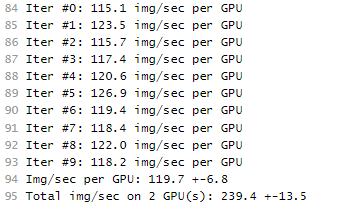
训练作业一般需要运行一段时间,根据您的训练业务逻辑和选择的资源不同,训练时长将持续几十分钟到几小时不等。训练作业执行成功后,日志信息如下所示。
图1 GPU规格运行日志信息(1个计算节点)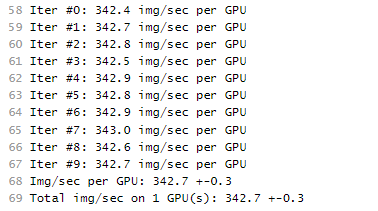 图2 GPU规格运行日志信息(2个计算节点)
图2 GPU规格运行日志信息(2个计算节点)