

配置小时调度
该指导提供配置小时调度的具体操作步骤。用户开发一个批处理的Pipeline作业时,需要配置MRS Hive SQL节点参数,并按照设置的小时周期调度去运行该作业,系统会按照所配置的小时周期调度去生成作业实例,同时您也可以查看作业运行日志信息,方便您对问题进行定位。
小时调度包含间隔小时和离散小时两种调度方式,满足了不同用户对小时调度的灵活配置。
两种场景的差异总结如下表所示。
| 调度场景 | 差异点 |
|---|---|
| 间隔小时 | 作业调度设置了生效时间、开始时间、间隔时间、结束时间后,作业运行时,会按照所设置的间隔小时去调度运行。 比如,设置作业计划调度生效时间为2025年5月20号,且持续有效,调度运行开始时间每天0点0分开始调度,每隔2小时,作业调度一次,23点59分结束。 作业实际运行周期为2025-05-20 00:00:00、2025-05-20 02:00:00、2025-05-20 04:00:00……2025-05-20 22:00:00。当天调度周期运行完成后,到第二天零点,开始第二天的调度运行,作业运行周期为2025-05-21 00:00:00、2025-05-21 02:00:00等。 |
| 离散小时 | 作业调度设置了生效时间、离散小时、指定分钟后,作业运行时,会按照所指定的离散小时去调度运行。 比如,设置作业计划调度生效时间为2025年5月20号,且持续有效,离散小时设置为每天9点、10点、15点,16点,19点,分钟指定为00分钟。 作业实际运行周期为2025-05-20 09:00:00、2025-05-20 10:00:00、2025-05-20 15:00:00、2025-05-20 16:00:00、2025-05-20 19:00:00。当天调度周期运行完成后,到第二天的9点,开始第二天的调度运行,作业运行周期为2025-05-21 09:00:00、2025-05-21 10:00:00等。 |
基本概念
- 作业(数据开发):在数据开发中,作业由一个或多个节点组成,共同执行以完成对数据的一系列操作。
- 节点:节点用于定义对数据执行的操作。例如,使用“MRS Hive SQL”节点可以实现在数据开发模块预先定义的Hive SQL脚本。该节点可以传递SQL语句到MRS Hive SQL节点中执行,支持DML与DDL SQL语句。
- 周期调度:按照设置的调度周期,会周期性自动运行作业。调度周期需要合理设置,单个作业最多允许5个实例并行执行,如果作业实际执行时间大于作业配置的调度周期,会导致后面批次的作业实例堆积,从而出现计划时间和开始时间相差大。
- 作业依赖:可以选择不同工作空间的周期调度作业作为依赖作业,则仅当依赖的作业运行完成时,才开始执行当前作业。
操作流程
| 操作项 | 操作步骤 | 步骤说明 |
|---|---|---|
| 创建一个批处理的Pipeline作业 | 批处理的Pipeline作业即传统的流水线式作业。作业类型选择批处理作业,模式为Pipeline,其他参数保持默认即可。 | |
| 配置节点参数 | 请参见步骤5。 | 作业创建完成后,打开作业通过画布编辑,可以拖入一个或多个节点组成作业节点,各节点依次被流水线式地执行。您需要为作业节点配置相关参数,便于后面作业调度。 |
| 配置作业参数(小时周期调度的参数、作业依赖等) | 配置小时周期调度相关参数,作业启动调度后,会按照设置的小时周期调度规律运行作业。 作业依赖表示当前作业所依赖的其他作业。依赖作业运行完成后,当前作业才开始运行。 | |
| 执行作业调度 | 作业调度运行后,前往作业监控页面查看作业运行结果,作业运行失败的话,可以查看运行日志,帮助您定位问题原因。 |
准备工作
- 已在管理中心创建通过代理连接方式的数据连接,数据连接名称为hive_000001。具体操作请参见MRS Hive数据连接参数说明。
- 已创建数据库,数据库名称为default。具体操作请参见新建数据库。
- 已创建Hive SQL脚本,脚本名称为hive_0520。具体操作请参见开发SQL脚本。
操作步骤
- 在数据开发主界面的左侧导航栏,选择。
- 右键单击目录,选择“新建作业”。
- 创建一个批处理的Pipeline作业,作业名称为job_8750。
- 作业基本参数设置完成后,单击“确定”,进入作业开发页面。
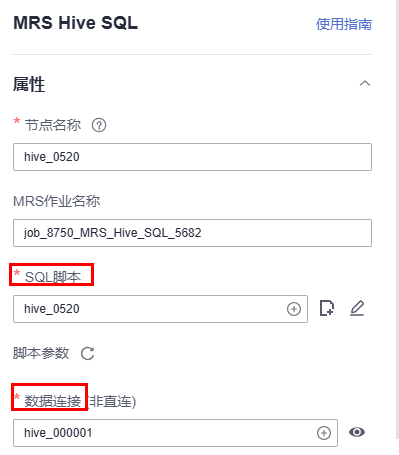
- 将MRS Hive SQL节点拖到画布中间,单击该节点名称,配置节点属性参数。MRS Hive SQL节点参数详细说明请参见MRS Hive SQL。
重要配置参数如下:
- SQL脚本:选择已创建的脚本hive_0520
- 脚本参数:可根据实际业务需要进行配置。如果SQL脚本中没有引用参数,此处脚本参数不显示。
- 数据连接:选择已创建的数据连接hive_000001(脚本中选择的数据连接) 图1 配置节点参数
其他参数根据实际需要可设置,高级参数系统默认,此处可以不做配置。
- 单击右侧的“调度配置”,设置该作业的“调度方式”为“周期调度”,“调度周期”选择“小时”进行调度。
- 配置作业的依赖关系。当所依赖的作业运行完成时,才开始执行当前作业。周期调度依赖策略详细描述,请参见周期调度依赖策略。 图4 配置作业依赖

- 调度属性参数和作业依赖参数配置完后,其他作业参数保持默认。
- 作业配置完成后,单击保存并提交作业版本。 图5 提交作业版本

- 单击“执行调度”,作业启动调度。

- 当所依赖的作业运行完成时,才开始执行当前作业。依赖的作业未完成时,当前作业处于等待运行的状态。
- 调度周期需要合理设置,单个作业最多允许5个实例并行执行,如果作业实际执行时间大于作业配置的调度周期,会导致后面批次的作业实例堆积,从而出现计划时间和开始时间相差大。同时,如果所依赖的作业的调度周期与当前作业调度运行周期设置的差异比较大,可能会导致作业运行异常,所以调度周期设置要合理,要满足符合业务的运行规律。
- 离散小时调度依赖场景很灵活,比如最近依赖,详细信息请参见离散小时调度与作业最近依赖调度逻辑。
- 在左侧菜单栏,选择“运维调度 > 作业监控”,在“批作业监控”页签下查看作业运行结果。 图6 批作业监控



相关文档
- 创建数据连接:通过配置数据源信息,可以建立数据连接。DataArts Studio基于管理中心的数据连接对数据湖底座进行数据开发、治理、服务和运营。配置开发和生产环境的数据连接后,数据开发时脚本/作业中的开发环境数据连接通过发布流程后,将自动切换对应生产环境的数据连接。具体请参见创建DataArts Studio数据连接。
- 创建数据表:您可以通过可视化模式、DDL模式或SQL脚本方式新建数据表。(推荐)可视化模式:您可以直接在DataArts Studio数据开发模块通过No Code方式,新建数据表。具体请参见新建数据表。
- 配置作业节点参数:节点定义对数据执行的操作。数据开发模块提供数据集成、计算&分析、数据库操作、资源管理等类型的节点,您可以根据业务模型选择所需的节点。具体请参见节点参数配置
- 周期调度依赖策略:数据开发当前支持两种调度依赖策略:传统周期调度依赖和自然周期调度依赖。具体参见周期调度依赖策略。
- 离散小时调度与作业最近依赖调度逻辑:随着用户业务的演进,自然周期调度中,增加了许多新的调度规则,如离散小时调度,最近依赖调度等。具体参见离散小时调度与作业最近依赖调度逻辑。




