公网发现与采集
通过公网在线发现并采集源端云平台资源,获取源端资源详细信息。目前支持的源端云平台为:阿里云、华为云、AWS、腾讯云、Azure、七牛云、金山云。
- 阿里云和华为云支持采集的资源类型包括:主机、容器、中间件、数据库、网络和存储。
- 腾讯云支持采集的资源类型包括:主机、数据库、存储。
- AWS和Azure支持采集的资源类型包括:主机、容器、中间件、数据库、存储和网络。
- 七牛云和金山云支持采集的资料类型包括:对象存储。
创建公网发现任务
- 登录迁移中心管理控制台。
- 单击左侧导航栏的“调研>资源采集”,进入资源采集页面。在页面左上角的当前项目下拉列表中选择迁移项目。
- 单击任务框中的“发现>公网发现”,进入创建公网发现任务页面。
图1 公网发现
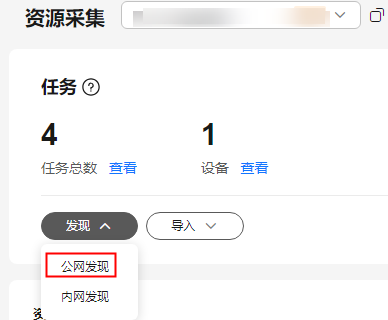
- 根据表1,配置公网发现任务参数。
表1 公网发现任务参数说明 区域
参数
说明
是否必选
基础配置
任务名称
自定义发现任务名称。
是
任务说明
输入发现任务说明。
否
任务配置
源端
选择源端云平台,目前支持的云平台有阿里云、华为云、AWS、腾讯云、Azure、七牛云、金山云。
是
凭证
选择源端对应的凭证,如未提前添加凭证,请单击“新建凭证”,填写相应参数,校验并保存凭证。
- 阿里云、华为云、AWS、腾讯云、七牛云、金山云认证方式请选择“AK/SK”,并输入源端账号的AK/SK。
- Azure认证方式请选择“ID/密钥”。添加凭证所需的信息获取方法请参见如何获取添加Azure凭证所需的信息。
是
区域
选择要发现的源端云平台区域,支持多选。
是
- 在资源类型下拉列表,勾选需要进行采集的资源类型(采集项)。当前支持采集的云平台和资源类型参见表2。
图2 选择要采集的资源类型

表2 支持采集的资源类型 云平台
资源类型
子类型
阿里云
- 主机
- 容器
- 大数据
- 数据库
-
中间件
- Redis
- Kafka
存储
- 对象存储
- 文件存储
网络
- 云连接
- 负载均衡(ALB、CLB)
- 专线
- 公网域名
- 内网域名
- 弹性公网IP
- 公网NAT网关
- 路由表
- 安全组
- 虚拟私有云
- VPN网关
华为云
- 主机
- 容器
- 大数据
- 数据库
-
中间件
- Redis
- Kafka
存储
- 对象存储
- 文件存储
网络
- 负载均衡(ELB)
- 公网域名
- 内网域名
- 弹性公网IP
- 公网NAT网关
- 路由表
- 安全组
- 虚拟私有云
AWS
- 主机
- 容器
- 数据库
-
存储
- 对象存储
- 文件存储
网络
- 负载均衡(ELB)(目前只支持CLB类型)
- 公网域名
- 内网域名
- 弹性公网IP
- 公网NAT网关
- 路由表
- 安全组
- 虚拟私有云
存储
- 对象存储
- 文件存储
腾讯云
- 主机
- 数据库
-
存储
- 对象存储
- 文件存储
Azure
- 主机
- 容器
- 数据库
-
存储
- 对象存储
- 文件存储
中间件
- Redis
- Kafka
网络
- 弹性公网IP
- 路由表
- 安全组
- 公网NAT网关
- 虚拟私有云
- 负载均衡(ELB)
七牛云
存储
对象存储
金山云
存储
对象存储
- (可选)将采集的资源关联到应用。
- 已提前创建应用,在“应用”的下拉列表中选择要关联的应用。
- 未提前创建应用,单击“新建应用”,弹出新建应用窗口,输入自定义的应用名称和描述;根据实际需求,选择业务场景和使用场景;区域选择目的端所在区域,单击“确定”按钮,应用创建成功。
- 单击“确认”,公网发现任务创建完成,系统自动开始资源发现。
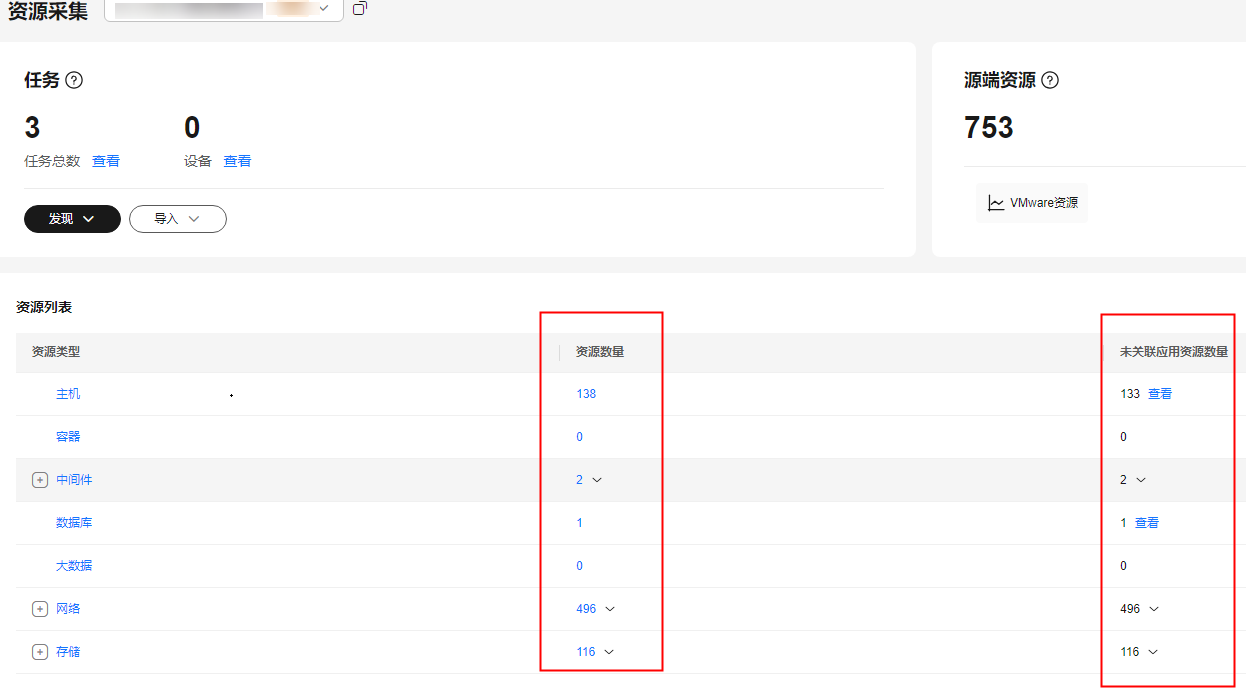
- 您可以在资源采集页面,查看发现的源端资源列表和资源详情。
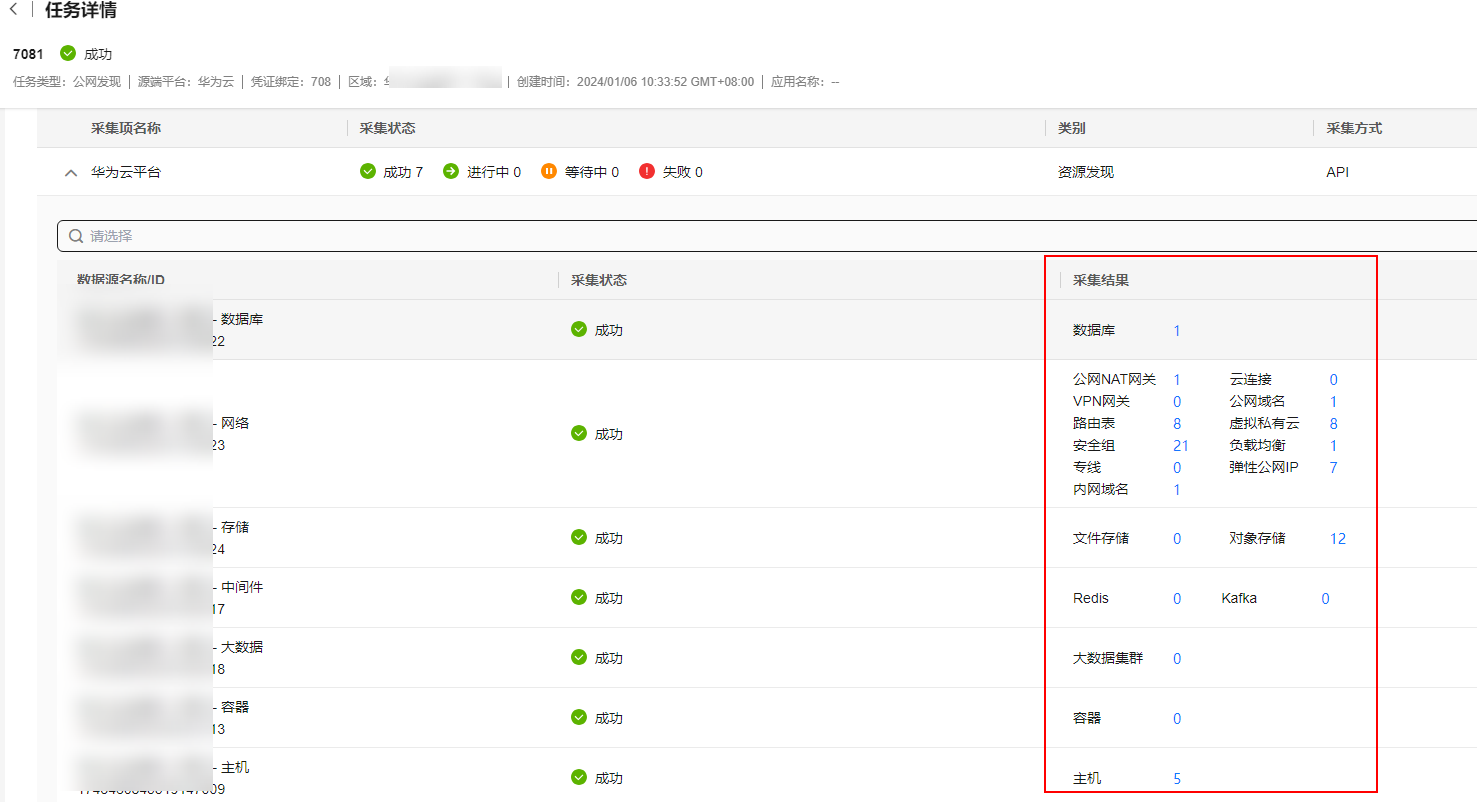
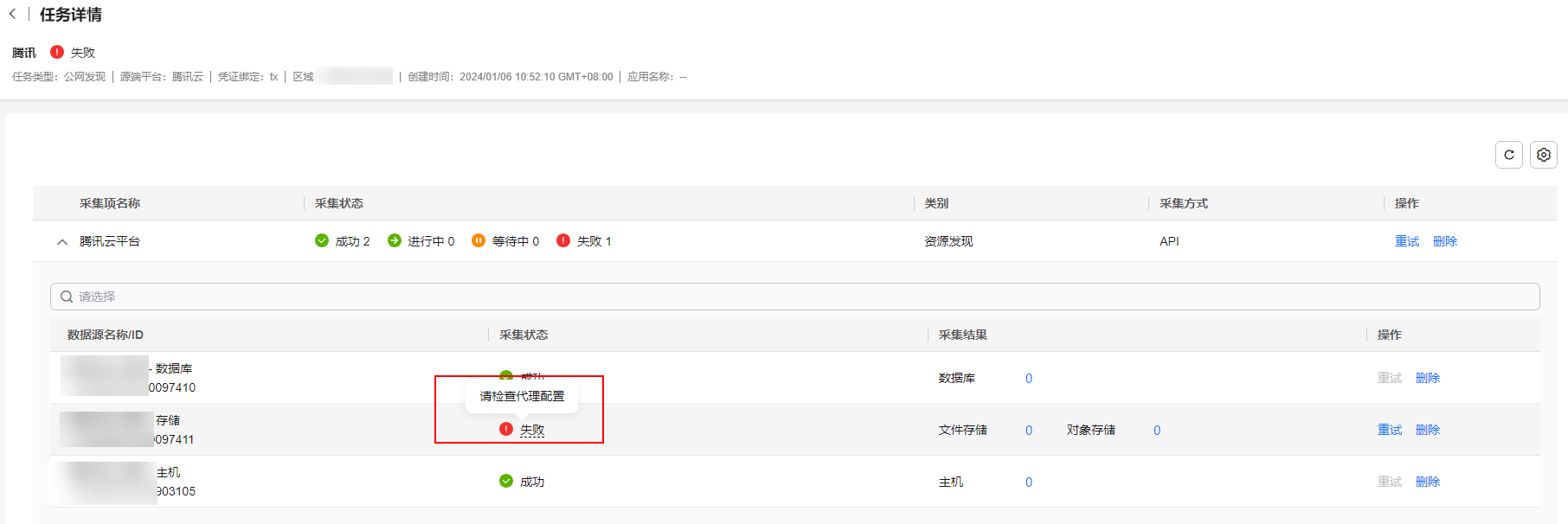
- 您可以在任务列表页面,查看任务状态和详情。
- 发现任务状态为成功后,根据不同资源类型,进行后续操作。
主机源端迁移准备度检查
- 在源端内网环境中安装Edge工具并完成注册。
- 在资源采集页面的资源列表,单击主机或主机的资源数量,进入资源列表页面的主机页签。
- 勾选待迁移的主机,单击列表上方的关联到应用按钮,弹出关联到应用窗口。
- 已提前创建应用,在下拉列表中选择要关联的应用,单击“确定”。
- 未提前创建应用,单击“新建应用”,输入自定义的应用名称和描述,选择业务场景、使用场景和目的端区域,单击“创建”按钮,应用创建成功。选择创建的应用后,单击“确定”。
- 在列表上方选择“目标场景>主机迁移”,此时源端迁移准备度列会出现“配置”按钮。
- 单击源端迁移准备度列的“配置”,弹出配置窗口。
- 根据表3,配置参数。
表3 迁移准备度参数配置说明 参数
配置说明
类型
根据实际的主机操作系统类型选择。
采集设备
选择在源端环境安装的Edge工具。
接入IP
选择主机接入IP,可以为公网IP,也可以是私有IP;迁移预检查通过后,该IP会作为后续主机迁移工作流的资源接入IP。
端口
主机开放端口。
- Windows主机默认为5985端口,无法修改。
- Linux主机默认22端口,可根据实际情况修改。
凭证
选择主机凭证,如未提前在Edge上添加源端主机凭证,请前往Edge控制台添加,并同步至迁移中心。
须知:为确保采集过程具备充分的系统访问权限,从而能够获取到必要的信息和数据。对主机深度采集的凭证要求如下:
- 对Linux主机进行深度采集时,请添加Root账号和密码作为采集凭证。
- 对Windows主机进行深度采集时,请添加Administrator账号和密码作为采集凭证。
- 配置完成后,单击“确认”按钮,系统会校验配置信息的正确性并开始源端迁移准备度检查,当源端迁移准备度列状态会变为已就绪时,代表该主机已满足迁移条件,可以进行下一阶段迁移方案设计或迁移方案配置。
主机深度采集
- 在源端内网环境中安装Edge工具并与迁移中心连接。
- 在资源采集页面的资源列表,单击主机资源的资源数量,进入资源列表页面的主机页签。
- 在需要进行深度采集的主机采集设备列,单击“配置”,弹出配置窗口。根据表4,配置参数。
表4 深度采集参数配置说明 参数
配置说明
类型
根据实际的主机操作系统类型选择。
采集设备
选择在源端环境安装的Edge工具。
接入IP
选择主机接入IP,可以为公网IP,也可以是私有IP;迁移预检查通过后,该IP会作为后续主机迁移工作流的资源接入IP。
端口
主机开放端口。
- Windows主机默认为5985端口,无法修改。
- Linux主机默认22端口,可根据实际情况修改。
凭证
选择主机凭证,如未提前在Edge上添加源端主机凭证,请前往Edge控制台添加,并同步至迁移中心。
须知:为确保采集过程具备充分的系统访问权限,从而能够获取到必要的信息和数据。对主机深度采集的凭证要求如下:
- 对Linux主机进行深度采集时,请添加Root账号和密码作为采集凭证。
- 对Windows主机进行深度采集时,请添加Administrator账号和密码作为采集凭证。
- 单击“确认”,采集设备和凭证都绑定成功后,系统会自动开始深度采集。当深度采集列的状态为“已采集”时,代表采集完成。可以进行下一阶段迁移方案设计或迁移方案配置。
容器深度采集
- 在源端内网环境中安装Edge工具并与迁移中心连接。
- 在资源采集页面的资源列表,单击容器资源的资源数量,进入资源列表页面的容器页签。
- 在需要进行深度采集的容器采集设备列,单击“绑定”,弹出绑定采集设备窗口。
如果需要批量绑定,可以同时勾选多个资源,单击列表上方的“绑定采集设备”,弹出绑定采集设备窗口。
- 选择源端安装的Edge工具,单击“确定”。绑定成功后,资源的采集设备列状态会变为已绑定。
- 采集设备绑定成功后,还需要为资源绑定凭证,单击资源凭证列的“绑定”,弹出绑定凭证窗口。
- 选择资源凭证,如未提前在Edge上添加源端资源凭证,请前往Edge控制台添加,并同步至迁移中心。
- 单击“确定”,系统会自动检查凭证绑定状态。当深度采集列状态为就绪时,单击深度采集列的“采集”进行深度采集。首次深度采集完成后,可以单击采集状态列的“重新采集”按钮,进行多次深度采集。采集完成后,单击资源名称可以查看采集到的容器详情。
对象存储深度采集
- 在源端内网环境中安装Edge工具并与迁移中心连接。
- 在资源采集页面的资源列表,单击存储资源的资源数量,进入资源列表页面的存储页签。
- 在对象存储资源列表中,单击深度采集配置列的“配置”,弹出配置窗口。
- 选择源端安装的Edge工具和相应的资源凭证,单击“确认”完成配置。如未提前在Edge上添加源端资源凭证,请前往Edge控制台添加,并同步至迁移中心。

在对Azure云平台对象存储资源进行深度采集时,需要使用“存储账户”和“密钥”作为采集凭证,凭证的获取方法请参见如何获取Azure对象存储深度采集所需凭证。
- 配置完成后,单击操作列的“添加前缀”,弹出添加前缀窗口。
- 输入指定的资源目录路径进行采集,不输入则默认采集全桶资源,单击“确定”保存前缀设置。
- 完成深度采集配置和添加前缀后,单击操作列的“深度采集”,系统开始进行对象存储资源的深度采集。支持进行多次深度采集。当采集状态为采集完成后,单击资源名称,可以查看采集到的信息。
数据库深度采集
当前支持对AWS RDS(包括MySQL、MariaDB、Aurora、Postgre SQL、SQL Server、Oracle)和AWS DocumentDB数据库进行深度采集,以获取包括数据库版本、引擎、服务器字符集、平均事务每秒(Transaction Per Second, TPS)和查询每秒(Query Per Second, QPS)等关键性能指标在内的详细信息。不同的数据库类型,采集的信息详情可能有所差异。
- 在源端内网环境中或在可以访问到源端数据库的网络环境中安装Edge工具并与迁移中心连接。
- 在资源采集页面的资源列表,单击数据库资源的资源数量,进入资源列表页面的数据库页签。
- 在数据库资源列表中,通过平台类型过滤出采集到的所有AWS数据库资源,在支持深度采集的数据库类型的采集设备列,单击“绑定”,弹出绑定采集设备窗口。
如果需要批量绑定,可以同时勾选多个资源,单击页面右上角的“绑定采集设备”,弹出绑定采集设备窗口。
- 选择源端安装的Edge工具,以及网络接入方式(如果采集的资源与安装Edge的主机处于同一VPC内,可以选择私网接入,否则需要选择公网接入),单击“确定”。绑定成功后,资源的采集设备列状态会变为已绑定。
- 采集设备绑定成功后,还需要为资源绑定凭证,单击资源凭证列的“绑定”,弹出绑定凭证窗口。
- 选择数据库资源凭证,如未提前在Edge上添加源端资源凭证,请前往Edge控制台添加,并同步至迁移中心。
- 单击“确定”,系统会自动检查凭证绑定状态。当深度采集列的状态为就绪时,单击“采集”开始深度采集。首次深度采集完成/采集失败后,可以单击深度采集列的“重新采集”,进行多次深度采集。
- 深度采集完成后,单击数据库名称,进入数据库详情页面,在数据库详情区域,可以查看采集到的详细信息。