

体验KooSearch问答
当知识库有了数据以后,就可以在KooSearch体验平台进行问答体验。
前提条件
- 已开通了KooSearch服务。
- 已准备好数据库,且已上传数据。
- 待进行问答体验的知识库状态为“开启”状态。
进入KooSearch控制台
- 登录云搜索服务管理控制台。
- 在左侧导航栏选择“KooSearch>KooSearch文档问答”,进入KooSearch文档问答页面。
- 选择已创建好的文档问答服务,单击操作列的“问答”,前往KooSearch控制台。
选择知识库
- 在KooSearch控制台,左侧导航栏选择“体验平台”,进入体验平台页面。
- 单击右上角
 ,在“引用来源”对话框勾选知识库,单击“确定”。可以选择单个知识库,也可以打开右边的复选框
,在“引用来源”对话框勾选知识库,单击“确定”。可以选择单个知识库,也可以打开右边的复选框 选择多个知识库作为知识来源。
选择多个知识库作为知识来源。
问答体验将在所选择的知识库中进行答案搜索。
体验问答
- 在“体验平台”页面右上角单击“问答”,切换至问答体验页面。
- 在输入框中输入问题。
- 在输入框左侧单击
 图标,可以选择“按标签”、“按文档”、“按表格”搜索。
图标,可以选择“按标签”、“按文档”、“按表格”搜索。
- 按标签:按文档标签筛选文档,结果只在筛选出来的文档中搜索。
- 按文档:选择具体文档,结果只在选择出来的文档中搜索。
- 按表格:当知识库开启了表格问答功能时,可以选择表格问答,当问题命中含表格数据的excel文档时会触发nl2sql,结果只在选择出来的表格中搜索。

按表格问答时,建议在问题中明确表格名称、列名,以提高问答效果。
- 单击
 ,查看搜索到的答案。
图1 体验问答
,查看搜索到的答案。
图1 体验问答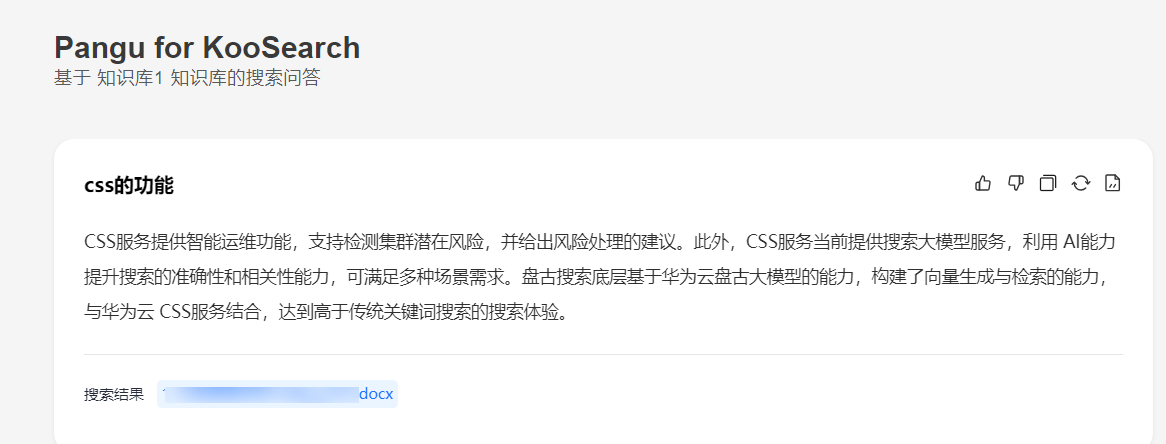
表1 图标说明 图标
说明

认同内容,直接单击即可。

反馈建议。不认同内容,在针对问题、针对搜索、针对回答中选出您认为的不合理的意见,也可以在对话框中输入您认为更理想的回答,单击“提交”。

复制内容。

刷新内容。

查看答案参考源。在参考列表中,单击“阅读全文”,可查看文档原文。
说明:当前针对上传的多栏排版docx文档,查看文档原文时存在内容显示错位及显示不全的问题。
- 单击搜索结果下面的文档名称,可以查看参考文档的详细内容,如果想阅读参考文档,单击“阅读全文”按钮。
- 问答体验页面上还有“对话配置”和“对话清空”按钮,如下图所示。
图2 按钮说明
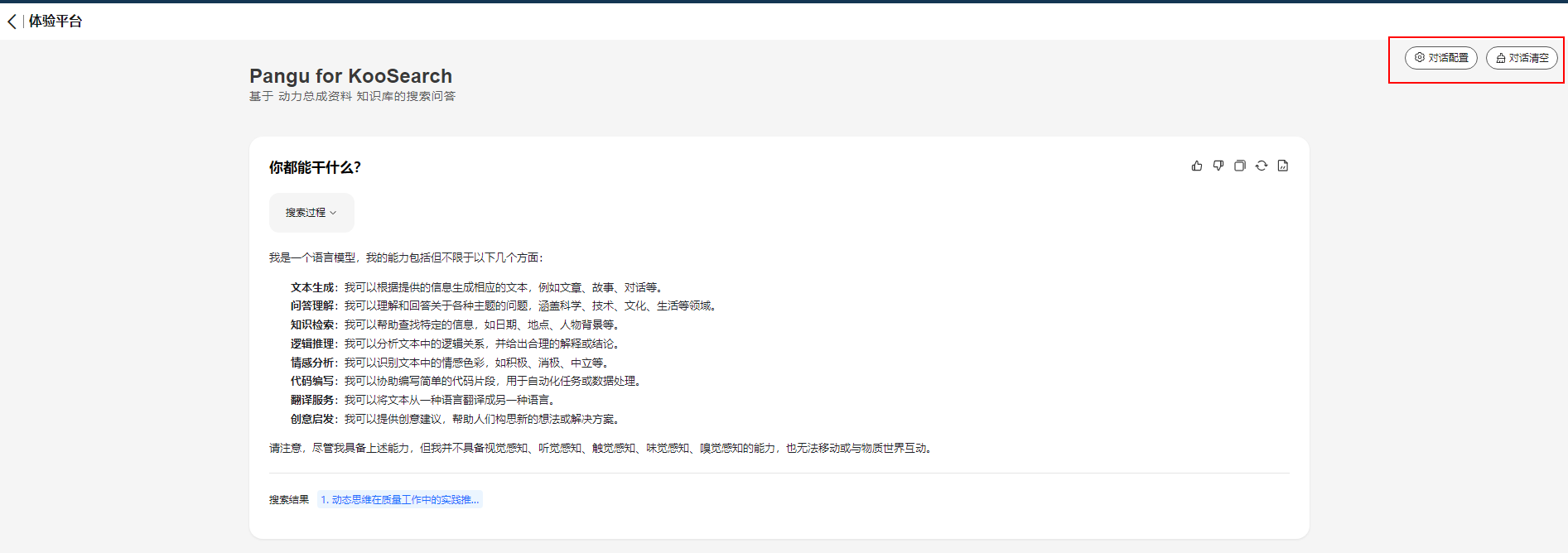
- “对话配置”:如果您在对话过程中想修改配置,可以单击“对话配置”按钮,具体的配置参数请参考配置问答小节。
- “对话清空”:单击“对话清空”按钮可以清空当前对话页面,清空之后再进行问答,会默认进行下一轮问答。

配置问答
- 在“体验平台”页面,单击右上角
 ,在配置页面进行问答配置。
,在配置页面进行问答配置。
表2 召回策略 参数
说明
文本召回策略
是指在文档中搜索时,生成结果的策略。包含语义检索、混合检索、关键词检索。
- 语义检索:切片使用向量检索技术,FAQ使用querytoquery相似检索技术。
- 混合检索:切片使用向量检索和关键词检索混合检索,FAQ使用querytoquery相似检索技术。
- 关键词检索:切片使用倒排检索技术,FAQ使用querytoquery相似检索技术。
语义检索topk召回数量:是指语义搜索生成的片段数量。语义检索topk未配置时,将使用默认值50。
关键字topK召回数量:是指搜索生成的片段数量。
FAQ检索召回个数:通过querytoquery相似检索得到相似得分,按照配置个数进行截断检索召回默认值2。
精排:对搜索结果进行过滤和排序后呈现给。
知识库精排开关默认为开启状态,若未配置,则为开启状态。注意:关闭精排时相关性得分范围为0-200,开启精排时相关性得分为0-1,在开启或关闭精排后需要重新设置相关性阈值和引用相关度阈值,否则会影响过滤效果!
- 搜索页面相关性阈值:超过相关度阈值的搜索结果才能在搜索结果页展示,否则被过滤。
- 问答相关度阈值:超过相关度阈值的搜索结果会提交给大模型进行总结,否则被过滤。
FAQ召回策略
是指在FAQ中搜索结果时,生成结果的策略。
FAQ检索召回相似阈值:通过querytoquery相似检索得到相似得分,超过阈值可以检索召回,默认值0.8。
FAQ问答直出阈值:超过阈值的FAQ会作为答案直接输出,不需要经过大模型总结。默认值0.95。
表3 问答配置 参数
说明
NLP模型服务
选择NLP模型服务。
Query改写
开启后,将根据用户历史多轮对话,对query进行多轮改写和分解,改写后的query仅用于文档检索。
意图分类
勾选意图分类。
- 人设类:你叫什么名字?
- 天气类:今天天气怎样?
- 行业知识类: 对于行业知识类,建议使用前缀匹配,后续可能继续扩展。如:行业知识类-金融:贷款重组的定义是什么。
- 行业知识类-制造:我国的制造业到了什么阶段?
- 行业知识类-医疗:医疗事故有哪些?
- 行业知识类-政务:《国务院关于印发新一代人工智能发展规划的通知》的指导思想是什么?
- 行业知识类-金融:今天的股市怎么样?
- 语言任务类:请创作一封约460字的邮件,主题是咨询一个新的IT项目的细节,这个邮件将被发送给公司的IT项目经理。
- 通用知识类:豆汁和豆浆的区别。
- 闲聊类:坐火车累死了。
说明:未选择分类的先使用知识库检索再进行大模型总结,选中的分类直接使用大模型回答。
拒答回复
开启后,可以自己设置拒答回复语,当搜索的问题没有答案时,则会回复设置的回复语。
通用自定义prompt
- 使用场景:主要用于非RAG场景下的模型生成阶段。(非RAG场景:对话生成任务中,不使用检索步骤进行信息检索,直接使用生成模型生成回复。)
- 组成要素:用户问题、任务指令以及其他要求。
- 使用方式:支持自定义prompt,如果未配置自定义prompt,则使用默认prompt。在自定义构建时,请参考默认prompt的格式。
QA问题生成自定义prompt
你是问题抽取专家,请根据下面的文档文本内容,归纳生成最多{0}个高质量问题,要求: (1)生成的问题可以根据所提供的文档文本内容进行回答 (2)以知识库问答的口语化个人提问方式呈现 (3)生成问题不能特指该文档文本内容 (4)生成知识点丰富全面的多样性问题 (5)生成的问题不能过于简单,确保生成问题的质量文档文本内容:{1}
注意:其中{0}和{1}表示占位符,且顺序固定,检索出来的文章内容将被填充至{0}所在位置,格式为 【文档名称】:{title1} 【文档内容】:{content1} 【文档名称】:{title2} 【文档内容】:{content2} ...... 检索的query将被填充至{1}所在位置后进行生成。QA答案生成自定义prompt
你是问题抽取专家,请根据下面的文档文本内容,归纳生成最多{0}个高质量问题,要求: (1)生成的问题可以根据所提供的文档文本内容进行回答 (2)以知识库问答的口语化个人提问方式呈现 (3)生成问题不能特指该文档文本内容 (4)生成知识点丰富全面的多样性问题 (5)生成的问题不能过于简单,确保生成问题的质量文档文本内容:{1}
注意:其中{0}和{1}表示占位符,且顺序固定,检索出来的文章内容将被填充至{0}所在位置,格式为 【文档名称】:{title} 【文档内容】:{content} 生成的问题将被填充至{1}所在位置后进行对应答案生成。表4 模型配置 参数
说明
文本多样性(top_p)
通过限制词汇的选择来控制生成文本的多样性。值越高,候选单词越多,文本多样性越高。默认值为0.1。
模型生成最大新词数(max_tokens)
控制文本的最大生成长度,值越大有助于生成较长或完整的回复;值较小,生成的内容越简洁。默认值为2048。
说明:如果选择NLP模型-昇腾云类型的模型服务进行问答,建议设置模型生成最大新词数不超过512。
非搜索增强模型生成多样性(temperature)
控制非搜索增强模型文本的随机性,值越高,文本随机性越高、多样性和创造性越高。默认值为0.6。
搜索增强模型生成多样性(temperature)
控制搜索增强模型文本的随机性,值越高,文本随机性越高、多样性和创造性越高。默认值为0.6。
文本重复度(presence_penalty)
用于控制生成文本中特定单词或短语出现的频率。值越高生成的文本会使用更多样的单词和短语,减少重复性。默认值为0。
- 单击“确定”,完成配置。




