

使用Cypher语句查询图
Cypher是一种声明式图查询语言,使用Cypher语句可以查询和修改GES中的数据,并返回结果。
具体操作步骤如下:
- 进入图引擎编辑器页面,详细操作请参见访问图引擎编辑器。
- Cypher查询编译过程中使用了基于label的点边索引。
内存版图:第一次使用Cypher查询,您需要单击结果展示区右上角的“建索引”(后续使用不用进行此操作)。
持久化图:第一次使用Cypher查询,需要在画布左侧的“索引区”中单击“创建索引”按钮,进行索引创建,具体步骤可参考使用索引管理图。图1 内存版图建索引 图2 持久化图建索引
图2 持久化图建索引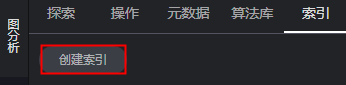
- 在图数据查询区,在您输入查询语句前,按“回车”键执行操作。
Cypher查询语句
常用的查询语句如下表所示:
- 点查询
match (n:movie) return n:查询label为movie的点。
match (n) return n limit 100:表示查询100个节点的详细数据。
match (n{Occupation:'artist'}) return id(n), n.Gender limit 100:查询前100个属性Occupation为artist的点,返回其id以及属性值Gender。
match (n) where id(n)='Vivian' return n:查询id为Vivian的点。
match (n) return n skip 50 limit 100:查询全图所有的点,跳过前50个,而后返回100个。
- 边查询
match (n)-[r]->(m) return r, n, m:查询所有的边,并返回边和边两端的点。
match (n)-[r:rate]->(m) return r, n, m: 查询label为rate的边。
match (n)-[r:rate|:friends]-(m) where id(n)='Vivian' return n,r,m:查询起点为Vivian,边label为rate或friends的所有边。
- 路径查询
match p=(n:user)--(m1:user)--(m2:movie) return p limit 100:查询起点label为user,一跳终点为user,二跳终点为movie的路径,并返回前100条。
- 分组聚集、去重
match (n) return count(*):查询全图点的数目。
match (n:user) return n.Gender, count(n):对label为user的点,统计不同Gender下各有多少点。
match (n:user) return distinct n.Occupation:对label为user的点,拿到属性值Occupation,并去重。
- 排序
match (n:user) return id(n) as name order by name:查询label为user的点的id,命名为name,按照name排序。
- 创建点
create (n:movie{_ID_:'机长',Title: '机长', Year:2019}) return n: 创建一个ID为机长, label为movie,属性值Title为机长, Year为2019的点并返回。
create (n:movie{_ID_:'机长',Title: '机长', Year:2019})-[r:rate]-> (m:movie{_ID_:'攀登XX',Title: '攀登XX', Year:2019}) return r:创建两个点,以及其关联的边。
- 创建边
match (n),(m) where id(n)= '机长' and id(m)= 'Lethal Weapon' create (n)-[r:rate]->(m) return r:给定两个id,创建一条label为rate的边(建议2.2.21及以上版本使用此查询)。
- 更改属性
match (n) where id(n)= '机长' set n.Title= '《机长》' return n:查找id为机长的点,修改点的属性值Title为《机长》。
- 删除点
match (n) where id(n)= '机长' delete n:查找id为机长的点,并删除。
match (n) where id(n)= '机长' detach delete n:查找id为机长的点,删除点以及其关联的边。
- 查询schema:call db.schema()
注意:单独执行此接口仅返回的点对应的schema元数据,页面上将会看到点label呈现的多个孤立点。如果您希望看到点边结构的schema可视化,可以调用生成schema结构API,然后在cypher输入框中输入call db.schema()。

- 如果您输入了多个Cypher查询命令,可以在输入框中通过上下方向键来查找历史命令。
- Cypher查询支持联想历史记录的功能,根据您输入的语法关键字会自动显示您刚输入过的语法供您参考和选择,帮助您提高查询效率。 图3 Cypher联想查询
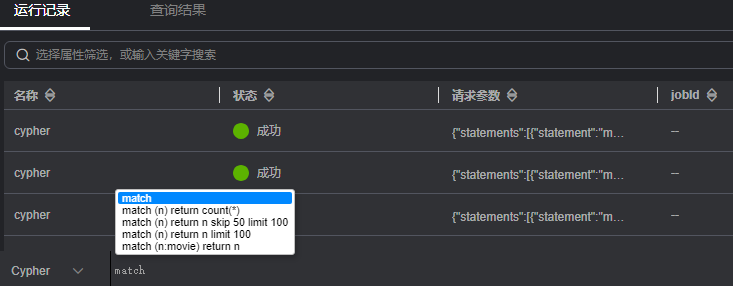
- 输入栏中的关键词,不同的类型会呈现出不同的颜色,具体颜色区分如下:
- 保留字:灰色
注意:保留字是编程语言中的一类语法结构。在特定的编程语言里,这些保留字具有较为特殊的意义,并且在语言的格式说明里被预先定义。
- String类型:橙色
- 键值对(非String类型,包括[键:值]):紫色
- 分隔符(包含 [] {} , ; () . 等):红色
- 变量:绿色
图4 Cypher关键字高亮
- 保留字:灰色




