

更新时间:2025-12-17 GMT+08:00
在试验场进行推理
DataArts Fabric提供了试验场,方便用户在页面上选择推理服务进行推理。试验场支持流式推理,支持用户配置max_tokens等不同的推理参数,还支持不同的推理服务对比。
约束与限制
使用公共推理服务时的通用约束限制如下:
- Token配额约束:每种公共推理服务都有免费配额限制,超过配额不可用,也无法再购买。每种公共推理服务的配额为当前用户在当前局点下所有工作空间共享;
- 时间约束:有效期为服务开通90天内,超过时间则失效。同一个推理服务在不同工作空间下面开通,以首次开通为准。
- 不同的模型有不同的上下文长度约束,请见表公共推理服务。
- 不保证SLA,如果想要更高的性能,建议创建自己的推理服务进行推理;
前提条件
- 已有可正常使用的华为云账号。
- 已有至少一个正常可用的工作空间。
- 已开通公共推理服务,开通流程请参见开通推理服务。
操作步骤
- 登录DataArts Fabric工作空间管理台。
- 选择已创建的工作空间,单击“进入工作空间”。
- 在左侧菜单栏中选择,进入“公共推理服务”"页面。
图1 查看公共推理服务
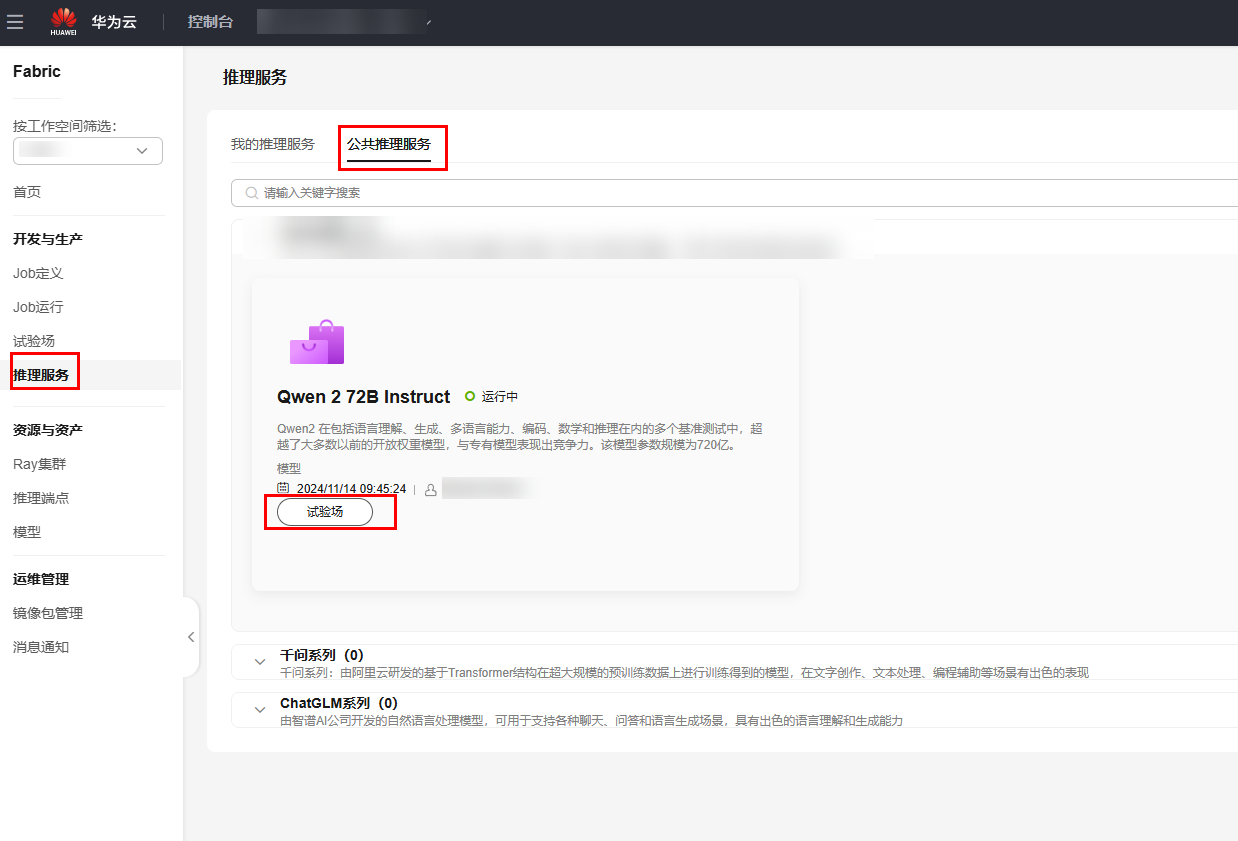
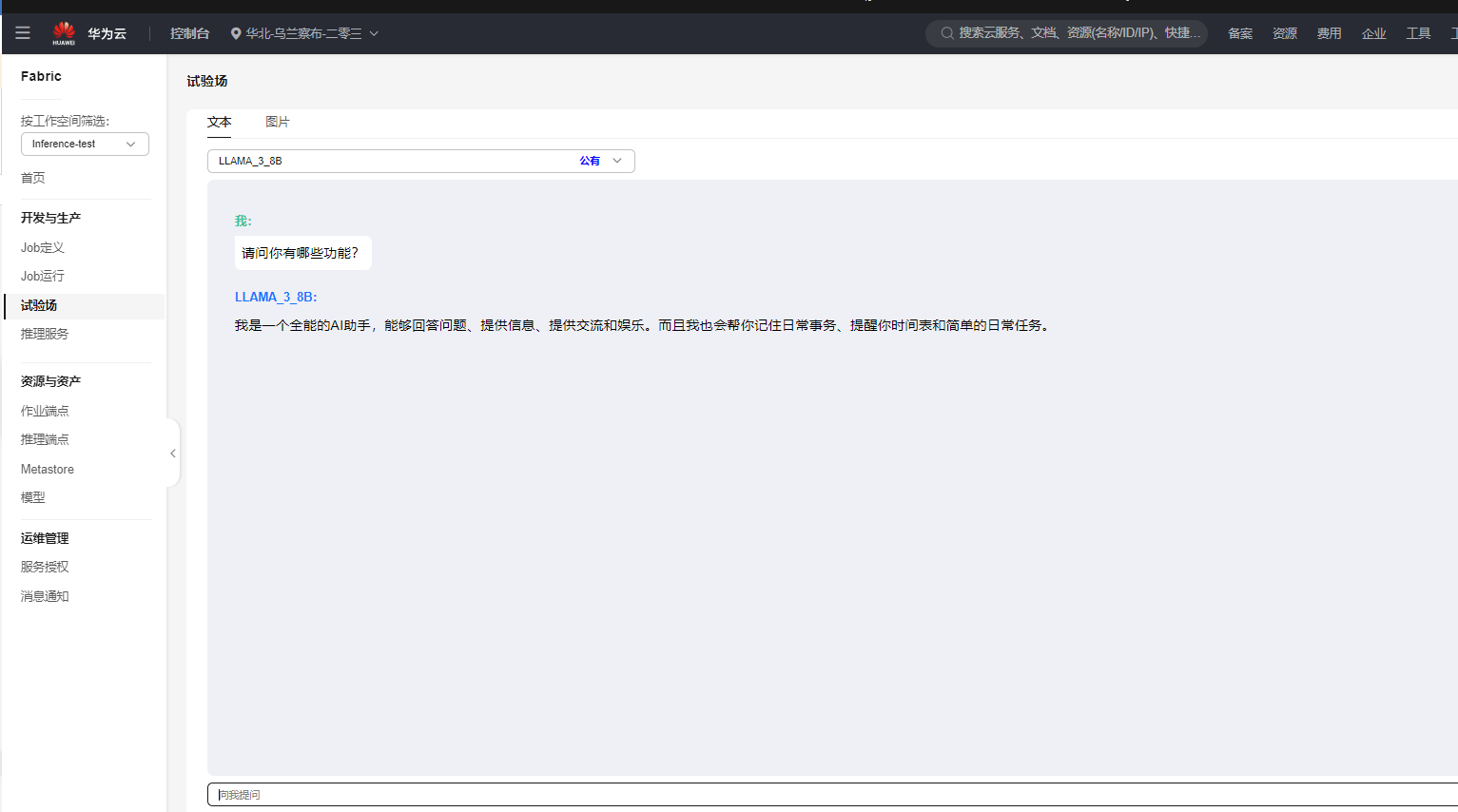
- 单击“试验场”,进入“试验场”页面,进行推理操作。
图2 试验场推理界面
- 调节推理参数(可选)。
如果想调节推理的一些参数,可以单击高级配置来调节推理的max_tokens等参数。参数列表如下。
表1 推理参数说明 名称
说明
max_tokens
要在聊天完成中生成的最大token数。不同公共推理服务支持的最大max_tokens不一样,具体参考公共推理服务介绍。
temperature
Temperature是用于调整随机程度的数字。介于0和2之间。较高的值(如0.8)将使输出更随机,而较低的值(如0.2)将使输出更集中和确定性。
top_p
核心采样,用于控制AI模型根据累积概率考虑的标记范围。
frequency_penalty
数字介于-2.0和2.0之间。频率惩罚,控制文本中词汇的重复度,避免生成文本中某些词汇或短语出现过于频繁。正值会根据它们在文本中的现有频率惩罚新令牌,从而降低模型逐字重复同一行的可能性。
presence_penalty
数字介于-2.0和2.0之间。存在惩罚,控制文本中话题的重复度,避免在对话或文本中反复讨论相同的主题或观点。正值会根据到目前为止它们是否出现在文本中来惩罚新令牌,从而增加模型谈论新主题的可能性。
图3 配置推理参数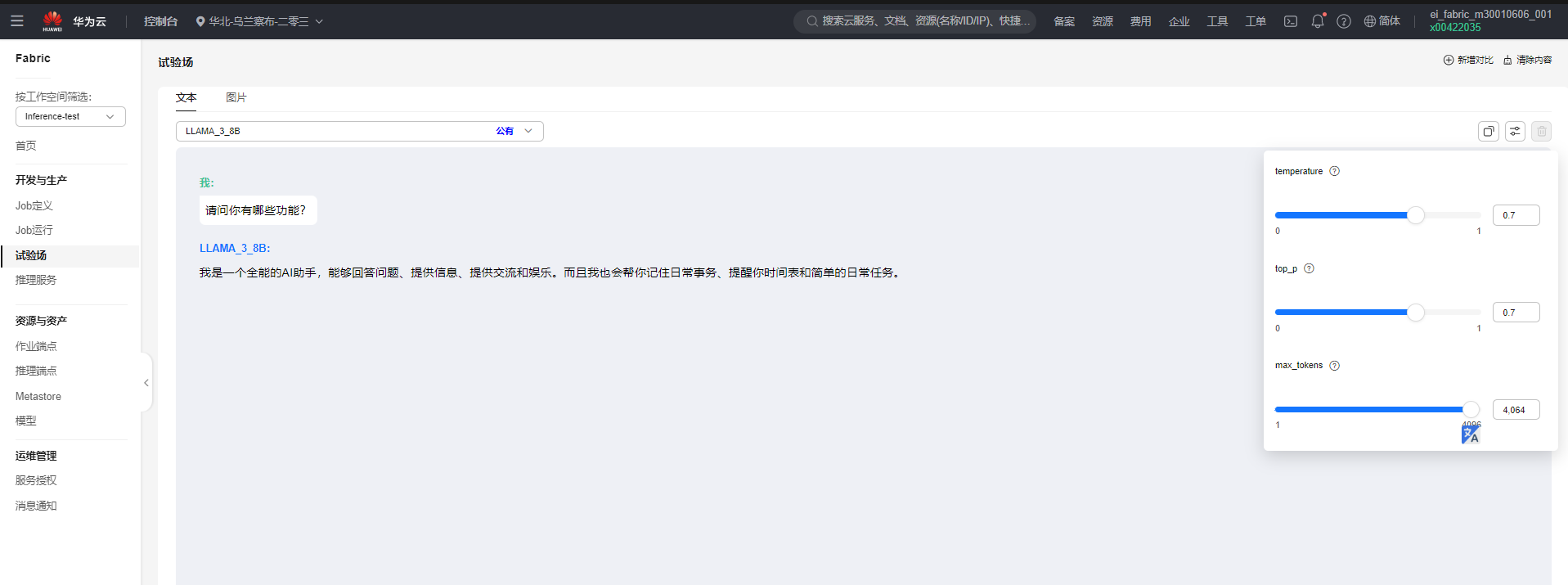
- 对比多个推理服务(可选)。
如果您想对比多个推理服务,DataArts Fabric也提供了推理服务的对比功能。您可以单击右上角的“新增对比”按钮进行新增,最多支持3个推理服务进行对比。
图4 推理服务对比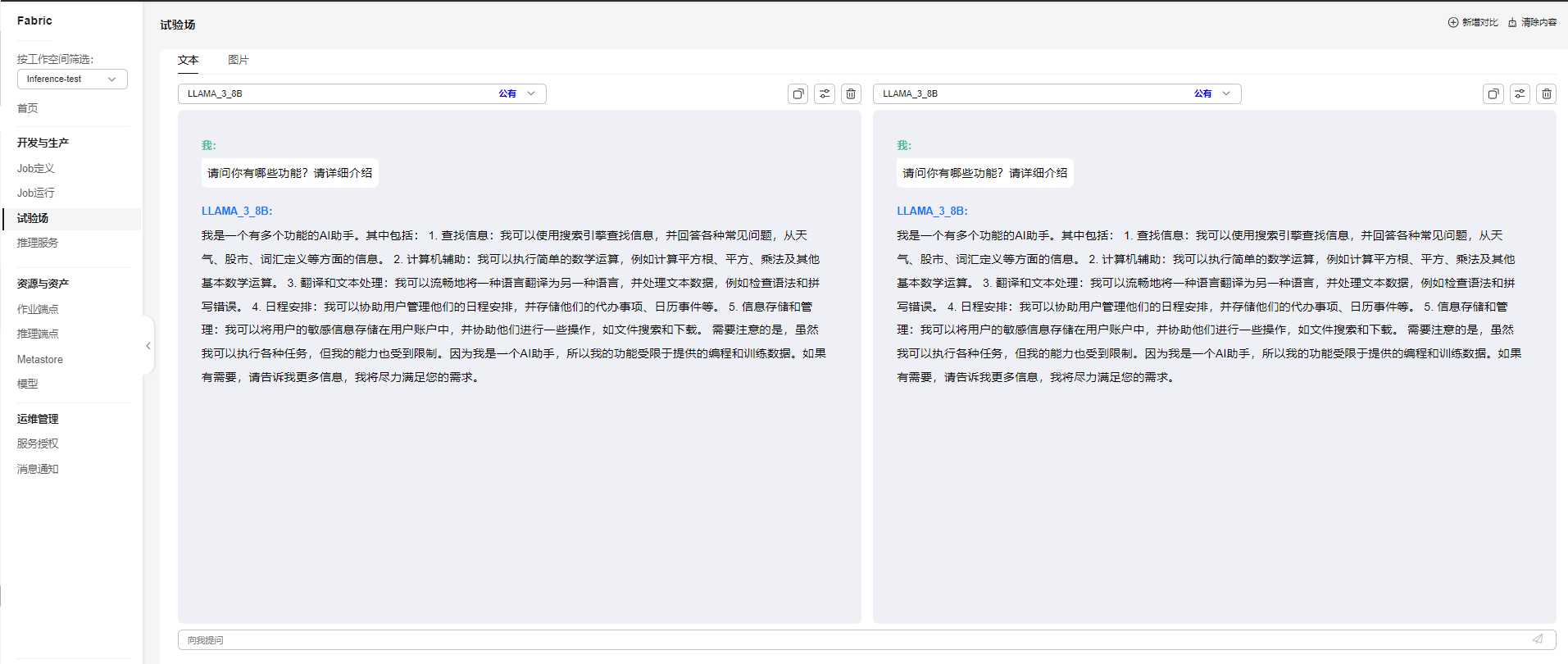
父主题: 使用公共推理服务进行推理




