

更新时间:2025-11-21 GMT+08:00
文本敏感数据识别概述
从海量数据中自动发现并分析敏感数据使用情况,基于数据识别引擎,对OBS中的非结构化数据进行扫描,自动识别敏感和个人隐私数据并进行分类分级。
- 文件类型:支持近200种非结构化文件,详情请参见DSC支持识别的非结构化文件类型。
- 数据类型:支持数十种个人隐私数据类型,包含中英文。
- 支持自定义规则,场景适配不同行业。
- 提供可视化识别结果,同时,可供用户下载到本地查看。
使用流程
图1 流程图
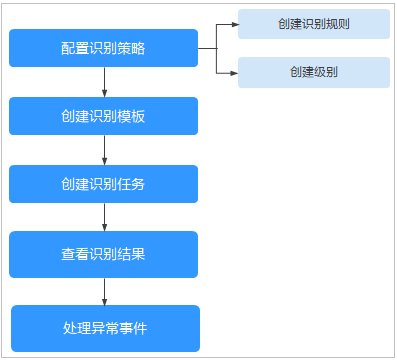
| 功能 | 描述 | 相关操作 |
|---|---|---|
| 识别规则 | 拥有华为云计算公司数据安全内置的规则可供使用,同时可以自定义新的规则,将零散的数据按照识别规则进行分类,是创建识别模板必须的配置项。 | |
| 级别配置 | 拥有华为云计算公司数据安全内置的级别可供使用,同时可以自定义新的级别,将每条规则进行分级。 | |
| 识别模板 | 拥有参考华为云计算公司数据安全分类分级标准和最佳实践内置的模板供使用,同时可以自定义新的分类分级模板,将多个零散的规则进行统一分级分类管理,是创建识别任务必须的配置项。 | |
| 识别任务 | 数据安全中心会根据创建的识别任务,在选定的OBS桶的指定范围中,自动识别敏感数据并生成识别数据和结果。 | |
| 查看或下载识别结果 | 识别任务扫描完成后,可在识别任务列表查看识别结果,也可将识别结果下载到本地查看。 |




