

更新时间:2025-05-12 GMT+08:00
插入数据
功能描述
将SELECT查询结果或某条数据插入到表中。
约束限制
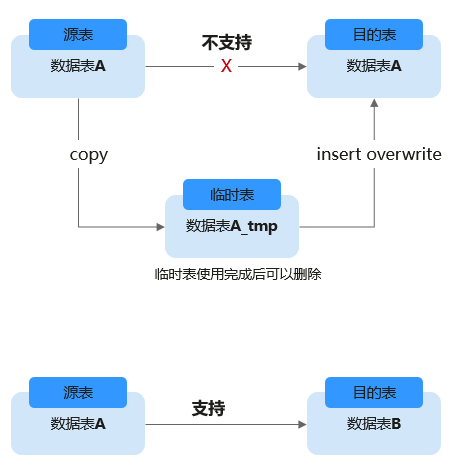
- insert overwrite语法不适用于同一张表内部的“自读自写”场景(包括分区表和非分区表),直接在原表上执行insert overwrite可能会导致数据丢失或数据不一致的风险。
如果要实现“自读自写”场景数据操作,建议使用一个临时表来处理数据。如图1所示。
"自读自写"即目的表和数据源表都是同一张表。例如,假设将student表中class_no = 1的学生信息提取出来并覆盖原表,以下语句即为自读自写场景典型语句。
INSERT OVERWRITE TABLE student SELECT name FROM student WHERE class_no = 1;
- 使用Hive和Datasource(除Hudi外)表在执行数据修改类命令(例如insert into,load data)时由于数据源不支持事务性,在系统故障或队列资源重启后,可能会导致数据重复或数据不一致等问题。
为了避免这种情况,建议优先选择支持事务性的数据源,如Hudi类型数据源,该类数据源具备ACID(Atomicity、Consistency、Isolation、Durability)能力,有助于确保数据的一致性和准确性。
语法格式
- 将SELECT查询结果插入到表中
1 2
INSERT INTO [TABLE] [db_name.]table_name [PARTITION part_spec] select_statement;
1 2
INSERT OVERWRITE TABLE [db_name.]table_name [PARTITION part_spec] select_statement;
part_spec: : (part_col_name1=val1 [, part_col_name2=val2, ...])
- 将某条数据插入到表中
1 2
INSERT INTO [TABLE] [db_name.]table_name [PARTITION part_spec] VALUES values_row [, values_row ...];
1 2
INSERT OVERWRITE TABLE [db_name.]table_name [PARTITION part_spec] VALUES values_row [, values_row ...];
values_row: : (val1 [, val2, ...])
关键字
| 参数 | 描述 |
|---|---|
| db_name | 需要执行INSERT命令的表所在数据库的名称。 |
| table_name | 需要执行INSERT命令的表的名称。 |
| part_spec | 指定详细的分区信息。若分区字段为多个字段,需要包含所有的字段,但是可以不包含对应的值,系统会匹配上对应的分区。单表分区数最多允许100000个。 |
| select_statement | 源表上的SELECT查询(支持DLI表、OBS表)。 |
| values_row | 想要插入到表中的值,列与列之间用逗号分隔。 |
注意事项
- 表必须已经存在。
- 如果动态分区不需要指定分区,则将“part_spec”作为普通字段放置SELECT语句中。
- 被插入的OBS表在建表时只能指定文件夹路径。
- 源表和目标表的数据类型和列字段个数应该相同,否则插入失败。
- 不建议对同一张表并发插入数据,可能会由于并发冲突导致插入数据结果异常。
- INSERT INTO命令用于将查询的结果追加到目标表中。
- INSERT OVERWRITE命令用于覆盖源表中已有的数据。
- INSERT INTO命令可以并行执行,INSERT OVERWRITE命令只有在分区表下不同的插入到不同静态分区才可以并行。
- INSERT INTO命令和INSERT OVERWRITE命令同时执行,其结果是未知的。
- 在从源表插入数据到目标表的过程中,无法在源表中导入或更新数据。
- 对于Hive分区表的动态INSERT OVERWRITE,支持覆盖涉及到的分区数据,不支持覆盖整表数据。
- 如果需要覆盖DataSource表指定分区数据,需要先配置参数:dli.sql.dynamicPartitionOverwrite.enabled=true,再通过“insert overwrite”语句实现,“dli.sql.dynamicPartitionOverwrite.enabled”默认值为“false”,表示覆盖整表数据。例如:
1insert overwrite table tb1 partition(part1='v1', part2='v2') select * from ...

在“数据湖探索管理控制台>SQL编辑器”页面,单击编辑窗口右上角“设置”,可配置参数。
- 通过配置“spark.sql.shuffle.partitions”参数可以设置非DLI表在OBS桶中插入的文件个数,同时,为了避免数据倾斜,在INSERT语句后可加上“distribute by rand()”,可以增加处理作业的并发量。例如:
insert into table table_target select * from table_source distribute by cast(rand() * N as int);
示例
- 示例1:将SELECT查询结果插入到表中
- 使用DataSource语法创建一个parquet格式的分区表
CREATE TABLE data_source_tab1 (col1 INT, p1 INT, p2 INT) USING PARQUET PARTITIONED BY (p1, p2);
- 插入查询结果到分区 (p1 = 3, p2 = 4)中
INSERT INTO data_source_tab1 PARTITION (p1 = 3, p2 = 4) SELECT id FROM RANGE(1, 3);
- 插入新的查询结果到分区 (p1 = 3, p2 = 4) 中
INSERT OVERWRITE TABLE data_source_tab1 PARTITION (p1 = 3, p2 = 4) SELECT id FROM RANGE(3, 5);
- 使用DataSource语法创建一个parquet格式的分区表
- 示例2:将某条数据插入表中
- 使用Hive语法创建一个parquet格式的分区表
CREATE TABLE hive_serde_tab1 (col1 INT, p1 INT, p2 INT) USING HIVE OPTIONS(fileFormat 'PARQUET') PARTITIONED BY (p1, p2);
- 插入两条数据到分区 (p1 = 3, p2 = 4)中
INSERT INTO hive_serde_tab1 PARTITION (p1 = 3, p2 = 4) VALUES (1), (2);
- 插入新的数据到分区 (p1 = 3, p2 = 4) 中
INSERT OVERWRITE TABLE hive_serde_tab1 PARTITION (p1 = 3, p2 = 4) VALUES (3), (4);
- 使用Hive语法创建一个parquet格式的分区表
执行Insert into后数据重复怎么办?
- 问题现象:
使用Hive和Datasource(除Hudi外)表在执行数据修改类命令(例如insert into,load data)时由于数据源不支持事务性,在系统故障或队列资源重启后,可能会导致数据重复或数据不一致等问题。
- 原因分析:
在数据的Commit阶段如果出现队列资源重启可能会导致数据已经被修复到正式目录中。如果执行的是Insert into语句,资源重启后触发重试就会有概率导致数据重复写入。
- 解决方案:
- 推荐使用具备ACID能力的Hudi类型数据源。
- 建议尽量使用insert overwrite这样幂等的语法而不是insert into等非幂等语法插入数据。
- 如果严格需求数据不能重复,建议在insert into后对表数据执行去重操作,防止数据重复。
父主题: 数据相关




