

更新时间:2024-12-03 GMT+08:00
创建盘古NLP大模型SFT任务
场景描述
此示例演示了如何从头创建SFT(有监督微调)训练任务。通过该示例,您将了解以下内容:
- 如何将数据导入平台并进行数据加工、标注和评估操作。
- 如何创建SFT训练任务并配置训练参数,以提升文本理解和生成的质量。
- 如何执行模型的压缩和部署操作。
准备工作
- 请提前准备文本类数据,文本类数据集格式要求请详见《用户指南》“使用数据工程准备与处理数据集 > 数据集格式要求 > 文本类数据集格式要求”。
- 上传文本类数据至OBS服务,上传步骤请详见通过控制台快速使用OBS。
操作流程
盘古NLP大模型SFT任务创建流程见表1。
|
操作步骤 |
说明 |
|---|---|
|
本样例场景实现将存储在OBS的文本数据导入至盘古平台,并上线为原始数据集。 |
|
|
本样例场景帮助用户利用数据集加工算子处理原始数据集。 |
|
|
本样例场景帮助用户高效完成数据标注任务,提升标注数据的可靠性和可用性。 |
|
|
本样例场景帮助用户利用数据集评估标准评估和优化数据质量。 |
|
|
本样例场景实现将处理好的数据集发布为模型训练可用的数据集。 |
|
|
本样例场景实现NLP大模型的训练操作。 |
|
|
本样例场景实现NLP大模型的压缩操作。压缩是指通过减少模型的参数量或计算复杂度,在尽量保持模型性能的前提下,减小其存储需求和推理时间,从而提升模型的部署效率,尤其在资源受限的环境中具有重要意义。常见的压缩方法包括剪枝、量化、知识蒸馏等。 |
|
|
本样例场景实现NLP大模型的部署操作。 |
步骤1:导入数据至盘古平台
- 登录ModelArts Studio大模型开发平台,进入所需空间。
- 选择左侧“数据工程 > 数据获取”,单击右上角“创建原始数据集”。
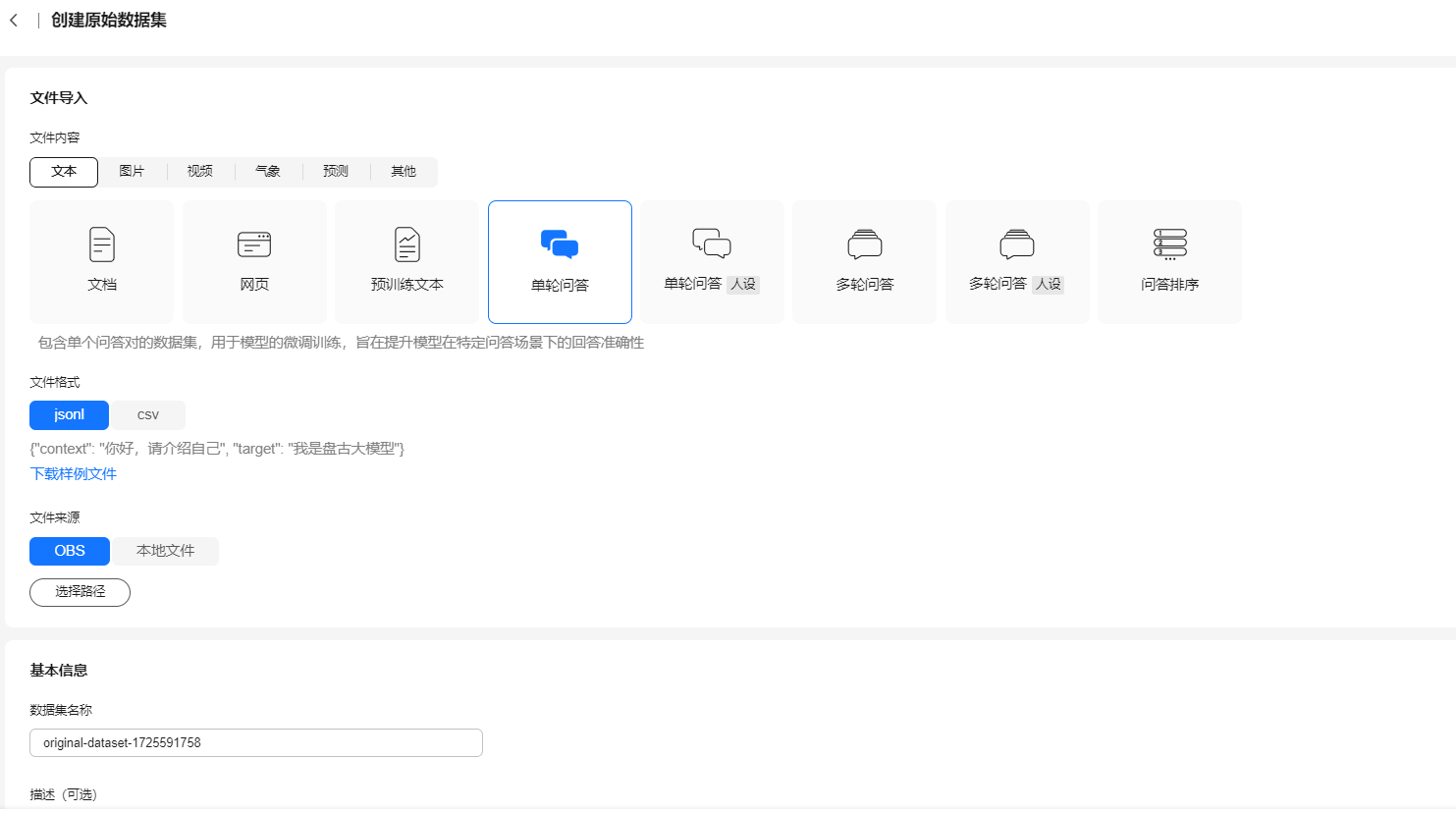
- 在“创建原始数据集”页面,选择“文本 > 单轮问答”,选择文件格式、文件来源,填写数据集名称及描述,单击“立即创建”。
图1 创建原始数据集
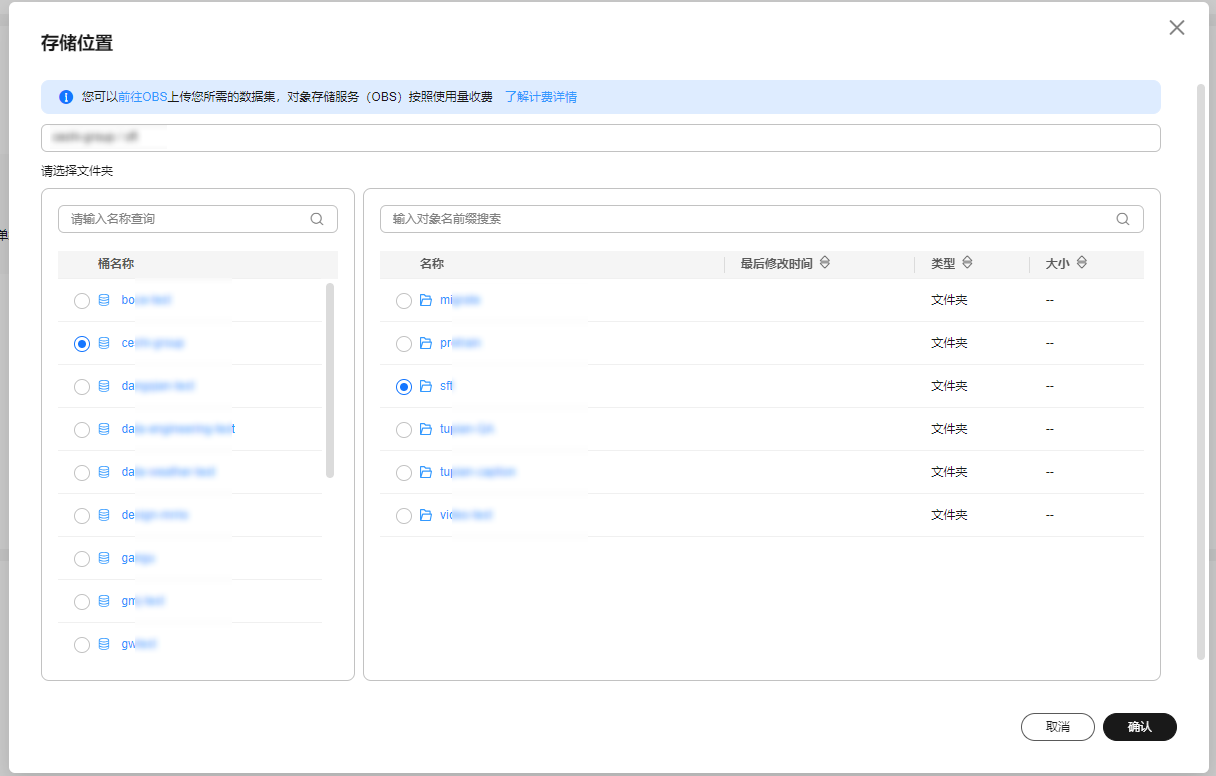
- 单击“选择路径”,在“存储位置”弹窗中选择需导入的数据,单击“确认”。
图2 选择导入的数据
- 数据集信息设置完成后,填写“数据集名称”和“描述”,并设置“拓展信息”。
- 标签设置。通过标签设置,可以给数据集添加行业、语言、标签信息。
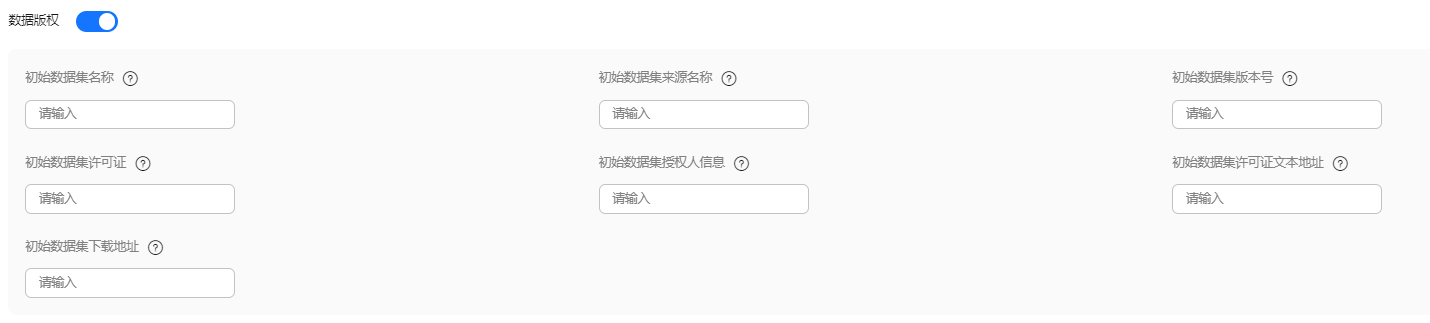
- 数据版权设置。训练模型的数据集除用户自行构建外,也可能会使用开源的数据集。数据版权功能主要用于记录和管理数据集的版权信息,确保数据的使用合法合规,并清晰地了解数据集的来源和相关的版权授权。通过填写这些信息,可以追溯数据的来源,明确数据使用的限制和许可,从而保护数据版权并避免版权纠纷。
图3 设置数据版权
- 单击页面右下角“立即创建”完成原始数据集的创建操作。创建成功的数据集的任务状态为“成功”,单击操作列的“上线”按钮,将该数据集上线,用于后续加工操作。
步骤2:加工文本类数据集
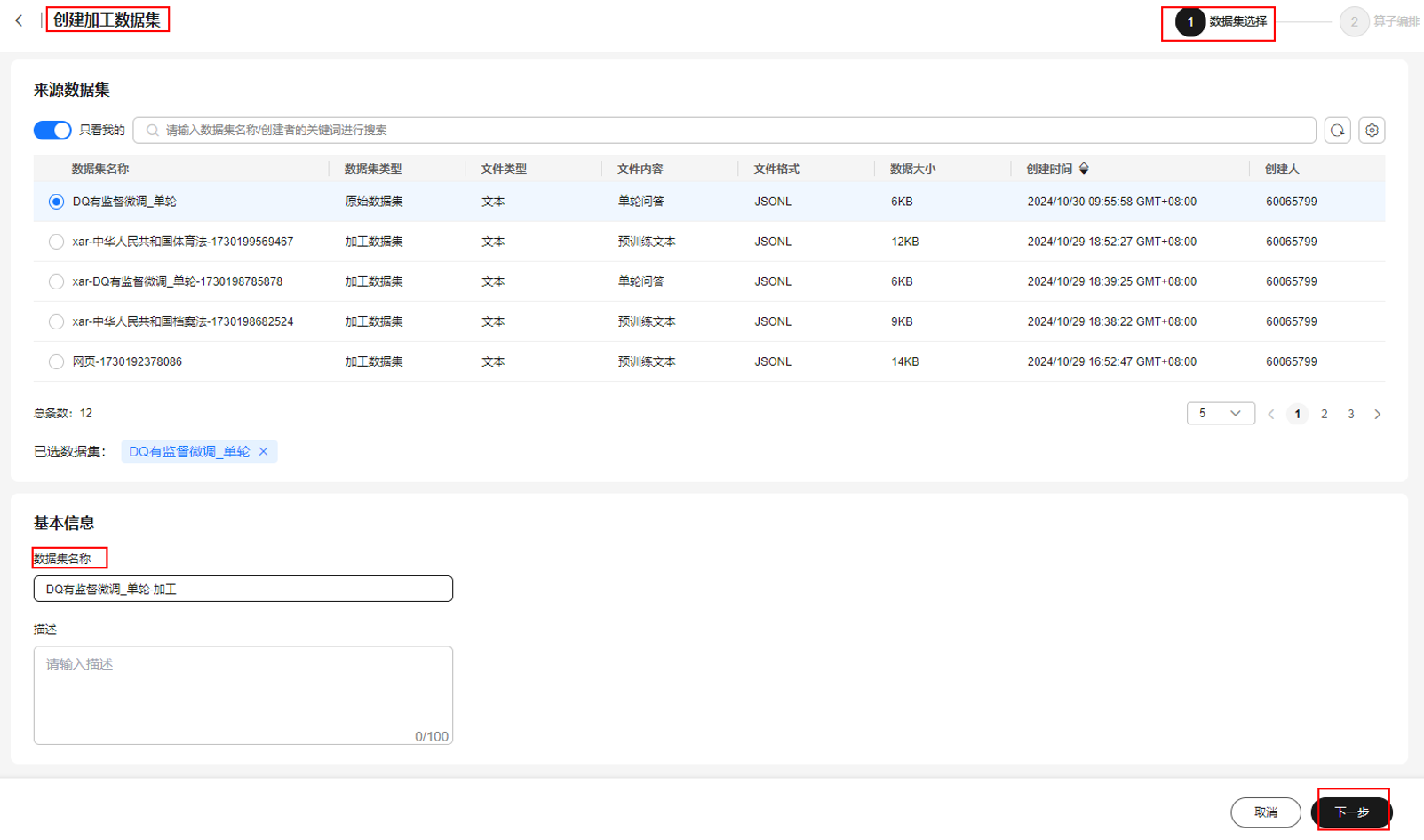
- 选择左侧“数据工程 > 数据加工”,单击右上角“创建加工数据集”。
- 在“创建加工数据集”页面,选择步骤1中创建好的原始数据集,填写数据集名称及描述,单击“下一步”。
图4 创建加工数据集
- 在左侧算子列表中添加相应的数据加工算子,单击“立即执行”。
图5 加工算子编排
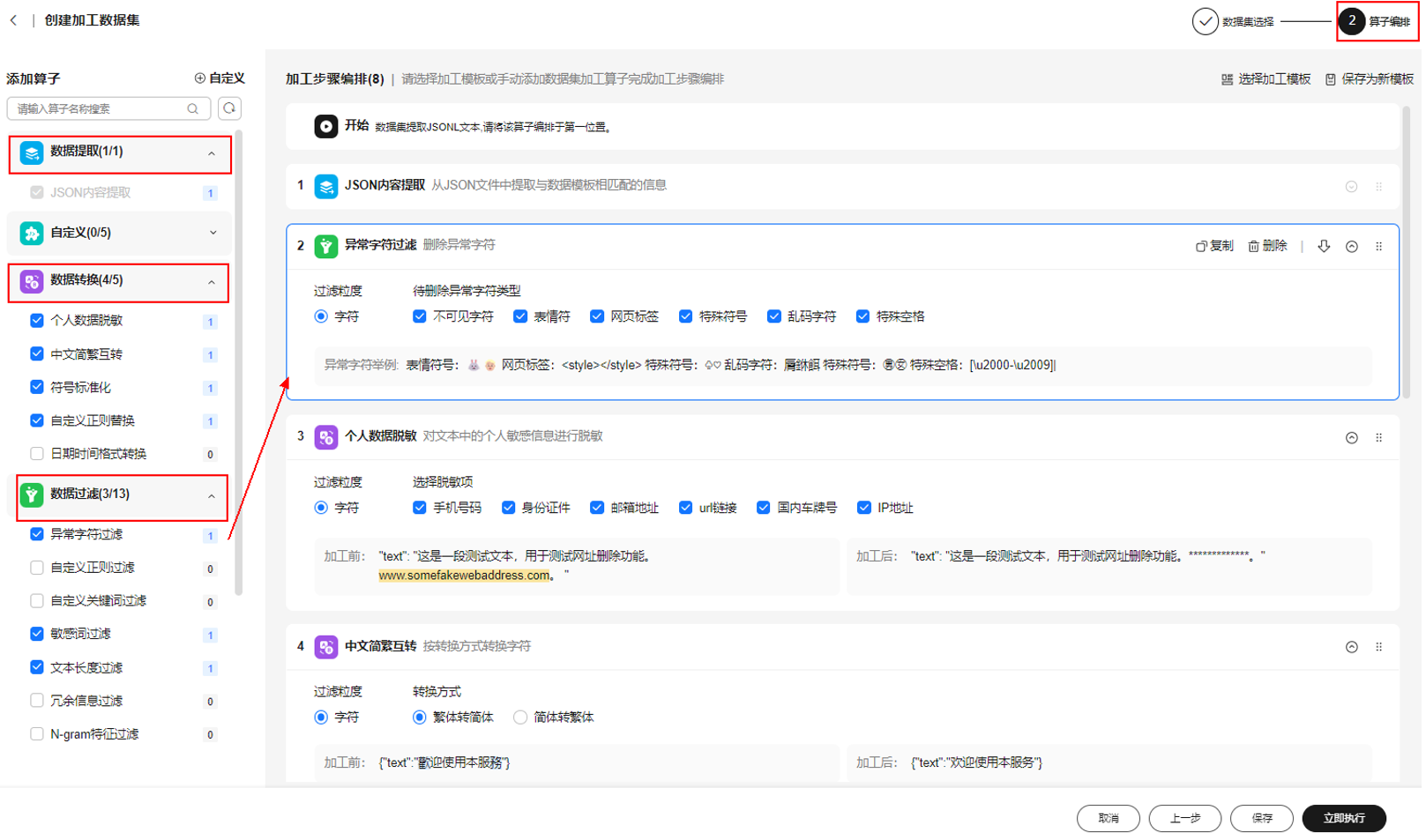
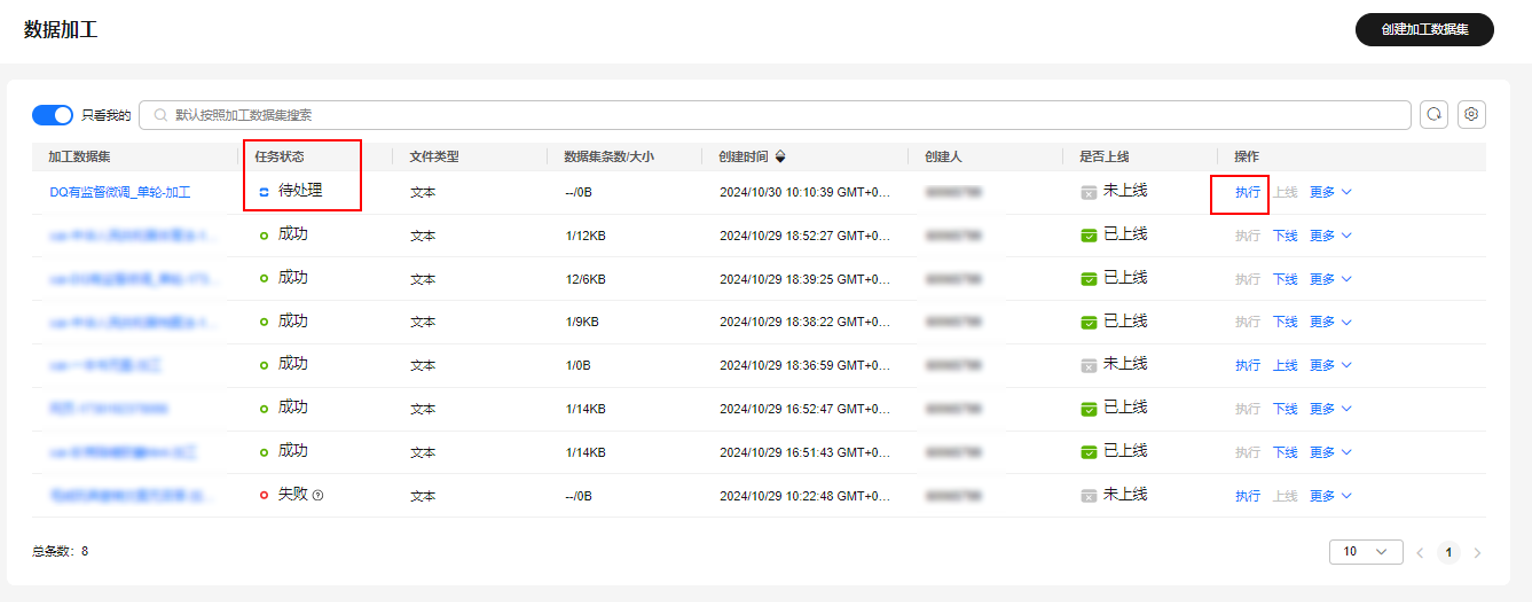
- 单击“执行”,开始执行加工任务,加工成功的数据集的任务状态为“成功”,单击“上线”,用于后续标注操作。
图6 上线加工后的数据集
步骤3:标注文本类数据集
- 选择左侧“数据工程 > 数据标注 > 标注管理”,单击右上角“创建标注任务”。
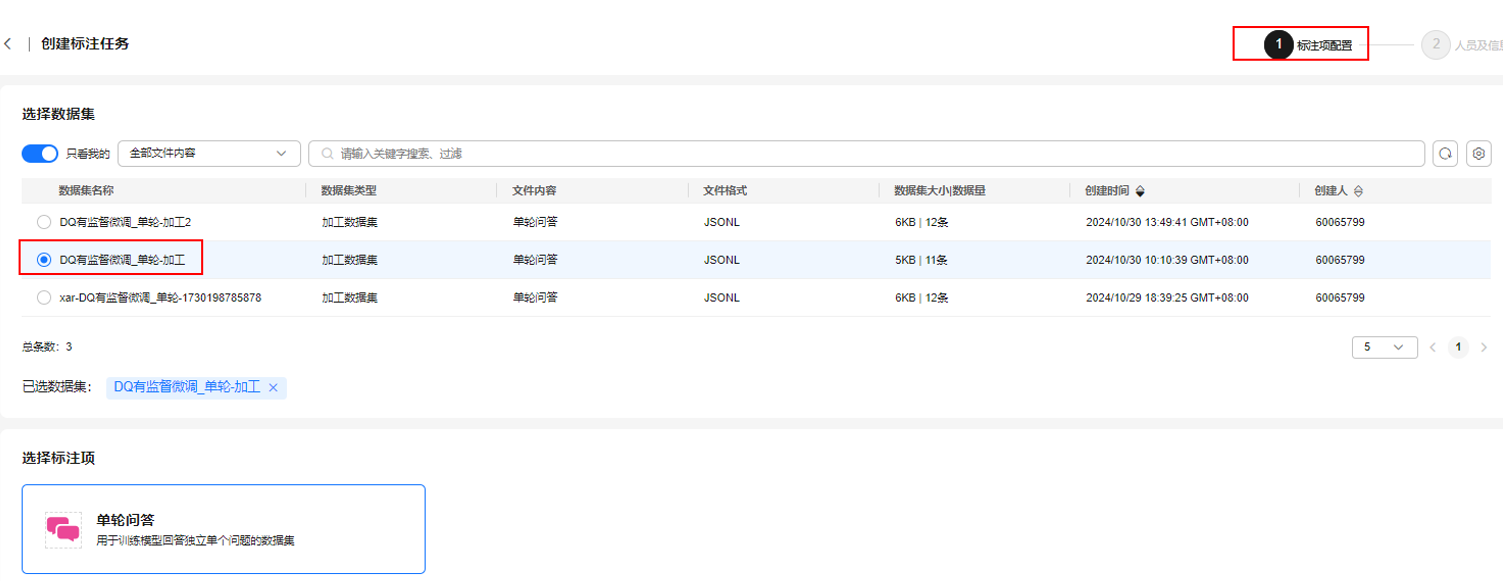
- 在“创建标注任务”页面,选择步骤2:加工文本类数据集中加工好的数据集,选择标注项“单轮问答”,单击“下一步”。
图7 选择加工后的数据集
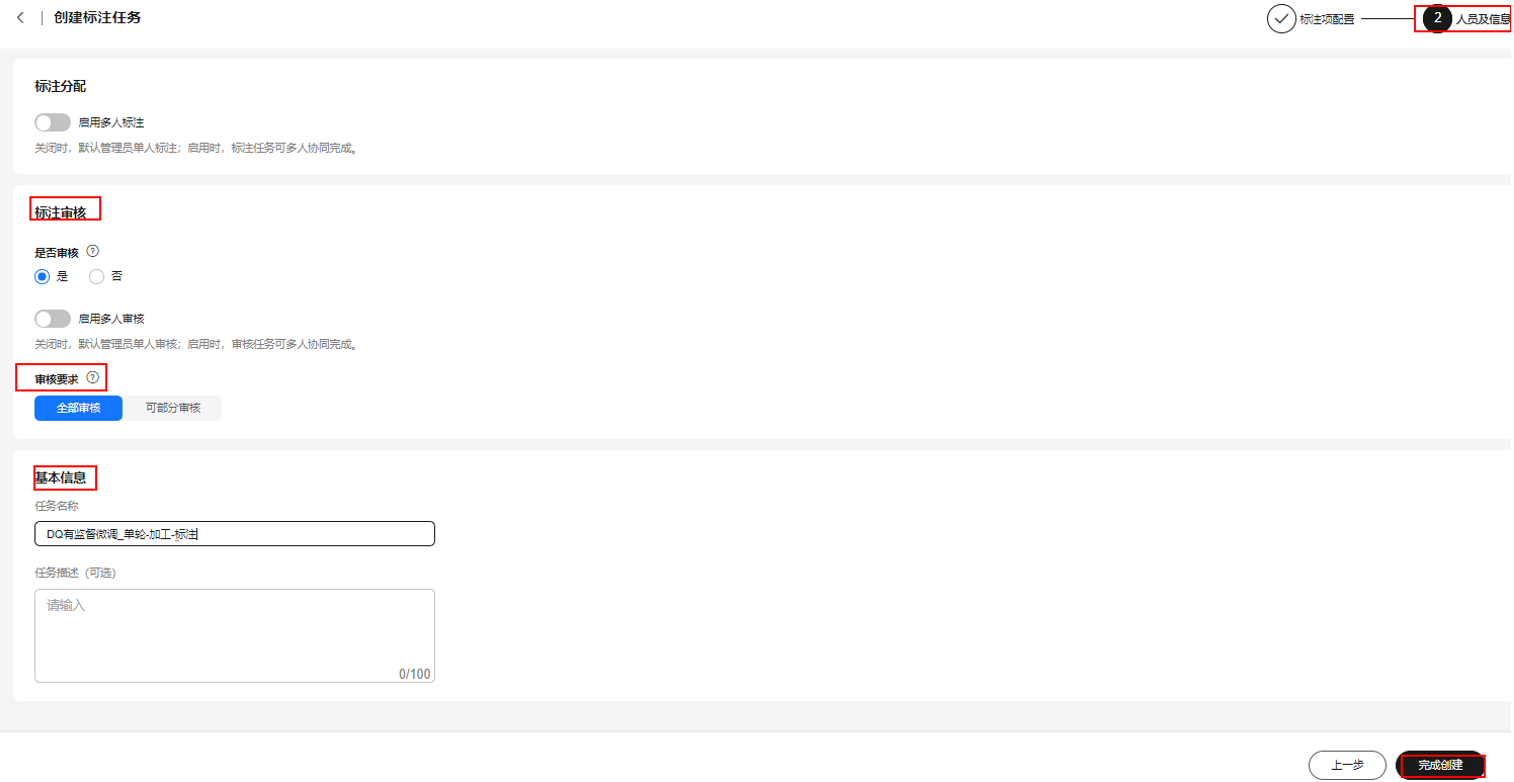
- 配置“标注审核”与“基本信息”,单击“完成创建”。
图8 配置标注审核、基本信息
- 选择左侧导航栏的“数据工程 > 数据标注 > 标注作业”,单击数据集操作列的“标注”,进入数据集的标注页面。
- 在标注页面后,需要逐一确认问题(Q)及答案(A)是否正确,如果问题或答案不正确,可以对其进行二次编辑。
图9 标注页面
- 一条数据标注完成后,单击“提交”按钮可继续标注剩余数据。所有数据标注完成后,页面会出现标注任务成功的提示。
图10 标注任务完成提示
- 创建数据集标注任务时,如果设置了启用标注审核,在完成标注后可以在“标注审核”页面审核标注结果。
图11 标注审核页面
- 在“标注审核”页面,单击操作列“审核”可进入审核页面审核数据。如果需要将该审核任务移交给其他人员,可以单击操作列“移交”设置移交人员以及移交的数量。
图12 移交任务页面
- 进入审核页面后,可通过单击“通过”或“不通过”按钮逐一对数据进行审核,直至所有数据审核完成,期间可对不满足要求的数据进行驳回,驳回后将分给标注人员重新标注。
- 数据集审核无问题后,可在“标注管理”页面对数据集进行上线。
图13 标注管理页面
步骤4:评估文本类数据集
- 选择左侧“数据工程 > 数据评估 > 评估任务”,单击右上角“创建评估任务”。
- 在“创建评估任务”页面,选择数据集,设置抽样规格,单击“下一步”。
图14 创建评估任务
- 根据数据集类型选择评估标准,此处选择“NLP数据质量标准V1.0”,单击“下一步”。
图15 选择评估标准
- 选择评估人员,单击“下一步”。填写“任务名称”,单击“完成创建”,在数据集操作列单击“评估”。
图16 评估任务列表
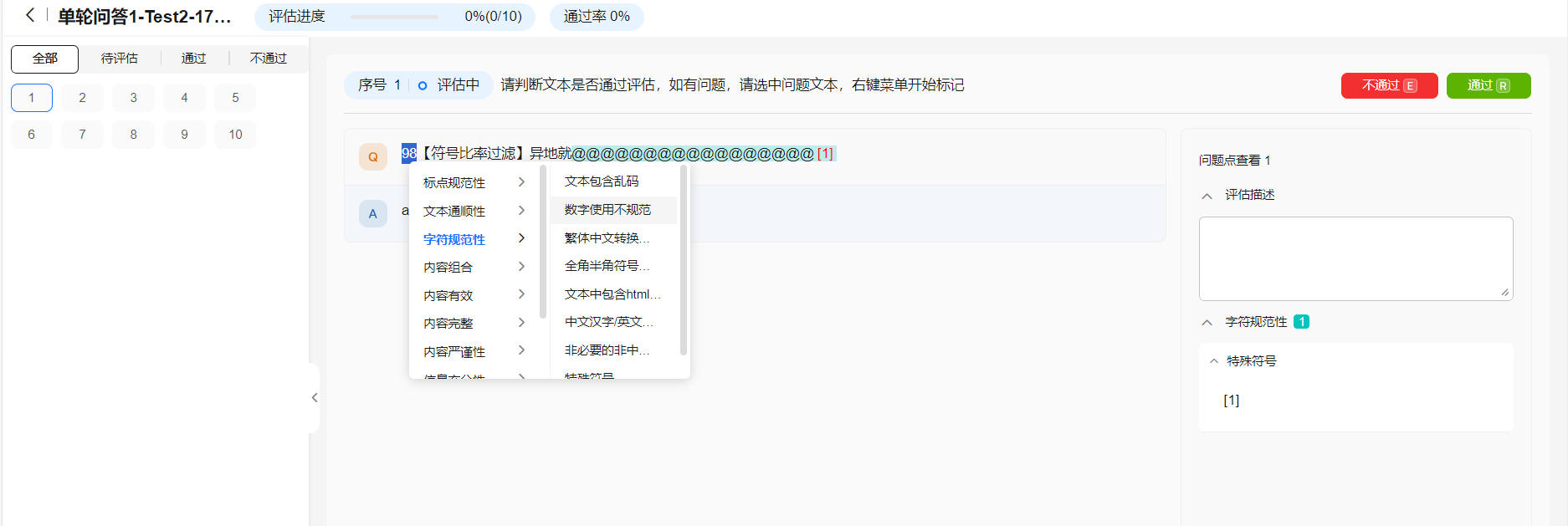
- 在评估页面,可参考评估项对当前数据的问题进行标注,且不满足时需要单击“不通过”,满足则单击“通过”。
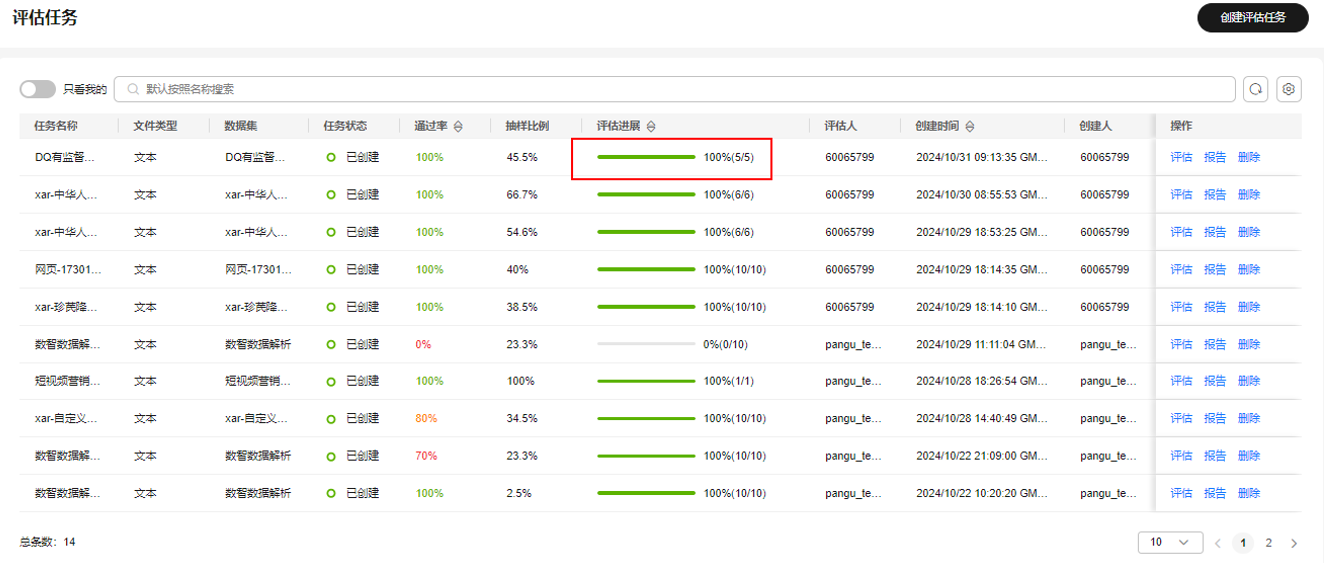
- 全部数据评估完成后,评估状态显示为“100%”,表示当前数据集已经评估完成,可以回退到“评估任务”页面,查看,单击操作列“报告”按钮,获取数据集质量评估报告。
图18 查看评估任务进展
步骤5:发布文本类数据集
- 选择左侧“数据工程 > 数据发布”,单击右上角“创建发布数据集”。
- 在“创建发布数据集”页面,选择“文本 > 单轮问答”,选择“发布方式”为“单个数据集”,选择评估后的数据集,单击“下一步”。
- 选择“格式配置”为“盘古格式”,单击“下一步”。
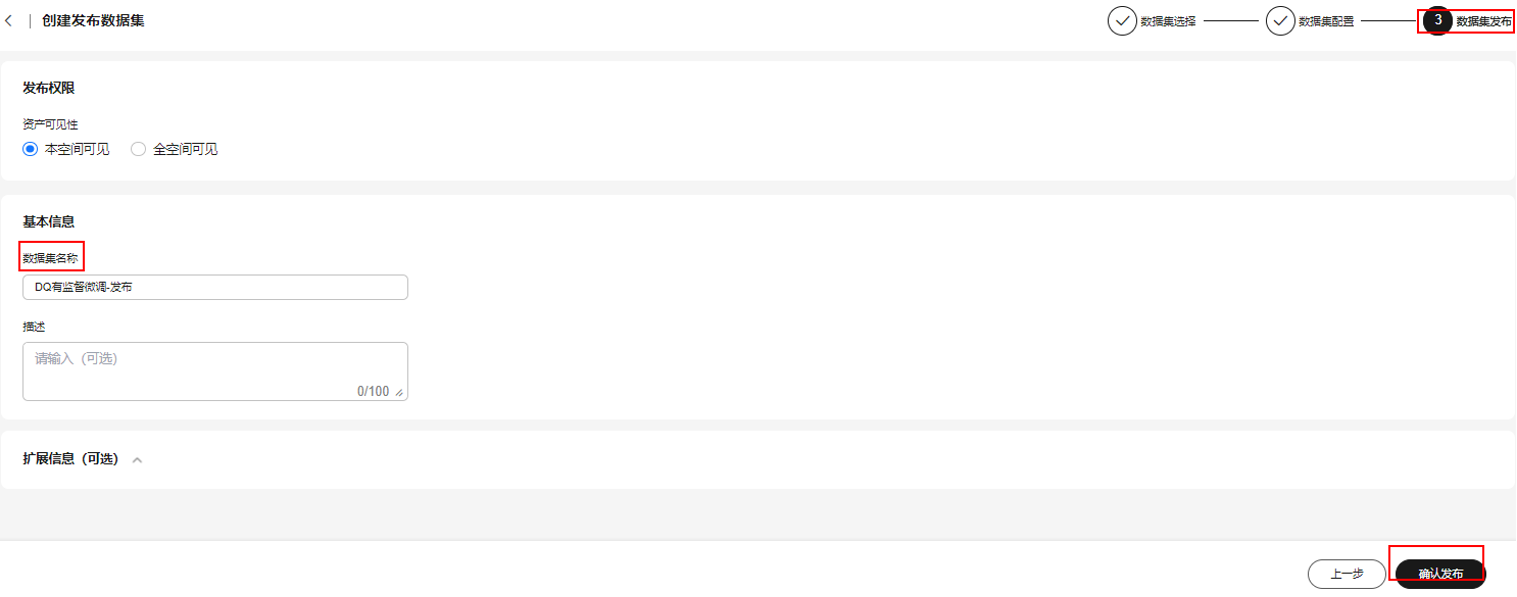
- 选择资产可见性,填写数据集名称,单击“确认发布”。
图19 创建发布数据集
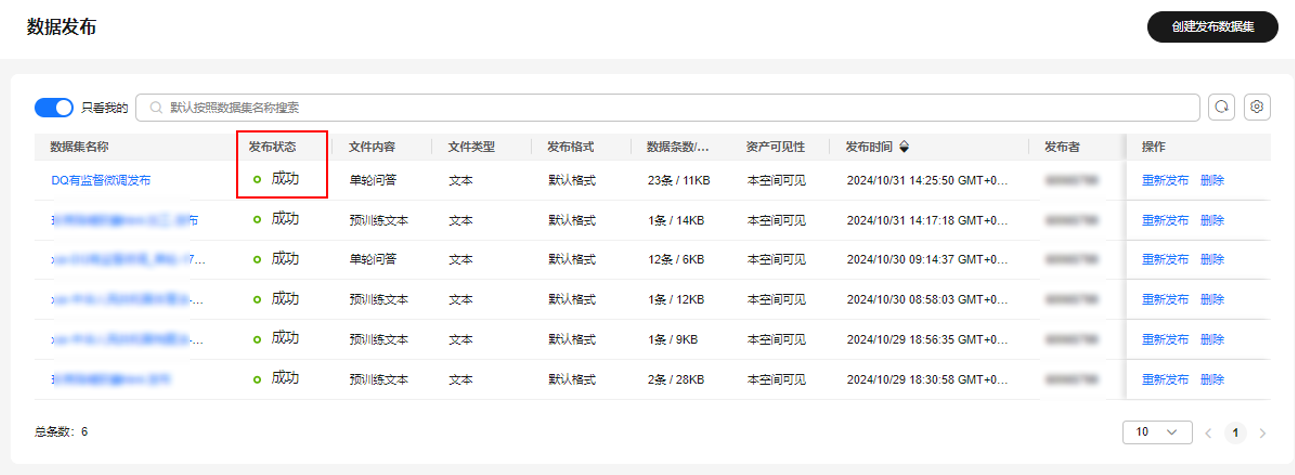
- 发布成功的数据集的发布状态为“成功”,可用于后续的模型训练操作。
图20 查看数据集发布状态
步骤6:训练NLP大模型
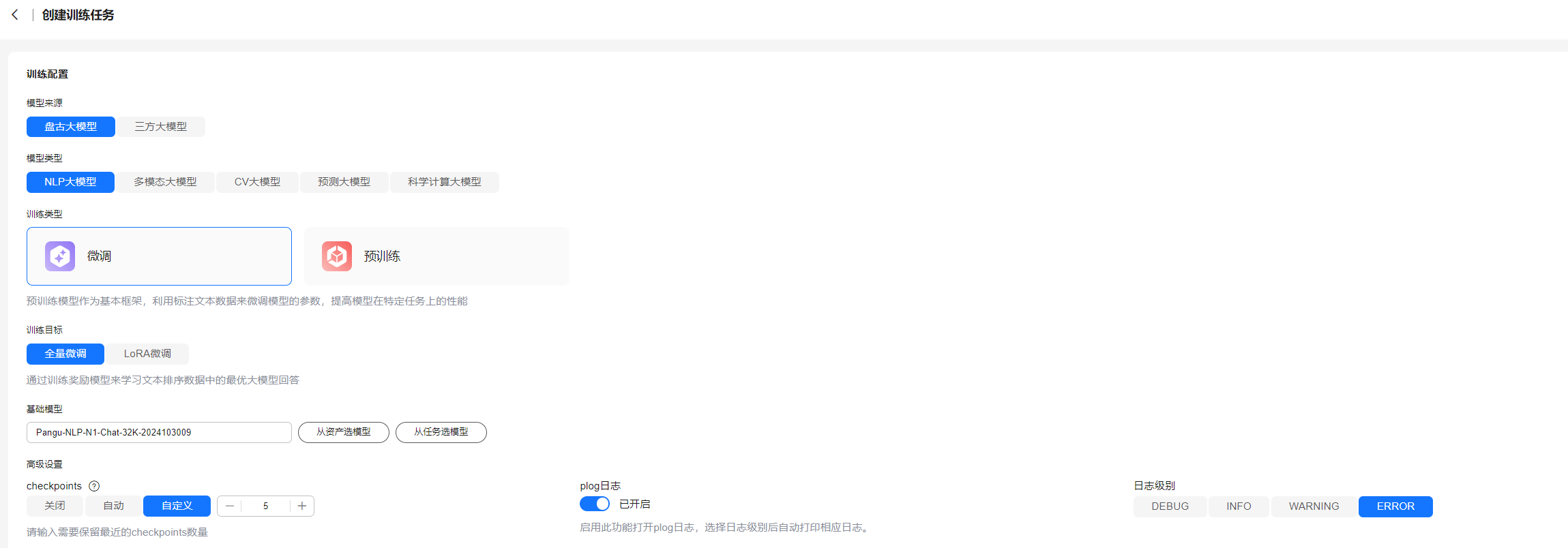
- 选择左侧“模型开发 > 模型训练”,单击右上角“创建训练任务”。
- 在“创建训练任务”页面,依次选择“盘古大模型 > NLP大模型 > 微调 > 全量微调”。
- 在“基础模型”中,选择“从资产选模型 > 预置”,选择所需NLP大模型,单击“确定”。
- 在“高级设置”中,依次配置checkpoints、plog日志以及日志级别。
图21 创建训练任务页面
- 在“训练参数”中,平台已经预置了默认的模型参数,也可根据需求自行修改。
- 在“数据配置”中选择训练数据集。填写基本信息后,单击“立即创建”。
- 创建好训练任务后,自动返回至“模型训练”页面,模型将自动开始训练,训练完成后的任务状态为“已完成”。
步骤7:压缩NLP大模型
- 在左侧导航栏中选择“模型开发 > 模型压缩”,单击界面右上角“创建压缩任务”。
- 在“创建压缩任务”页面,单击“从资产选模型”,选择步骤6:训练NLP大模型步骤中训练好的大模型,选择压缩策略,填写任务名称、压缩后模型名称及描述。
- 参数填写完成后单击“立即创建”创建模型压缩任务。
步骤8:部署NLP大模型
- 在左侧导航栏中选择“模型开发 > 模型部署”,单击“创建部署”。
- 在“创建部署”页面,选择“盘古大模型 > NLP大模型”,单击“从资产选模型”,选择步骤7:压缩NLP大模型步骤中压缩后的模型。
- 选择部署方式“云上部署”,选择最大TOKEN长度,如“4096”,选择架构类型“ARM”。
- 在“资源配置”中配置实例数,如“1”,“安全护栏”功能已默认开启。
- 填写服务名称及描述,单击“立即部署”,启动模型部署。





