

DataArts Fabric SQL
DataArts Fabric SQL介绍
DataArts Fabric SQL是一个全托管式数据平台,利用华为云基础设施提供的资源池化和海量存储能力,结合并行执行、元数据解耦、计算持久化分离架构,实现了极致弹性和湖仓一体等能力,提供先进软件及服务(SaaS)技术。全新的无服务器架构可以让您在使用SQL语言处理组织复杂业务时,无需管理基础架构。
DataArts Fabric SQL架构基于华为云DataArts Fabric平台,主要由服务接入层、计算层与存储层组成。平台实现了元数据服务、计算、缓存和存储的分层解耦和弹性,让每一层动态分配资源而不会影响另一层的性能或可用性。语句级别的弹性扩缩、高性能分布式分析引擎可帮助您在几秒钟内查询TB级别数据,在几分钟内查询PB级别数据。
DataArts Fabric SQL支持加工和分析Iceberg、ORC、Parquet等开放结构化数据格式,支持开放湖生态,让您可以在使用多个数据湖生态服务时共享同一份数据。
DataArts Fabric SQL积极拥抱Data+AI生态并提供了Python UDF特性,支持用户在SQL中直接运行Python脚本,使能一站式AI数据处理;
DataArts Fabric SQL提供可视化界面,并提供JDBC驱动,方便与现有应用和第三方工具交互。同时提供REST API接口和Python API接口,方便开发者使用熟悉的编程语言转换和管理数据。
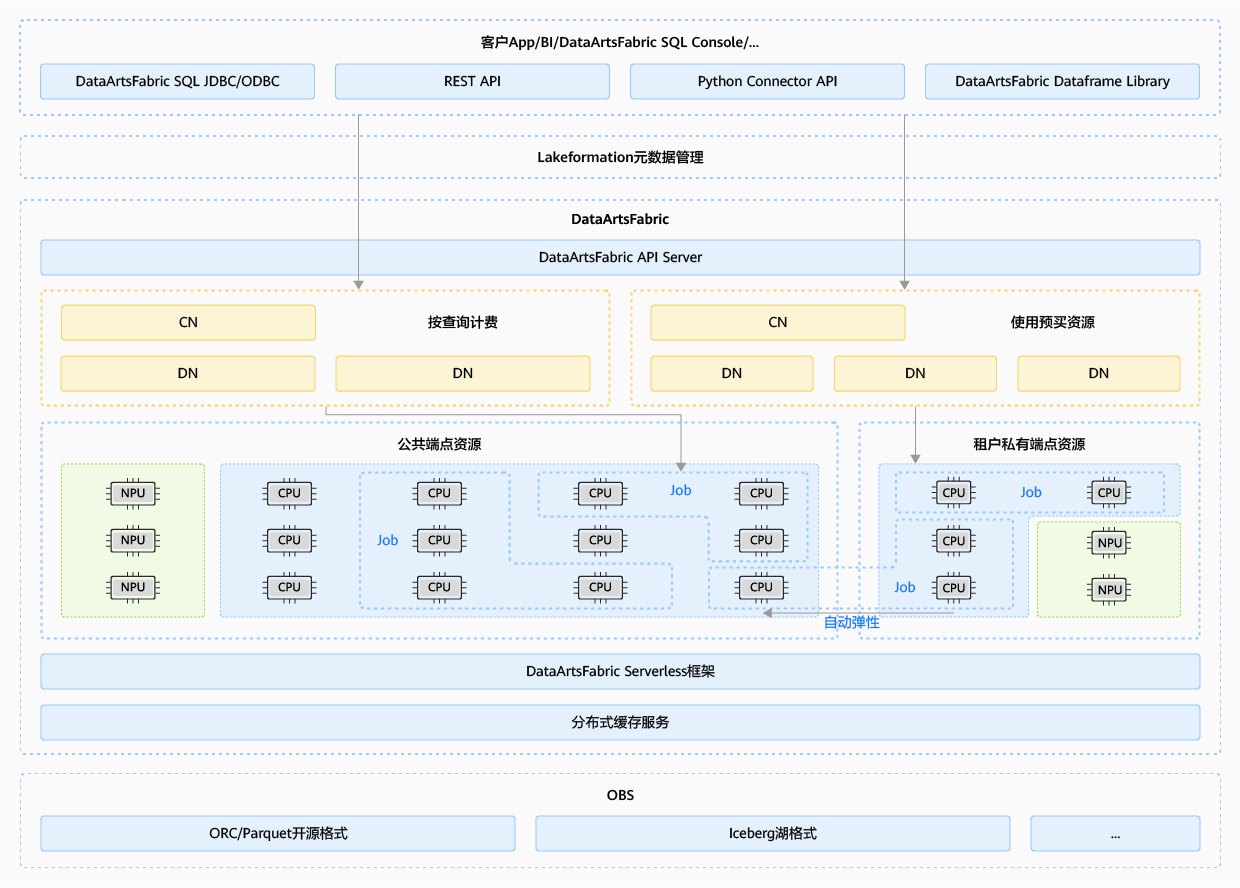
DataArts Fabric SQL功能介绍
下表介绍了DataArts Fabric SQL的关键功能。
| 特性 | 特性及规格描述 |
|---|---|
| 支持标准SQL语法 | 基于ANSI标准SQL规范扩展,支持GBK、UTF-8、SQL ASCII以及Latin-1字符集。 |
| DDL | 支持SCHEMA、TABLE的Create/Alter/Drop/Show/Describe。 |
| 数据类型 | 支持smallint, int, bigint, float, double, numeric, timestamp, date, varchar, char, bool, binary, string。 |
| 应用程序接口 | 标准JDBC 4.0、Restful API、Python Connector API。 |
| 事务能力 | 支持分区级别事务能力,支持并发控制。 ICEBERG支持完整的事务能力。 |
| 多租户 | 不同租户通过不同的CN/DN隔离,CN/DN通过独占POD来进行隔离。 |
| 数据导入导出 | 数据导入通过INSERT INTO导入,导出也通过insert into。从外表导出外表,格式转换支持:Parquet/ORC -> Parquet/ORC。 |
| 弹性能力 | 支持两级弹性,资源池内根据查询特征秒级弹性计算单元(节点弹性速度秒级<2s),根据资源水位线触发额外计算资源扩缩容。 说明: Beta特性,扩容操作需要通过管控面触发DataArts Fabric服务购买容器。 |
| SMP | 提供节点内SMP并行计算能力,充分利用多核CPU资源,默认开启query_dop。 |
| 向量化执行 | 向量化执行引擎,提升OLAP性能。 |
| 统计信息搜集 | Analyze完成统计信息搜集,提升优化器评估精度,确保数据库性能稳定高效。 |
| 存储格式支持 | 支持PARQUET/ORC/Iceberg格式。 |
| DML支持 | 支持Insert Into/Insert Overwrite。 |
| 分区表 | PARQUET/ORC/Iceberg均支持分区表。 |
| 视图 | 支持视图。 |
| 用户自定义函数(UDF) | 支持用户以自定义函数的方式扩展SQL并统一执行,当前编程语言仅支持Python。 |
| 弹性计算规模 | 单查询最大规模256 弹性计算节点。 |
| 细粒度访问控制 | 表元数据由LakeFormation管理,使用IAM权限管理,当前由Lakeformation负责整体的权限控制。 |




