

ClickHouse基本原理
ClickHouse简介
ClickHouse为您提供方便易用、灵活稳定的云端ClickHouse托管服务。只需要几分钟,便可完成海量数据查询数据仓库的搭建,简单轻松地完成对数据的实时查询分析,提升数据价值挖掘的整体效率。云数据仓库ClickHouse是一种基于MPP(大规模并行处理)架构的数仓服务,基于ClickHouse优异的查询性能,查询效率数倍于传统数据仓库。
ClickHouse原理
ClickHouse是一个完全的列式分布式数据库管理系统(DBMS),主要用于在线分析处理查询(OLAP),能够使用SQL查询实时生成分析数据报告,允许在运行时创建表和数据库,加载数据和运行查询,简单方便,高可靠性,容错性强。通过MPP架构,分布式运算,历史存储等特性,提供了高性能的数据查询性能。
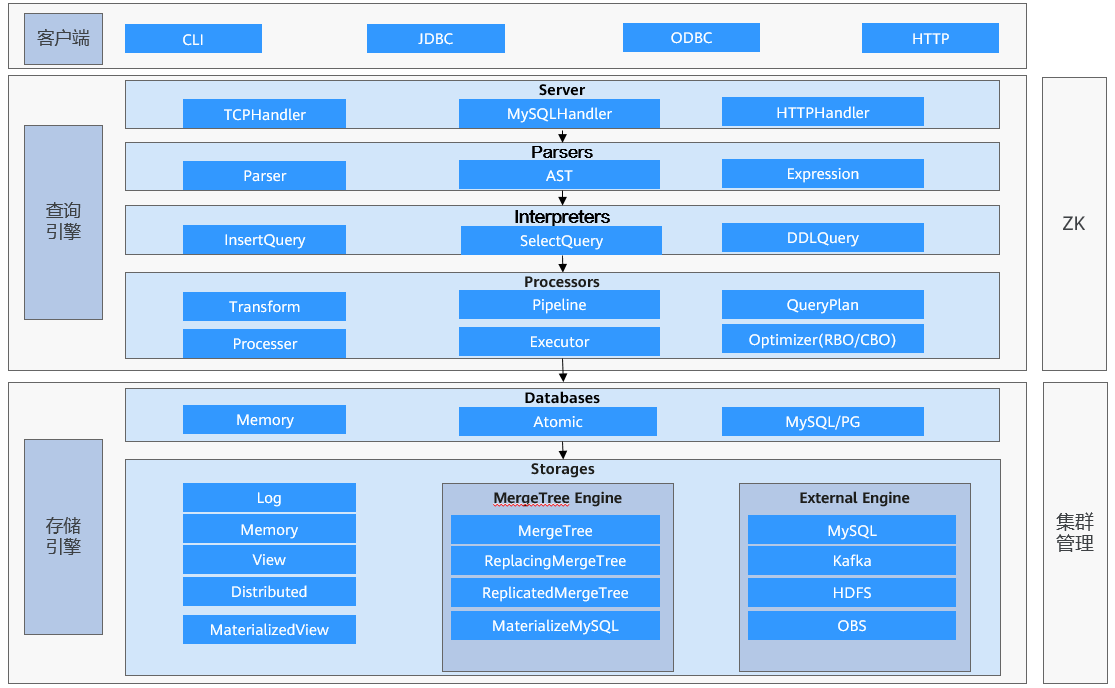
| 名称 | 描述 |
|---|---|
| MergeTree | 是ClickHouse最常用的存储引擎,适用于需要高效插入数据和查询的场景。通过将数据分割成多个部分(part)并合并(merge)来优化查询性能。主要支持分区(Partitioning)、排序键(Sorting keys)、主键(Primary keys)、二级索引(Secondary indexes)等。 |
| 查询引擎 | ClickHouse采用MPP架构与向量化执行引擎,显著提升复杂分析查询性能。任务下发到集群后执行流程包含三个并行层级:
|
| 存储引擎 | ClickHouse采用列式存储设计,将同类型数据按列独立存储。这种结构适合分析场景,能够高效地读取查询所需的列,减少开销且提升查询性能。 |
| MaterializedView | 物化视图 (Materialized View)是数据库中用于优化查询性能的物理表,通过预计算并存储复杂查询结果来减少重复计算。与传统视图不同,物化视图将查询结果持久化存储,可直接访问以提高查询效率。 |
| RBO | RBO通过预定义的逻辑规则(Logical Rules)和物理规则(Physical Rules)对查询计划进行转换和优化。这些规则在保证查询结果正确性的前提下,重构执行逻辑,显著提升查询性能。 |
| CBO | 基于代价的优化(CBO)是查询优化器的核心组件,通过分析统计信息动态选择最优执行计划。相比基于规则的优化(RBO),CBO能够更精准地优化复杂查询,尤其在Join策略选择、聚合计算优化和谓词下推等关键场景中表现突出。 |
| Atomic | 事务的原子性确保事务作为一个不可分割的工作单元,要么所有操作全部成功提交,要么全部失败回滚,不存在部分执行的状态。 |
| DDL | 数据库模式定义语言DDL(Data Definition Language)是用于创建、修改和管理数据库结构的标准化语言,它定义了数据实体(如表、视图、索引)及其关系的逻辑框架。 |
| 索引Index | ClickHouse通过索引机制优化查询性能,在列式存储的纵向裁剪基础上,支持分区键、主键和多种二级索引。这些索引结构在横向上对数据块进行高效定位,快速过滤无关数据块,显著减少磁盘扫描范围,从而提升查询效率。 |
ClickHouse优势
- 性能优势:ClickHouse采用列存储,相同列的数据属于同一类型,有利于获得更高的数据压缩比。通常可以达到10:1的压缩比,大幅降低存储成本和读取开销,提高查询性能。
- 副本机制:ClickHouse利用Zookeeper,通过ReplicatedMergeTree引擎(Replicated系列引擎)实现了副本机制。用户在创建表时,可指定存储引擎,选择该表是否进行复制。
- 简单易用:通过控制台分钟级构建ClickHouse分析集群,使您无需关注底层基础设施,利用完善的SQL语句支持,专注于数据价值的分析。
- 极致性能:使用分布式大规模并行处理MPP框架,并充分利用所有可用的硬件,以尽可能快地处理每个查询。查询效率数倍于传统数据仓库,单个查询的峰值处理性能高达每秒数TB。
- 安全可靠:用户集群独立部署,支持VPC私有网络隔离,数据访问安全多重保障。
- 成本更低:利用云端高性价比设备,构建极具成本优势的托管ClickHouse集群。




