
- 最新动态
- 功能总览
- 服务公告
- 产品介绍
- 计费说明
- 快速入门
-
ModelArts用户指南(Standard)
- ModelArts Standard使用流程
- ModelArts Standard准备工作
- ModelArts Standard资源管理
- 使用自动学习实现零代码AI开发
- 使用Workflow实现低代码AI开发
- 使用Notebook进行AI开发调试
- 数据准备与处理
- 使用ModelArts Standard训练模型
- 使用ModelArts Standard部署模型并推理预测
- 制作自定义镜像用于ModelArts Standard
- ModelArts Standard资源监控
- 使用CTS审计ModelArts服务
- ModelArts用户指南(Lite Server)
- ModelArts用户指南(Lite Cluster)
- 最佳实践
-
API参考
- 使用前必读
- API概览
- 如何调用API
- 开发环境管理
- 训练管理
- AI应用管理
- APP认证管理
- 服务管理
- 资源管理
- DevServer管理
- 授权管理
- 配额管理
- 资源标签管理
- 节点池管理
- 应用示例
- 权限策略和授权项
- 公共参数
-
历史API
-
数据管理(旧版)
- 查询数据集列表
- 创建数据集
- 查询数据集详情
- 更新数据集
- 删除数据集
- 查询数据集的统计信息
- 查询数据集监控数据
- 查询数据集的版本列表
- 创建数据集标注版本
- 查询数据集版本详情
- 删除数据集标注版本
- 查询样本列表
- 批量添加样本
- 批量删除样本
- 查询单个样本信息
- 获取样本搜索条件
- 分页查询团队标注任务下的样本列表
- 查询团队标注的样本信息
- 查询数据集标签列表
- 创建数据集标签
- 批量修改标签
- 批量删除标签
- 按标签名称更新单个标签
- 按标签名称删除标签及仅包含此标签的文件
- 批量更新样本标签
- 查询数据集的团队标注任务列表
- 创建团队标注任务
- 查询团队标注任务详情
- 启动团队标注任务
- 更新团队标注任务
- 删除团队标注任务
- 创建团队标注验收任务
- 查询团队标注验收任务报告
- 更新团队标注验收任务状态
- 查询团队标注任务统计信息
- 查询团队标注任务成员的进度信息
- 团队成员查询团队标注任务列表
- 提交验收任务的样本评审意见
- 团队标注审核
- 批量更新团队标注样本的标签
- 查询标注团队列表
- 创建标注团队
- 查询标注团队详情
- 更新标注团队
- 删除标注团队
- 向标注成员发送邮件
- 查询所有团队的标注成员列表
- 查询标注团队的成员列表
- 创建标注团队的成员
- 批量删除标注团队成员
- 查询标注团队成员详情
- 更新标注团队成员
- 删除标注团队成员
- 查询数据集导入任务列表
- 创建导入任务
- 查询数据集导入任务的详情
- 查询数据集导出任务列表
- 创建数据集导出任务
- 查询数据集导出任务的状态
- 同步数据集
- 查询数据集同步任务的状态
- 查询智能标注的样本列表
- 查询单个智能标注样本的信息
- 分页查询智能任务列表
- 启动智能任务
- 获取智能任务的信息
- 停止智能任务
- 查询处理任务列表
- 创建处理任务
- 查询处理任务详情
- 更新处理任务
- 删除处理任务
- 开发环境(旧版)
- 训练管理(旧版)
-
数据管理(旧版)
- SDK参考
-
常见问题
-
一般性问题
- 什么是ModelArts
- ModelArts与其他服务的关系
- ModelArts与DLS服务的区别?
- 如何购买或开通ModelArts?
- 如何获取访问密钥?
- 如何上传数据至OBS?
- 提示“上传的AK/SK不可用”,如何解决?
- 使用ModelArts时提示“权限不足”,如何解决?
- 如何用ModelArts训练基于结构化数据的模型?
- 什么是区域、可用区?
- 在ModelArts中如何查看OBS目录下的所有文件?
- ModelArts数据集保存到容器的哪里?
- ModelArts支持哪些AI框架?
- ModelArts训练和推理分别对应哪些功能?
- 如何查看账号ID和IAM用户ID
- ModelArts AI识别可以单独针对一个标签识别吗?
- ModelArts如何通过标签实现资源分组管理
- 为什么资源充足还是在排队?
- 计费相关
- Standard自动学习
-
Standard数据管理
- 添加图片时,图片大小有限制吗?
- 数据集图片无法显示,如何解决?
- 如何将多个物体检测的数据集合并成一个数据集?
- 导入数据集失败
- 表格类型的数据集如何标注
- 本地标注的数据,导入ModelArts需要做什么?
- 为什么通过Manifest文件导入失败?
- 标注结果存储在哪里?
- 如何将标注结果下载至本地?
- 团队标注时,为什么团队成员收不到邮件?
- 可以两个账号同时进行一个数据集的标注吗?
- 团队标注的数据分配机制是什么?
- 标注过程中,已经分配标注任务后,能否将一个labeler从标注任务中删除?删除后对标注结果有什么影响?如果不能删除labeler,能否删除将他的标注结果从整体标注结果中分离出来?
- 数据标注中,难例集如何定义?什么情况下会被识别为难例?
- 物体检测标注时,支持叠加框吗?
- 如何将两个数据集合并?
- 智能标注是否支持多边形标注?
- 团队标注的完成验收的各选项表示什么意思?
- 同一个账户,图片展示角度不同是为什么?
- 智能标注完成后新加入数据是否需要重新训练?
- 为什么在ModelArts数据标注平台标注数据提示标注保存失败?
- 标注多个标签,是否可针对一个标签进行识别?
- 使用数据处理的数据扩增功能后,新增图片没有自动标注
- 视频数据集无法显示和播放视频
- 使用样例的有标签的数据或者自己通过其他方式打好标签的数据放到OBS桶里,在modelarts中同步数据源以后看不到已标注,全部显示为未标注
- 如何使用soft NMS方法降低目标框堆叠度
- ModelArts标注数据丢失,看不到标注过的图片的标签
- 如何将某些图片划分到验证集或者训练集?
- 物体检测标注时除了位置、物体名字,是否可以设置其他标签,比如是否遮挡、亮度等?
- ModelArts数据管理支持哪些格式?
- 旧版数据集中的数据是否会被清理?
- 数据集版本管理找不到新建的版本
- 如何查看数据集大小
- 如何查看新版数据集的标注详情
- 标注数据如何导出
- 找不到新创建的数据集
- 数据集配额不正确
- 数据集如何切分
- 如何删除数据集图片
- 从AI Gallery下载到桶里的数据集,再在ModelArts里创建数据集,显示样本数为0
-
Standard Notebook
- 规格限制
- 文件上传下载
- 数据存储
- 环境配置相关
- Notebook实例常见错误
- 代码运行常见错误
-
PyCharm Toolkit使用
- 安装ToolKit工具时出现错误,如何处理?
- PyCharm ToolKit工具中Edit Credential时,出现错误
- 为什么无法启动训练?
- 提交训练作业时,出现xxx isn't existed in train_version错误
- 提交训练作业报错“Invalid OBS path”
- 使用PyCharm Toolkit提交训练作业报错NoSuchKey
- 部署上线时,出现错误
- 如何查看PyCharm ToolKit的错误日志
- 如何通过PyCharm ToolKit创建多个作业同时训练?
- 使用PyCharm ToolKit ,提示Error occurs when accessing to OBS
- VS Code使用技巧
-
VS Code连接开发环境失败常见问题
- 在ModelArts控制台界面上单击VS Code接入并在新界面单击打开,未弹出VS Code窗口
- 在ModelArts控制台界面上单击VS Code接入并在新界面单击打开,VS Code打开后未进行远程连接
- VS Code连接开发环境失败时的排查方法
- 远程连接出现弹窗报错:Could not establish connection to xxx
- 连接远端开发环境时,一直处于"Setting up SSH Host xxx: Downloading VS Code Server locally"超过10分钟以上,如何解决?
- 连接远端开发环境时,一直处于"Setting up SSH Host xxx: Copying VS Code Server to host with scp"超过10分钟以上,如何解决?
- 连接远端开发环境时,一直处于"ModelArts Remote Connect: Connecting to instance xxx..."超过10分钟以上,如何解决?
- 远程连接处于retry状态如何解决?
- 报错“The VS Code Server failed to start”如何解决?
- 报错“Permissions for 'x:/xxx.pem' are too open”如何解决?
- 报错“Bad owner or permissions on C:\Users\Administrator/.ssh/config”或“Connection permission denied (publickey)”如何解决?
- 报错“ssh: connect to host xxx.pem port xxxxx: Connection refused”如何解决?
- 报错"ssh: connect to host ModelArts-xxx port xxx: Connection timed out"如何解决?
- 报错“Load key "C:/Users/xx/test1/xxx.pem": invalid format”如何解决?
- 报错“An SSH installation couldn't be found”或者“Could not establish connection to instance xxx: 'ssh' ...”如何解决?
- 报错“no such identity: C:/Users/xx /test.pem: No such file or directory”如何解决?
- 报错“Host key verification failed.'或者'Port forwarding is disabled.”如何解决?
- 报错“Failed to install the VS Code Server.”或“tar: Error is not recoverable: exitng now.”如何解决?
- VS Code连接远端Notebook时报错“XHR failed”
- VS Code连接后长时间未操作,连接自动断开
- VS Code自动升级后,导致远程连接时间过长
- 使用SSH连接,报错“Connection reset”如何解决?
- 使用MobaXterm工具SSH连接Notebook后,经常断开或卡顿,如何解决?
- VS Code连接开发环境时报错Missing GLIBC,Missing required dependencies
- 使用VSCode-huawei,报错:卸载了‘ms-vscode-remote.remot-sdh’,它被报告存在问题
- 在Notebook中使用自定义镜像常见问题
-
更多功能咨询
- 在Notebook中,如何使用昇腾多卡进行调试?
- 使用Notebook不同的资源规格,为什么训练速度差不多?
- 使用MoXing时,如何进行增量训练?
- 在Notebook中如何查看GPU使用情况
- 如何在代码中打印GPU使用信息
- Ascend上如何查看实时性能指标?
- 不启用自动停止,系统会自动停掉Notebook实例吗?会删除Notebook实例吗?
- JupyterLab目录的文件、Terminal的文件和OBS的文件之间的关系
- ModelArts中创建的数据集,如何在Notebook中使用
- pip介绍及常用命令
- 开发环境中不同Notebook规格资源“/cache”目录的大小
- 开发环境如何实现IAM用户隔离?
- 资源超分对Notebook实例有什么影响?
- 在Notebook中使用tensorboard命令打开日志文件报错Permission denied
-
Standard训练作业
-
功能咨询
- 本地导入的算法有哪些格式要求?
- 欠拟合的解决方法有哪些?
- 旧版训练迁移至新版训练需要注意哪些问题?
- ModelArts训练好后的模型如何获取?
- AI引擎Scikit_Learn0.18.1的运行环境怎么设置?
- TPE算法优化的超参数必须是分类特征(categorical features)吗
- 模型可视化作业中各参数的意义?
- 如何在ModelArts上获得RANK_TABLE_FILE进行分布式训练?
- 如何查询自定义镜像的cuda和cudnn版本?
- Moxing安装文件如何获取?
- 多节点训练TensorFlow框架ps节点作为server会一直挂着,ModelArts是怎么判定训练任务结束?如何知道是哪个节点是worker呢?
- 训练作业的自定义镜像如何安装Moxing?
- 子用户使用专属资源池创建训练作业无法选择已有的SFS Turbo
- 训练过程读取数据
- 编写训练代码
- 创建训练作业
- 管理训练作业版本
- 查看作业详情
-
功能咨询
- Standard推理部署
- Standard资源池
- API/SDK
-
一般性问题
-
故障排除
- 通用问题
- 自动学习
-
开发环境
- 环境配置故障
- 实例故障
- 代码运行故障
- JupyterLab插件故障
-
VS Code连接开发环境失败故障处理
- 在ModelArts控制台界面上单击VS Code接入并在新界面单击打开,未弹出VS Code窗口
- 在ModelArts控制台界面上单击VS Code接入并在新界面单击打开,VS Code打开后未进行远程连接
- VS Code连接开发环境失败时的排查方法
- 远程连接出现弹窗报错:Could not establish connection to xxx
- 连接远端开发环境时,一直处于"Setting up SSH Host xxx: Downloading VS Code Server locally"超过10分钟以上,如何解决?
- 连接远端开发环境时,一直处于"Setting up SSH Host xxx: Copying VS Code Server to host with scp"超过10分钟以上,如何解决?
- 远程连接处于retry状态如何解决?
- 报错“The VS Code Server failed to start”如何解决?
- 报错“Permissions for 'x:/xxx.pem' are too open”如何解决?
- 报错“Bad owner or permissions on C:\Users\Administrator/.ssh/config”如何解决?
- 报错“Connection permission denied (publickey)”如何解决
- 报错“ssh: connect to host xxx.pem port xxxxx: Connection refused”如何解决?
- 报错"ssh: connect to host ModelArts-xxx port xxx: Connection timed out"如何解决?
- 报错“Load key "C:/Users/xx/test1/xxx.pem": invalid format”如何解决?
- 报错“An SSH installation couldn't be found”或者“Could not establish connection to instance xxx: 'ssh' ...”如何解决?
- 报错“no such identity: C:/Users/xx /test.pem: No such file or directory”如何解决?
- 报错“Host key verification failed.'或者'Port forwarding is disabled.”如何解决?
- 报错“Failed to install the VS Code Server.”或“tar: Error is not recoverable: exiting now.”如何解决?
- VS Code连接远端Notebook时报错“XHR failed”
- VS Code连接后长时间未操作,连接自动断开
- VS Code自动升级后,导致远程连接时间过长
- 使用SSH连接,报错“Connection reset”如何解决?
- 使用MobaXterm工具SSH连接Notebook后,经常断开或卡顿,如何解决?
- VS Code连接开发环境时报错Missing GLIBC,Missing required dependencies
- 使用VSCode-huawei,报错:卸载了‘ms-vscode-remote.remot-sdh’,它被报告存在问题
- 使用VS Code连接实例时,发现VS Code端的实例目录和云上目录不匹配
- VSCode远程连接时卡顿,或Python调试插件无法使用如何处理?
-
自定义镜像故障
- Notebook自定义镜像故障基础排查
- 镜像保存时报错“there are processes in 'D' status, please check process status using 'ps -aux' and kill all the 'D' status processes”或“Buildimge,False,Error response from daemon,Cannot pause container xxx”如何解决?
- 镜像保存时报错“container size %dG is greater than threshold %dG”如何解决?
- 保存镜像时报错“too many layers in your image”如何解决?
- 镜像保存时报错“The container size (xG) is greater than the threshold (25G)”如何解决?
- 镜像保存时报错“BuildImage,True,Commit successfully|PushImage,False,Task is running.”
- 使用自定义镜像创建Notebook后打开没有kernel
- 用户自定义镜像自建的conda环境会查到一些额外的包,影响用户程序,如何解决?
- 用户使用ma-cli制作自定义镜像失败,报错文件不存在(not found)
- 用户使用torch报错Unexpected error from cudaGetDeviceCount
- 其他故障
-
训练作业
- OBS操作相关故障
-
云上迁移适配故障
- 无法导入模块
- 训练作业日志中提示“No module named .*”
- 如何安装第三方包,安装报错的处理方法
- 下载代码目录失败
- 训练作业日志中提示“No such file or directory”
- 训练过程中无法找到so文件
- ModelArts训练作业无法解析参数,日志报错
- 训练输出路径被其他作业使用
- PyTorch1.0引擎提示“RuntimeError: std:exception”
- MindSpore日志提示“ retCode=0x91, [the model stream execute failed]”
- 使用moxing适配OBS路径,pandas读取文件报错
- 日志提示“Please upgrade numpy to >= xxx to use this pandas version”
- 重装的包与镜像装CUDA版本不匹配
- 创建训练作业提示错误码ModelArts.2763
- 训练作业日志中提示 “AttributeError: module '***' has no attribute '***'”
- 系统容器异常退出
- 硬盘限制故障
- 外网访问限制
- 权限问题
- GPU相关问题
-
业务代码问题
- 日志提示“pandas.errors.ParserError: Error tokenizing data. C error: Expected .* fields”
- 日志提示“max_pool2d_with_indices_out_cuda_frame failed with error code 0”
- 训练作业失败,返回错误码139
- 训练作业失败,如何使用开发环境调试训练代码?
- 日志提示“ '(slice(0, 13184, None), slice(None, None, None))' is an invalid key”
- 日志报错“DataFrame.dtypes for data must be int, float or bool”
- 日志提示“CUDNN_STATUS_NOT_SUPPORTED. ”
- 日志提示“Out of bounds nanosecond timestamp”
- 日志提示“Unexpected keyword argument passed to optimizer”
- 日志提示“no socket interface found”
- 日志提示“Runtimeerror: Dataloader worker (pid 46212 ) is killed by signal: Killed BP”
- 日志提示“AttributeError: 'NoneType' object has no attribute 'dtype'”
- 日志提示“No module name 'unidecode'”
- 分布式Tensorflow无法使用“tf.variable”
- MXNet创建kvstore时程序被阻塞,无报错
- 日志出现ECC错误,导致训练作业失败
- 超过最大递归深度导致训练作业失败
- 使用预置算法训练时,训练失败,报“bndbox”错误
- 训练作业进程异常退出
- 训练作业进程被kill
- 训练作业运行失败
- 专属资源池创建训练作业
- 训练作业性能问题
-
推理部署
-
模型管理
- 创建模型失败,如何定位和处理问题?
- 导入模型提示该账号受限或者没有操作权限
- 用户创建模型时构建镜像或导入文件失败
- 创建模型时,OBS文件目录对应镜像里面的目录结构是什么样的?
- 通过OBS导入模型时,如何编写打印日志代码才能在ModelArts日志查询界面看到日志
- 通过OBS创建模型时,构建日志中提示pip下载包失败
- 通过自定义镜像创建模型失败
- 导入模型后部署服务,提示磁盘不足
- 创建模型成功后,部署服务报错,如何排查代码问题
- 自定义镜像导入配置运行时依赖无效
- 通过API接口查询模型详情,model_name返回值出现乱码
- 导入模型提示模型或镜像大小超过限制
- 导入模型提示单个模型文件超过5G限制
- 创建模型失败,提示模型镜像构建任务超时,没有构建日志
- 服务部署
- 服务预测
-
模型管理
- MoXing
- API/SDK
- 资源池
- 视频帮助
- 通用参考
链接复制成功!
在Notebook中通过镜像保存功能制作自定义镜像用于推理
场景说明
本文详细介绍如何将本地已经制作好的模型包导入ModelArts的开发环境Notebook中进行调试和保存,然后将保存后的镜像部署到推理。本案例仅适用于华为云北京四和上海一站点。
操作流程如下:
Step1 在Notebook中复制模型包
- 登录ModelArts控制台,在左侧导航栏中选择“开发空间 > Notebook”,进入“Notebook”管理页面。
- 单击右上角“创建”,进入“创建Notebook”页面,请参见如下说明填写参数。
- 填写Notebook基本信息,包含名称、描述、是否自动停止。
- 填写Notebook详细参数,如选择镜像、资源规格等。
- “镜像”:选择统一镜像tensorflow_2.1-cuda_10.1-cudnn7-ubuntu_18.04(详见引擎版本一:tensorflow_2.1.0-cuda_10.1-py_3.7-ubuntu_18.04-x86_64)或者pytorch1.8-cuda10.2-cudnn7-ubuntu18.04(详见引擎版本一:pytorch_1.8.0-cuda_10.2-py_3.7-ubuntu_18.04-x86_64)。
- “资源池”:选择公共资源池或专属资源池,此处以公共资源池为例。
- “类型”:推荐选择GPU。
- “规格”:推荐选择GP Tnt004规格,如果没有再选择其他规格。
- 参数填写完成后,单击“立即创建”进行规格确认。参数确认无误后,单击“提交”,完成Notebook的创建操作。
进入Notebook列表,正在创建中的Notebook状态为“创建中”,创建过程需要几分钟,请耐心等待。
- 当Notebook状态变为“运行中”时,表示Notebook已创建并启动完成。单击“操作列”的“打开”,进入JupyterLab的Launcher界面。
图1 打开后进入JupyterLab的Launcher界面

- 通过
 功能,上传模型包文件到Notebook中,默认工作目录/home/ma-user/work/。模型包文件需要用户自己准备,样例内容参见模型包文件样例。
图2 上传模型包
功能,上传模型包文件到Notebook中,默认工作目录/home/ma-user/work/。模型包文件需要用户自己准备,样例内容参见模型包文件样例。
图2 上传模型包
- 打开Terminal终端,解压model.zip,解压后删除zip文件。
#解压命令 unzip model.zip
图3 在Terminal终端中解压model.zip
- 在Terminal运行界面,执行复制命令。
cp -rf model/* /home/ma-user/infer/model/1
然后执行如下命令查看镜像文件复制成功。
cd /home/ma-user/infer/model/1
ll
图4 查看镜像文件复制成功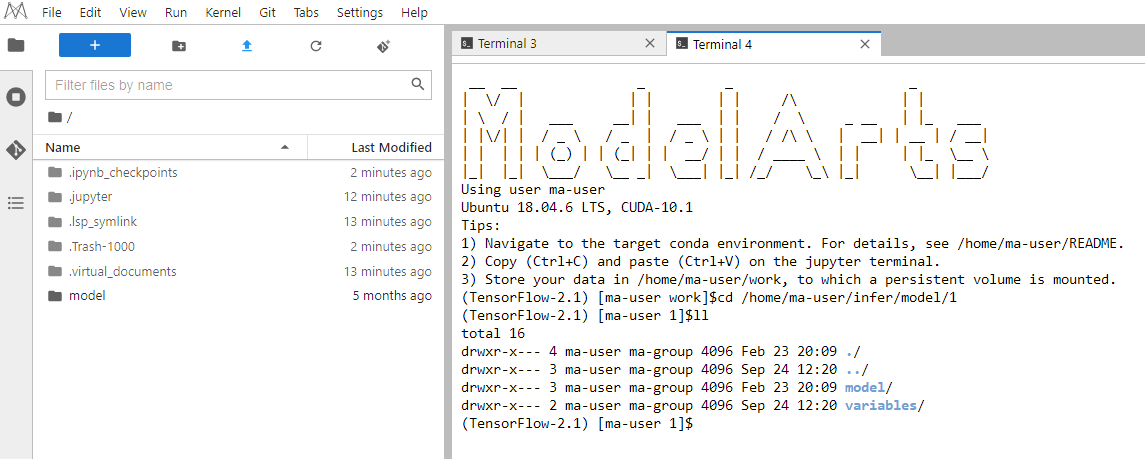
模型包文件样例
模型包文件model.zip中需要用户自己准备模型文件,此处仅是举例示意说明,以一个手写数字识别模型为例。
Model目录下必须要包含推理脚本文件customize_service.py,目的是为开发者提供模型预处理和后处理的逻辑。

推理脚本customize_service.py的具体写法要求可以参考模型推理代码编写说明。
本案例中提供的customize_service.py文件具体内容如下:
import logging
import threading
import numpy as np
import tensorflow as tf
from PIL import Image
from model_service.tfserving_model_service import TfServingBaseService
class mnist_service(TfServingBaseService):
def __init__(self, model_name, model_path):
self.model_name = model_name
self.model_path = model_path
self.model = None
self.predict = None
# 非阻塞方式加载saved_model模型,防止阻塞超时
thread = threading.Thread(target=self.load_model)
thread.start()
def load_model(self):
# load saved_model 格式的模型
self.model = tf.saved_model.load(self.model_path)
signature_defs = self.model.signatures.keys()
signature = []
# only one signature allowed
for signature_def in signature_defs:
signature.append(signature_def)
if len(signature) == 1:
model_signature = signature[0]
else:
logging.warning("signatures more than one, use serving_default signature from %s", signature)
model_signature = tf.saved_model.DEFAULT_SERVING_SIGNATURE_DEF_KEY
self.predict = self.model.signatures[model_signature]
def _preprocess(self, data):
images = []
for k, v in data.items():
for file_name, file_content in v.items():
image1 = Image.open(file_content)
image1 = np.array(image1, dtype=np.float32)
image1.resize((28, 28, 1))
images.append(image1)
images = tf.convert_to_tensor(images, dtype=tf.dtypes.float32)
preprocessed_data = images
return preprocessed_data
def _inference(self, data):
return self.predict(data)
def _postprocess(self, data):
return {
"result": int(data["output"].numpy()[0].argmax())
}Step2 在Notebook中调试模型
- 打开一个新的Terminal终端,进入“/home/ma-user/infer/”目录,运行启动脚本run.sh,并预测模型。基础镜像中默认提供了run.sh作为启动脚本。启动命令如下:
sh run.sh
图6 运行启动脚本
- 上传一张预测图片(手写数字图片)到Notebook中。
图7 手写数字图片
 图8 上传预测图片
图8 上传预测图片
- 重新打开一个新的Terminal终端,执行如下命令进行预测。
curl -kv -F 'images=@/home/ma-user/work/test.png' -X POST http://127.0.0.1:8080/
图9 预测
在调试过程中,如果有修改模型文件或者推理脚本文件,需要重启run.sh脚本。执行如下命令先停止nginx服务,再运行run.sh脚本。
#查询nginx进程 ps -ef |grep nginx #关闭所有nginx相关进程 kill -9 {进程ID} #运行run.sh脚本 sh run.sh也可以执行pkill nginx命令直接关闭所有nginx进程。
#关闭所有nginx进程 pkill nginx #运行run.sh脚本 sh run.sh
图10 重启run.sh脚本
Step3 Notebook中保存镜像
 说明:
说明:
Notebook实例状态必须为“运行中”才可以一键进行镜像保存。
- 在Notebook列表中,对于要保存的Notebook实例,单击右侧“操作”列中的“更多 > 保存镜像”,进入“保存镜像”对话框。
- 在保存镜像对话框中,设置组织、镜像名称、镜像版本和描述信息。单击“确认”保存镜像。
在“组织”下拉框中选择一个组织。如果没有组织,可以单击右侧的“立即创建”,创建一个组织。
同一个组织内的用户可以共享使用该组织内的所有镜像。
- 镜像会以快照的形式保存,保存过程约5分钟,请耐心等待。此时不可再操作实例(对于打开的JupyterLab界面和本地IDE仍可操作)。
 须知:
须知:
快照中耗费的时间仍占用实例的总运行时长,如果在快照中时,实例因运行时间到期停止,将导致镜像保存失败。
- 镜像保存成功后,实例状态变为“运行中”,用户可在“镜像管理”页面查看到该镜像详情。
- 单击镜像的名称,进入镜像详情页,可以查看镜像版本/ID,状态,资源类型,镜像大小,SWR地址等。
Step4 使用保存成功的镜像用于推理部署
将Step2 在Notebook中调试模型的自定义镜像导入到模型中,并部署为在线服务。
- 登录ModelArts控制台,在左侧导航栏中选择“模型管理”,单击“创建模型”,进入创建模型。
- 设置模型的参数,如图11所示。
- 元模型来源:从容器镜像中选择。
- 容器镜像所在的路径:单击
 选择镜像文件。具体路径查看5SWR地址。
选择镜像文件。具体路径查看5SWR地址。 - 容器调用接口:选择HTTPS。
- host:设置为8443。
- 部署类型:选择在线服务。
- 填写启动命令,启动命令内容如下:
sh /home/ma-user/infer/run.sh
- 填写apis定义,单击“保存”生效。apis定义中指定输入为文件,具体内容参见下面代码样例。
图12 填写apis定义

apis定义具体内容如下:
[{ "url": "/", "method": "post", "request": { "Content-type": "multipart/form-data", "data": { "type": "object", "properties": { "images": { "type": "file" } } } }, "response": { "Content-type": "applicaton/json", "data": { "type": "object", "properties": { "result": { "type": "integer" } } } } }]须知:
apis定义提供模型对外Restfull api数据定义,用于定义模型的输入、输出格式。
- 创建模型填写apis。在创建的模型部署服务成功后,进行预测时,会自动识别预测类型。
- 创建模型时不填写apis。在创建的模型部署服务成功后,进行预测,需选择“请求类型”。“请求类型”可选择“application/json”或“multipart/form-data”。请根据元模型,选择合适的类型。
- 选择“application/json”时,直接填写“预测代码”进行文本预测。
- 选择“multipart/form-data”时,需填写“请求参数”,请求参数取值等同于使用图形界面的软件进行预测(以Postman为例)Body页签中填写的“KEY”的取值,也等同于使用curl命令发送预测请求上传数据的参数名。
- 设置完成后,单击“立即创建”,等待模型状态变为“正常”。
- 单击新建的模型名称左侧的小三角形,展开模型的版本列表。在操作列单击“部署 > 在线服务”,跳转至在线服务的部署页面。
- 在部署页面,参考如下说明填写关键参数。
“资源池”:选择“公共资源池”。
“模型来源”和“选择模型及版本”:会自动选择模型和版本号。
“实例规格”:在下拉框中选择“限时免费”资源,勾选并阅读免费规格说明。
其他参数可使用默认值。
说明:
如果限时免费资源售罄,建议选择收费CPU资源进行部署。当选择收费CPU资源部署在线服务时会收取少量资源费用,具体费用以界面信息为准。
- 参数配置完成后,单击“下一步”,确认规格参数后,单击“提交”启动在线服务的部署。
- 进入“部署上线 > 在线服务”页面,等待服务状态变为“运行中”时,表示服务部署成功。单击操作列的“预测”,进入服务详情页的“预测”页面。上传图片,预测结果。



