
FlinkServer对接Elasticsearch
操作场景
本章节介绍通过使用FlinkServer写FlinkSQL对接Elasticsearch,Flink支持1.12.2及以后版本,Elasticsearch支持7.10.2及以后版本,详细如下:
- 安全模式的Flink集群支持对接安全模式和非安全模式的Elasticsearch集群。

安全模式的Flink集群对接非安全模式的Elasticsearch集群时需设置如下参数:
- 登录Manager,选择“集群 > 服务 > Flink > 配置 > 全部配置”,搜索参数“es.security.indication”,并将FlinkResource角色和FlinkServer角色下该参数的值配置为“false” 。
- 重启Flink服务,在“概览”页签,选择“更多 > 重启服务”等待Flink服务重启成功。
- 非安全模式的Flink集群支持对接非安全模式的Elasticsearch集群。
本示例以安全模式FlinkServer对接本集群安全模式Elasticsearch为例。
前提条件
- 集群已安装Flink、Yarn、ZooKeeper、HDFS、Kafka和Elasticsearch服务。
- 参考创建FlinkServer角色创建一个具有FlinkServer管理员权限的用户用于访问Flink WebUI,如:flink_admin。并为该用户添加Elasticsearch用户组。若对接非本集群的Elasticsearch,请确保集群之间互信,并在待对接的集群内也创建具有相同权限的同名用户,并在Ranger UI中为该用户添加Elasticsearch的相关权限,可参考添加Elasticsearch的Ranger访问权限策略。
- 需确保Elasticsearch所在集群不存在“Elasticsearch服务存在red状态的索引”告警。
操作步骤
- 使用flink_admin登录Manager,选择“集群 > 服务 > Flink”,在“Flink WebUI”右侧,单击链接,访问Flink的WebUI。
- 参考新建作业,新建Flink SQL流作业,参考如下内容在作业开发界面进行作业开发,配置完成后启动作业。
需勾选“基础参数”中的“开启CheckPoint”,“时间间隔(ms)”可设置为“60000”,“模式”可使用默认值。
--创建KafkaSource表 CREATE TABLE kafka(uuid STRING, name STRING, age INT) WITH ( 'connector' = 'kafka', 'topic' = 'kafka2ES', 'properties.bootstrap.servers' = 'Kafka的Broker实例业务IP:Kafka端口号', 'properties.group.id' = 'testgroup2', 'scan.startup.mode' = 'latest-offset', 'format' = 'csv', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.系统域名' ); --创建ESSink表 CREATE TABLE es (uuid STRING, name STRING, age INT, PRIMARY KEY (uuid) NOT ENFORCED ) WITH ( 'connector' = 'elasticsearch-7', 'hosts' = 'https://10.10.10.10:24100;https://10.10.10.11:24100', 'index' = 'test_index', 'sink.bulk-flush.max-actions' = '1' ); --将Kafka的数据写入ES insert into es select * from kafka;

- Kafka Broker实例IP地址及端口号说明:
- 服务的实例IP地址可通过登录FusionInsight Manager后,单击“集群 > 服务 > Kafka > 实例”,在实例列表页面中查询。
- 集群已启用Kerberos认证(安全模式)时Broker端口为“sasl.port”参数的值,默认为“21007”。
- 集群未启用Kerberos认证(普通模式)时Broker端口为“port”的值,默认为“9092”。如果配置端口号为9092,则需要配置“allow.everyone.if.no.acl.found”参数为true,具体操作如下:
登录FusionInsight Manager系统,选择“集群 > 服务 > Kafka > 配置 > 全部配置”,搜索“allow.everyone.if.no.acl.found”配置,修改参数值为true,保存配置即可。
- 系统域名:可登录FusionInsight Manager,选择“系统 > 权限 > 域和互信”,查看“本端域”参数,即为当前系统域名。
- 10.10.10.10:Elasticsearch的EsNode的业务IP。登录FusionInsight Manager,选择“集群 > 服务 > Elasticsearch > 实例”,可查看所有Elasticsearch的EsNode的业务IP地址。
- 24100:Elasticsearch默认端口号,可登录FusionInsight Manager系统,选择“集群 > 服务 > Elasticsearch > 配置 > 全部配置”,搜索“SERVER_PORT”查看EsNode的端口。
- Kafka Broker实例IP地址及端口号说明:
- 查看作业管理界面,作业状态为“运行中”。
- 参考管理Kafka主题中的消息,查看Topic并向Kafka中写入数据。
./kafka-topics.sh --list --zookeeper ZooKeeper的quorumpeer实例业务IP:ZooKeeper客户端端口号/kafka
sh kafka-console-producer.sh --broker-list Kafka角色实例所在节点的IP地址:Kafka端口号 --topic 主题名称 --producer.config 客户端目录/Kafka/kafka/config/producer.properties
例如本示例使用主题名称为kafka2ES:
sh kafka-console-producer.sh --broker-list Kafka角色实例所在节点的IP地址:Kafka端口号 --topic kafka2ES --producer.config /opt/client/Kafka/kafka/config/producer.properties
输入消息内容:
3,zhangsan,18 4,wangwu,19 8,zhaosi,20
输入完成后按回车发送消息。
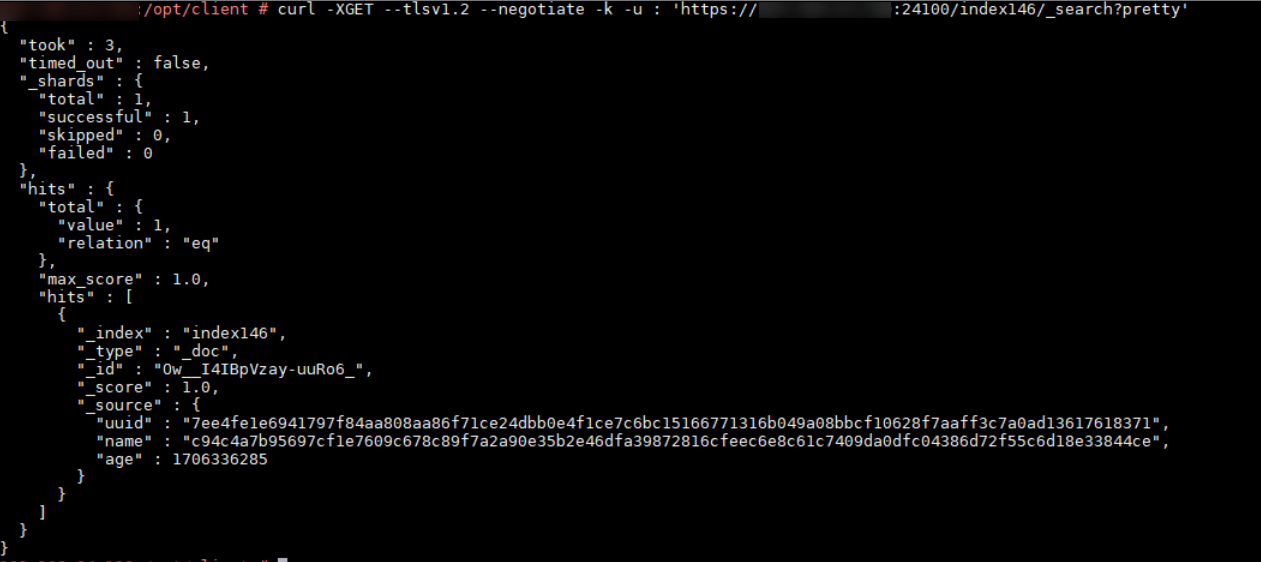
- 参考Linux下curl命令的使用使用curl命令获取写入的数据,数据输出正常则表明成功对接Elasticsearch,如下图所示。
如:curl -XGET --tlsv1.2 --negotiate -k -u : 'https://10.10.10.10:24100/test_index/_search?pretty'
WITH主要参数说明
|
参数 |
是否必选 |
数据类型 |
描述 |
|---|---|---|---|
|
connector |
必选 |
String |
指定要使用的连接器,如elasticsearch-7,即连接到Elasticsearch 7.x或更高版本的集群。 |
|
hosts |
必选 |
String |
要连接的一台或多台Elasticsearch主机地址。 例如:'http://10.10.10.10:24100;http://10.10.10.10:24100' |
|
index |
必选 |
String |
Elasticsearch中每条记录的索引。可以是一个静态索引(如 'myIndex' )或一个动态索引(如 'index-{log_ts|yyyy-MM-dd}' )。 |
|
document-id.key-delimiter |
可选 |
String |
复合键的分隔符,默认为“_”。若指定为“$”,则文档ID为“KEY1$KEY2$KEY3”。 |
|
username |
可选 |
String |
用于连接Elasticsearch实例的用户名。 |
|
password |
可选 |
String |
用于连接Elasticsearch实例的用户名密码。若配置了username,则必须配置为非空字符串。 |
|
failure-handler |
可选 |
String |
对Elasticsearch请求失败情况的失败处理策略,有效策略如下:
|
|
sink.flush-on-checkpoint |
可选 |
Boolean |
|
|
sink.bulk-flush.max-actions |
可选 |
Integer |
每个批量请求的最大缓冲操作数,默认值为“1000”,可设置为“0”禁用该功能。 |
|
sink.bulk-flush.max-size |
可选 |
MemorySize |
每个批量请求的缓冲操作在内存中的最大值,默认值为“2MB”,单位必须为MB,可设置为“0”禁用该功能。 |
|
sink.bulk-flush.interval |
可选 |
Duration |
缓冲操作的间隔时间,默认值为“1s”,可设置为“0”禁用该功能。 |
|
sink.bulk-flush.backoff.strategy |
可选 |
String |
指定在由于临时请求错误导致任何flush操作失败时如何执行重试。有效策略为:
|
|
sink.bulk-flush.backoff.max-retries |
可选 |
Integer |
最大回退重试次数。 |
|
sink.bulk-flush.backoff.delay |
可选 |
Duration |
每次退避重试之间的延迟,退避策略如下:
|
|
connection.path-prefix |
可选 |
String |
添加到每个REST通信中的前缀字符串,例如: '/v1' 。 |
|
format |
可选 |
String |
Elasticsearch连接器支持的指定格式,默认值为“json”。 |




