
创建CDL数据同步任务作业
操作场景
CDLService WebUI提供可视化的作业编排页面,用户可快速创建CDL作业,实现实时数据入湖。
前提条件
- 开启Kerberos认证的集群需已创建具有CDL管理操作权限的用户。
- ThirdKafka链路使用DRS作为源端时,需要提前手动创建心跳Topic。
- DRS从opengauss数据库同步数据时,心跳Topic格式为:opengauss数据库库名-cdc_cdl-cdc_heartbeat。
- DRS从Oracle数据库同步数据时,心跳Topic格式固定为:null-cdc_cdl-cdc_heartbeat。
操作步骤
- 使用具有CDL管理操作权限的用户或admin用户(未开启Kerberos认证的集群)登录CDLService WebUI界面,请参考登录CDLService WebUI。
- 选择“作业管理 > 数据同步任务 > 新建作业”,在弹出的窗口中输入作业相关信息,然后单击“下一步”。
参数名称
描述
示例
Name
作业名称。
job_pgsqltokafka
Desc
描述信息。
xxx
- 在“作业管理”界面,根据业务数据流向,从界面左侧列表中分别选择“Source”和“Sink”中数据连接元素并将其拖到右侧的操作界面中。
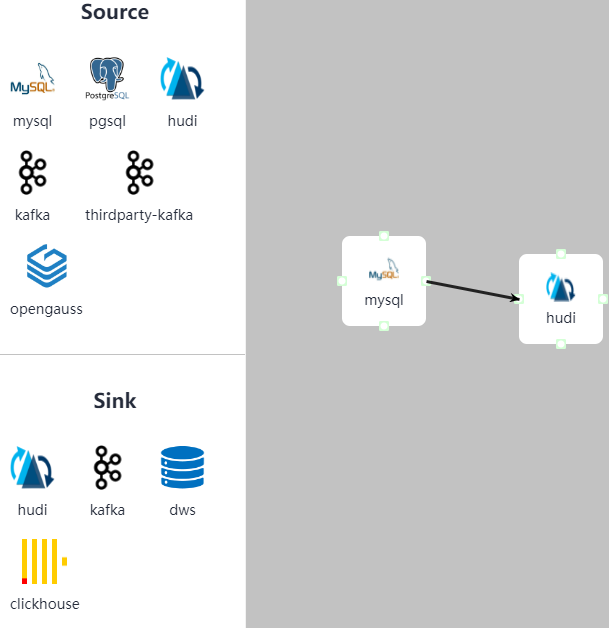
双击数据连接元素,并配置对应参数。
如需删除数据连接元素,请单击数据连接元素右上角的
 即可。
即可。表1 MySQL作业参数 参数名称
描述
示例
Link
已创建的MySQL连接。
mysqllink
Tasks Max
允许Connector创建的最大Task的数量,值为“1”。
1
Mode
任务需要抓取的CDC事件类型。
- insert:插入操作
- update:更新操作
- delete:删除操作
insert、update、delete
DB Name
MySQL数据库名称。
cdl-test
Schema Auto Create
是否在启动任务时抓取表的Schema信息。
否
Connect With Hudi
是否对接Hudi。
是
DBZ Snapshot Locking Mode
任务启动执行快照时的锁模式。
none
WhiteList
待抓取表的白名单。
配置需要抓取的表的名单列表,多个表可以用英文逗号分隔,支持通配符。
可选参数,单击
 显示该参数。说明:
显示该参数。说明:若此参数未配置,当MySQL源端数据库中存在多个表时,任务global topic(global topic为任务名)就会创建多个分区,分区数量与源端MySQL数据库表数量一致。若配置了此参数,则global topic最大分区为“topics.max.partitions”的参数值,该参数默认值为“5”,可通过CDL服务配置界面修改。
testtable
BlackList
表的黑名单。
配置不需要抓取的表的名单列表,多个表可以用英文逗号分隔,支持通配符。
可选参数,单击
 显示该参数。
显示该参数。-
Multi Partition
是否开启Topic的多分区。
开启之后需要配置“Topic TableMapping”并指定Topic的分区数量, 单表数据将分散在多个分区中。
可选参数,单击
 显示该参数。说明:
显示该参数。说明:- 此配置项为高危配置, 开启后无法保证数据的时间顺序。
- 默认分区数为“5”,若需修改则需登录FusionInsight Manager,选择“集群 > 服务 > CDL > 配置”,在搜索框中搜索“topics.max.partitions”并修改该值为需要修改的分区数,例如,修改值为“10”,保存配置并重启CDL服务。
- 当源端表为分区表且该参数为否时,CDL创建的Topic分区表数量为源端表分区数量+1。
否
Enable Data Encryption
数据写入Kafka是否加密。若该参数值设置为“是”,则需参考CDL任务支持数据加密配置数据加密。
否
Key Name
加密密钥名称。仅“Enable Data Encryption”参数值为“是”时,显示该参数。
test_key
Topic Table Mapping
Topic与表的映射关系。
用于指定某个表的数据发送到指定的Topic中,开启多分区功能后需要配置Topic的分区数,分区数必须大于1。数据过滤时间用于过滤数据,当源端数据的时间小于设定时间时,该数据将会被丢弃,当源端数据的时间大于设定时间时,该数据发送到下游。
单击
 显示该参数。若“Connect With Hudi”选择“是”,则该参数为必填项。
显示该参数。若“Connect With Hudi”选择“是”,则该参数为必填项。testtable
testtable_topic
2023/03/10 11:33:37
表2 PgSQL作业参数 参数名称
描述
示例
Link
已创建的PgSQL连接。
pgsqllink
Tasks Max
允许Connector创建的最大Task的数量,值为“1”。
1
Mode
任务需要抓取的CDC事件类型。
- insert:插入操作
- update:更新操作
- delete:删除操作
insert、update、delete
dbName Alias
数据库名称。
test
Schema
待连接的数据库的Schema名称。
public
Slot Name
PgSQL逻辑复制槽的名称。
不同任务之间槽名不能重名,支持小写字母和下划线。
test_solt
Enable FailOver Slot
开启Failover Slot功能,将指定为Failover Slot的逻辑复制槽信息从主实例同步到备实例,当主备切换之后逻辑订阅能够继续进行,实现逻辑复制槽的故障转移。
否
Slot Drop
任务停止时是否删除Slot。
否
Connect With Hudi
是否对接Hudi。
是
Use Exist Publication
使用已创建的publication。
是
Publication Name
已创建的publication名称。
“Use Exist Publication”选择“是”时显示该参数。
test
Kafka Message Format
Kafka中的消息格式,包括:
- CDL Json
- Debezium Json
CDL Json
Data Filter Time
数据过滤的起始时间。
2022/03/16 11:33:37
WhiteList
待抓取表的白名单。
配置需要抓取的表的名单列表,多个表可以用英文逗号分隔,支持通配符。
可选参数,单击
 显示该参数。
显示该参数。testtable
BlackList
表的黑名单。
配置不需要抓取的表的名单列表,多个表可以用英文逗号分隔,支持通配符。
可选参数,单击
 显示该参数。
显示该参数。-
Multi Partition
是否开启Topic的多分区。
开启之后需要配置“Topic TableMapping”并指定Topic的分区数量, 单表数据将分散在多个分区中。
可选参数,单击
 显示该参数。说明:
显示该参数。说明:- 此配置项为高危配置, 开启后无法保证数据的时间顺序。
- 默认分区数为“5”,若需修改则需登录FusionInsight Manager,选择“集群 > 服务 > CDL > 配置”,在搜索框中搜索“topics.max.partitions”并修改该值为需要修改的分区数,例如,修改值为“10”,保存配置并重启CDL服务。
- 当源端表为分区表且该参数为否时,CDL创建的Topic分区表数量为源端表分区数量+1。
否
Enable Data Encryption
数据写入Kafka是否加密。若该参数值设置为“是”,则需参考CDL任务支持数据加密配置数据加密。
否
Key Name
加密密钥名称。仅“Enable Data Encryption”参数值为“是”时,显示该参数。
test_key
Topic Table Mapping
Topic与表的映射关系。
用于指定某个表的数据发送到指定的Topic中,开启多分区功能后需要配置Topic的分区数,分区数必须大于1。数据过滤时间用于过滤数据,当源端数据的时间小于设定时间时,该数据将会被丢弃,当源端数据的时间大于设定时间时,该数据发送到下游。
单击
 显示该参数。若“Connect With Hudi”选择“是”,则该参数为必填项。
显示该参数。若“Connect With Hudi”选择“是”,则该参数为必填项。testtable
testtable_topic
2023/03/10 11:33:37
表3 Oracle作业参数 参数名称
描述
示例
Link
已创建的Oracle连接。
oraclelink
Tasks Max
允许Connector创建的最大Task的数量,值为“1”。
1
Mode
任务需要抓取的CDC事件类型。
- insert:插入操作
- update:更新操作
- delete:删除操作
insert、update、delete
dbName Alias
待连接的数据库名称。
oracledb
Schema
待连接的数据库的Schema名称。
oracleschema
Connect With Hudi
是否对接Hudi。
是
DB Fetch Size
指定单次从数据库抓取的数据条数。
取值范围大于等于0, 如果为0,则表示无限制。
可选参数,单击
 显示该参数。
显示该参数。-
WhiteList
待抓取表的白名单。
配置需要抓取的表的名单列表,多个表可以用英文逗号分隔,支持通配符。
可选参数,单击
 显示该参数。
显示该参数。testtable
BlackList
表的黑名单。
配置不需要抓取的表的名单列表,多个表可以用英文逗号分隔,支持通配符。
可选参数,单击
 显示该参数。
显示该参数。-
Multi Partition
是否开启Topic的多分区。
开启之后需要配置“Topic TableMapping”并指定Topic的分区数量, 单表数据将分散在多个分区中。
可选参数,单击
 显示该参数。说明:
显示该参数。说明:- 此配置项为高危配置, 开启后无法保证数据的时间顺序。
- 默认分区数为“5”,若需修改则需登录FusionInsight Manager,选择“集群 > 服务 > CDL > 配置”,在搜索框中搜索“topics.max.partitions”并修改该值为需要修改的分区数,例如,修改值为“10”,保存配置并重启CDL服务。
- 当源端表为分区表且该参数为否时,CDL创建的Topic分区表数量为源端表分区数量+1。
否
Enable Data Encryption
数据写入Kafka是否加密。若该参数值设置为“是”,则需参考CDL任务支持数据加密配置数据加密。
否
Key Name
加密密钥名称。仅“Enable Data Encryption”参数值为“是”时,显示该参数。
test_key
Topic Table Mapping
Topic与表的映射关系。
用于指定某个表的数据发送到指定的Topic中,开启多分区功能后需要配置Topic的分区数,分区数必须大于1。数据过滤时间用于过滤数据,当源端数据的时间小于设定时间时,该数据将会被丢弃,当源端数据的时间大于设定时间时,该数据发送到下游。
单击
 显示该参数。若“Connect With Hudi”或“Multi Partition”选择“是”,则该参数为必填项。
显示该参数。若“Connect With Hudi”或“Multi Partition”选择“是”,则该参数为必填项。testtable
testtable_topic
2023/03/10 11:33:37
表4 Source Hudi作业参数 参数名称
描述
示例
Link
Hudi App使用的Link。
hudilink
Interval
同步Hudi表的时间间隔,单位:秒。
10
Data Filter Time
数据过滤时间。
2023/08/16 11:40:52
Max Commit Number
单次增量视图拉取Commit的最大数量。
10
Hudi表属性配置方式
Hudi表属性配置方式,包括:
- 可视化视图。
- JSON视图。
可视化视图
Hudi Custom Config
Hudi相关的自定义配置。
-
Table Info
同步表的详细配置信息。要求Hudi与DWS的表名一致,且字段类型相同。
{"table1":[{"source.database":"base1","source.tablename":"table1"}],"table2":[{"source.database":"base2","source.tablename":"table2"}],"table3":[{"source.database":"base3","source.tablename":"table3"}]}
Table Info-Section Name
单表标签名称,仅支持数字、字母、下划线。
-
Table Info-Source DataBase
需要同步的Hudi数据库名称。
base1
Table Info-Source TableName
需要同步的Hudi表名。
table1
Table Info-Target SchemaName
数据写入目标数据库的Schema名称。
-
Table Info-Target TableName
数据写入目标数据库的表名称。
-
Table Info-Enable Sink Precombine
目标数据库是否启用预合并,当前仅支持目标库为DWS时启用预合并功能。
该功能用于当新值预合并字段比目标端预合并字段大时,则覆盖目标端已有数据;当新值预合并字段比目标端预合并字段小时,则丢弃新数据。
是
Table Info-Custom Config
Hudi自定义配置。
-
Execution Env
Hudi App运行时需要的环境变量,当前若无可用的ENV,则需先手动创建ENV。
defaultEnv
表5 thirdparty-kafka作业参数 参数名称
描述
示例
Link
已创建的thirdparty-kafka连接。
thirdparty-kafkalink
DB Name
待连接的数据库名称,名称只能由英文字母、数字、下划线和中划线组成,且必须以英文字母开头。
说明:“Datastore Type”为“iot”和“debezium-json”时不支持该参数。
opengaussdb
Schema
待检测数据库的Schema名称。
说明:“Datastore Type”为“iot”和“debezium-json”时不支持该参数。
opengaussschema
Datastore Type
上层源的类型。
- drs-opengauss-json
- ogg-oracle-avro
- drs-oracle-json
- drs-oracle-avro
- iot
- debezium-json
drs-opengauss-json
Avro Schema Topic
Ogg Kafka使用的Schema Topic以JSON格式存储表的Schema。
说明:仅“Datastore Type”为“ogg-oracle-avro”时支持该参数。
ogg_topic
Mode ID
IOT物模型Model ID。可登录IOT服务平台选择“数字孪生 > 模型管理”,在已发布模型列表中单击需要连接的模型名称,查看“ID”获取Model ID。
说明:仅“Datastore Type”为“iot”时支持该参数。
-
Source Topics
数据源Topic,可以包含英文字母、数字、特殊字符(-,_),各Topic应该以英文逗号分隔。
topic1
Tasks Max
允许Connector创建的最大Task的数量,数据库类型的Connector只允许配置为1。
10
Tolerance
容灾策略。
- none表示低容错,即出错后导致Connector任务失败。
- all表示高容错,出错后忽略失败的记录并继续运行。
说明:“Datastore Type”为“iot”时不支持该参数。
all
Data Filter Time
数据过滤的起始时间。
说明:“Datastore Type”为“debezium-json”时不支持该参数。
2022/03/16 14:14:50
Kaka Message Format
Kafka中的消息格式,包括:
- Debezium Json
- CDL Json
说明:仅“Datastore Type”为“drs-opengauss-json”时支持该参数。
CDL Json
Multi Partition
是否开启Topic多分区功能,开启之后需要配置Topic TableMapping并指定Topic的分区数量, 单表数据将分散在多个分区中。
当“Datastore Type”参数值为“ogg-oracle-avro”或“drs-oracle-avro”或“drs-oracle-json”时不支持开启Topic多分区功能。
说明:默认分区数为“5”,若需修改则需登录FusionInsight Manager,选择“集群 > 服务 > CDL > 配置”,在搜索框中搜索“topics.max.partitions”并修改该值为需要修改的分区数,例如,修改值为“10”,保存配置并重启CDL服务。
否
Enable Data Encryption
数据写入Kafka是否加密。若该参数值设置为“是”,则需参考CDL任务支持数据加密配置数据加密。
说明:“Datastore Type”为“debezium-json”时不支持该参数。
否
Key Name
密钥加密密钥名称。仅“Enable Data Encryption”参数值为“是”时,显示该参数。
test_key
Topic Table Mapping
Topic与表的映射关系。
用于指定某个表的数据发送到指定的Topic中,该Topic属于CDL依赖的Kafka,开启多分区功能后需要配置Topic的分区数,分区数必须大于1。若数据源Topic所属Kafka与CDL依赖Kafka为同一Kafka,则“Topic Table Mapping”中的Topic必须和“Source Topics”中配置的Topic名称不相同。
数据过滤时间用于过滤数据,当源端数据的时间小于设定时间时,该数据将会被丢弃,当源端数据的时间大于设定时间时,该数据发送到下游。当“Datastore Type”参数值为“debezium-json”时不支持配置数据过滤时间。
testtable
testtable_topic
2023/03/10 11:33:37
表6 opengauss作业参数 参数名称
描述
示例
Link
已创建的opengauss连接。
opengausslink
Tasks Max
允许Connector创建的最大Task的数量,值为“1”。
1
Mode
任务需要抓取的CDC事件类型。
- insert:插入操作
- update:更新操作
- delete:删除操作
insert、update、delete
dbName Alias
数据库名称。
test
Slot Name
opengauss逻辑复制槽的名称。
不同任务之间槽名不能重名,支持小写字母和下划线。
test_solt
Slot Drop
任务停止时是否删除Slot。
否
Connect With Hudi
是否对接Hudi。
是
WhiteList
待抓取表的白名单。
配置需要抓取的表的名单列表,多个表可以用英文逗号分隔,支持通配符。
testtable
Data Filter Time
数据过滤时间。
-
Multi Partition
是否开启Topic的多分区。
开启之后需要配置“Topic TableMapping”并指定Topic的分区数量, 单表数据将分散在多个分区中。
说明:- 此配置项为高危配置, 开启后无法保证数据的时间顺序。
- 默认分区数为“5”,若需修改则需登录FusionInsight Manager,选择“集群 > 服务 > CDL > 配置”,在搜索框中搜索“topics.max.partitions”并修改该值为需要修改的分区数,例如,修改值为“10”,保存配置并重启CDL服务。
否
Kafka Message Format
Kafka中的消息格式,包括:
- CDL Json
- Debezium Json
CDL Json
Key Management Tool
密钥管理工具。当前仅支持“his_kms”密钥管理工具。
his_kms
Key Environment Information
密钥信息。仅配置了“Key Management Tool”密钥管理工具才支持该参数。
hisIamUrl=https://iam.his-op.xxx.com/iam/auth/token, hisAccount={账号名}, hisSecret={密钥管理->程序密钥}, hisAppid={企业应用ID}, hisEnterprise={企业ID}
Enable Data Encryption
数据写入Kafka是否加密。若该参数值设置为“是”,则需参考CDL任务支持数据加密配置数据加密。
否
Key Name
密钥加密密钥名称。仅“Enable Data Encryption”参数值为“是”时,显示该参数。
test_key
Custom Config
自定义解码配置。
-
Topic Table Mapping
Topic与表的映射关系,表名格式为:Schema名.表名。
用于指定某个表的数据发送到指定的Topic中,开启多分区功能后需要配置Topic的分区数,分区数必须大于1。数据过滤时间用于过滤数据,当源端数据的时间小于设定时间时,该数据将会被丢弃,当源端数据的时间大于设定时间时,该数据发送到下游。
若“Connect With Hudi”选择“是”,则该参数为必填项。
cdlschema.testtable
testtable_topic
2023/03/10 11:33:37
表7 Sink Hudi作业参数 参数名称
描述
示例
Link
已创建的Hudi连接。
hudilink
Path
数据存储路径。
/cdldata
Interval
Spark RDD的执行周期,单位:秒。
1
Max Rate Per Partition
使用Kafka direct stram API时,从每个Kafka分区读取数据的最大速率限制,单位:个/秒, 0表示无限制。
0
Parallelism
写Hudi时的并发数。
100
Target Hive Database
目标Hive的数据库名称。
default
Hudi表属性配置方式
Hudi表属性配置方式,包括:
- 可视化视图
- JSON视图
可视化视图
Hudi表属性全局配置
Hudi侧的全局参数。
-
Hudi表属性配置
Hudi表属性配置。
-
Hudi表属性配置-Source Table Name
源端表名。
-
Hudi表属性配置-Table Type Opt Key
Hudi表类型,包括:
- COPY_ON_WRITE
- MERGE_ON_READ
MERGE_ON_READ
Hudi表属性配置-Hudi TableName Mapping
Hudi表名称,若不设置,则默认与源表名相同。
-
Hudi表属性配置-Hive TableName Mapping
Hudi表同步到Hive的表名映射关系,自定义表名。
-
Hudi表属性配置-Table Primarykey Mapping
Hudi表的主键对应关系。
说明:当数据源为IIOT时,该值推荐配置为“instance_id,thing_id,timestamp”。
id
Hudi表属性配置-Table Hudi Partition Type
Hudi表和分区字段映射关系,如果Hudi表采用分区表,则需要配置表名和分区字段的对应关系,包括“time”和“customized”。
time
Hudi表属性配置-Custom Config
自定义配置。
说明:从MySQL同步数据到Hudi时,需要指定“hoodie.datasource.write.precombine.field”参数,若MySQL的timestamp、datetime类型精度只支持秒级,则不建议指定timestamp、datetime类型及_hoodie_event_time字段作为precombine字段。该功能用于当新值预合并字段比Hudi端预合并字段大时,则覆盖Hudi端已有数据;当新值预合并字段比Hudi端预合并字段小时,则丢弃新数据。
-
Execution Env
Hudi App运行时需要的环境变量,当前若无可用的ENV,则需先参考管理ENV进行创建。
defaultEnv
表8 Sink Kafka作业参数 参数名称
描述
示例
Link
已创建的kafka连接。
kafkalink
表9 DWS作业参数 参数名称
描述
示例
Link
Connector使用的连接。
dwslink
Query Timeout
连接DWS的超时时间,单位:毫秒。
180000
Batch Size
批次写入DWS的数据量。
50
Sink Task Number
单个表写入DWS时的最大并行作业数。
-
DWS Custom Config
自定义配置。
-
表10 ClickHouse作业参数 参数名称
描述
示例
Link
Connector使用的连接。
clickhouselink
Query Timeout
连接ClickHouse的超时时间,单位:毫秒。
60000
Batch Size
批次写入ClickHouse的数据量。
说明:设置单批次写入ClickHouse的数据量时数值尽量大,建议取值范围为:10000~100000。
100000
- 作业参数配置完成后,拖拽图标将作业进行关联,然后单击“保存”,作业配置完成。
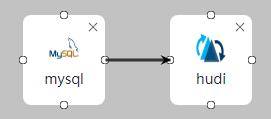
- 在“作业管理”的作业列表中,找到创建的作业名称,单击操作列的“启动”,等待作业启动。
观察数据传输是否生效,例如在MySQL数据库中对作业中指定的表进行插入数据操作,查看Hudi导入的文件内容是否正常。





