
CDL使用说明
CDL是一种简单、高效的数据实时集成服务,能够从各种OLTP数据库中抓取Data Change事件,然后推送至Kafka中,最后由Sink Connector消费Topic中的数据并导入到大数据生态软件应用中,从而实现数据的实时入湖。
CDL服务包含了两个重要的角色:CDLConnector和CDLService。CDLConnector是具体执行数据抓取任务的实例,CDLService是负责管理和创建任务的实例。
CDL支持在CDLService WebUI界面创建数据同步任务和数据比较任务。
数据同步任务
- CDL支持的数据同步任务类型:
表1 CDL支持的数据同步任务类型 数据源
目的端
描述
MySQL
Hudi
该任务支持从MySQL同步数据到Hudi。
Kafka
该任务支持从MySQL同步数据到Kafka。
PgSQL
Hudi
该任务支持从PgSQL同步数据到Hudi。
Kafka
该任务支持从PgSQL同步数据到Kafka。
Hudi
DWS
该任务支持从Hudi同步数据到DWS。
ClickHouse
该任务支持从Hudi同步数据到ClickHouse。
ThirdKafka
Hudi
该任务支持从ThirdKafka同步数据到Hudi。
Kafka
该任务支持从ThirdKafka同步数据到Kafka。
Opengauss
ThirdKafka(DMS/DRS)->Hudi
该任务支持opengauss通过ThirdKafka(DMS/DRS)同步数据到Hudi。
Hudi
该任务支持从Opengauss同步数据到Hudi。
Kafka
该任务支持从Opengauss同步数据到Kafka。

ThirdKafka中的数据源仅支持drs-opengauss-json、drs-oracle-json、drs-oracle-avro、ogg-oracle-avro、iot、debezium-json。
- CDL支持的数据同步任务中数据库版本范围:
- 使用约束:
- 如果需要使用CDL, Kafka的“log.cleanup.policy”参数值必须为“delete”。
- MRS集群已安装CDL服务。
- CDL仅支持抓取非系统表下的增量数据,MySQL、Oracle、PostgreSQL、Opengauss等数据库的内置数据库不支持抓取增量数据。
- 从Hudi同步数据到DWS或ClickHouse任务中,在Hudi中物理删除的数据目的端不会同步删除。例如,在Hudi中执行delete from tableName命令硬删除表数据,目的端DWS或ClickHouse仍存在该表数据。
- MySQL数据库需要开启MySQL的bin log功能(默认情况下是开启的)和GTID功能,CDL不支持抓取表名包含“$”等特殊字符的表。
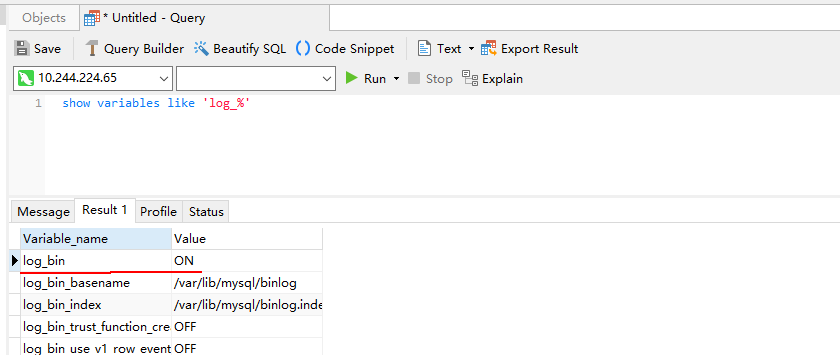
使用工具或者命令行连接MySQL数据库(本示例使用Navicat工具连接),执行show variables like 'log_%'命令查看。
例如在navicat工具选择“File > New Query”新建查询,输入如下SQL命令,单击“Run”在结果中“log_bin”显示为“ON”则表示开启成功。
show variables like 'log_%'
若未开启MySQL的bin log功能,需执行以下操作:
可以通过修改MySQL的配置文件“my.cnf” (Windows系统是“my.ini”)开启,操作如下:
server-id = 223344 log_bin = mysql-bin binlog_format = ROW binlog_row_image = FULL expire_logs_days = 10
修改完成之需要重启MySQL服务使配置生效。
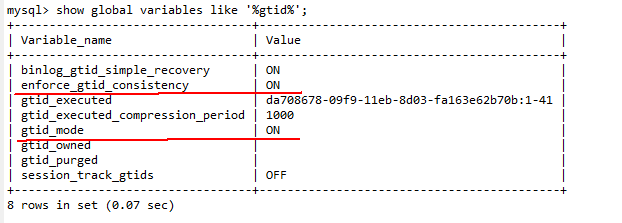
查看MySQL是否开启GTID功能:
使用show global variables like '%gtid%'命令查看是否开启, 具体开启方法参考MySQL对应版本的官方文档。(MySQL 8.x版本开启指导请参见https://dev.mysql.com/doc/refman/8.0/en/replication-mode-change-online-enable-gtids.html)
用户权限设置:
用户执行MySQL任务需要的权限包括SELECT、RELOAD、SHOW DATABASES、REPLICATION SLAVE、REPLICATION CLIENT。
执行以下命令进行赋权:
GRANT SELECT, RELOAD, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user' IDENTIFIED BY '密码';
命令中如果携带认证密码信息可能存在安全风险,在执行命令前建议关闭系统的history命令记录功能,避免信息泄露。
执行以下命令刷新权限:
FLUSH PRIVILEGES;
- PostgreSQL数据库需要修改预写日志的策略。
- 连接PostgreSQL数据库的用户需要具有replication权限和对数据库的create权限,对心跳表要有owner权限。
- CDL不支持抓取表名包含“$”等特殊字符的表。
- PostgreSQL数据库需要有修改“statement_timeout”和“lock_timeout”两个超时参数的设置权限以及查询删除Slot和publication权限。
- “max_wal_senders”建议设置为Slot的1.5倍或2倍。
- 在PostgreSQL表的复制标识是default的情况下,若存在以下场景,需要开启全字段补全功能:
- 场景一:
在源端数据库存在delete操作场景下,delete事件只包含主键信息, 在这时写入到Hudi的delete数据会出现只有主键字段有值, 其他业务字段都是null的情况。
- 场景二:
在数据库单条数据大小超过8k(包括8k)场景下,update事件只包含变更字段,此时Hudi数据中会出现部分字段的值为__debezium_unavailable_value的情况。
相关命令如下,其中:
- 场景一:
- 修改数据库配置文件“postgresql.conf”(默认在PostgreSQL安装目录的data文件夹下)中的参数项“wal_level = logical”。
#------------------------------------------------ #WRITE-AHEAD LOG #------------------------------------------------ # - Settings - wal_level = logical # minimal, replica, or logical # (change requires restart) #fsync = on #flush data to disk for crash safety ... - 重启数据库服务:
#停止 pg_ctl stop #启动 pg_ctl start
- Oracle数据库需要开启预写日志功能。
- 在任务中配置的数据库用户需要具有Oracle数据库的logminer权限,赋权命令如下:
GRANT create session, alter session, select any dictionary, select any transaction, select any table, logmining, execute_catalog_role TO <username>;
- CDL不支持抓取表名包含“$”等特殊字符的表。
- CDL不支持Oracle创建的Schema名称包含特殊字符“#”。
- Oracle任务目前不支持PDB模式。
- Oracle任务同步UPDATE数据需要开启全字段补全功能,命令如下:
ALTER TABLE schema.table_name ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
- 使用工具或者命令行连接Oracle数据库,然后执行如下命令。
SQL> select log_mode from v$database; LOG_MODE ------------ NOARCHIVELOG SQL> shutdown immediate Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount ORACLE instance started. Total System Global Area 1653518336 bytes Fixed Size 2228904 bytes Variable Size 1291849048 bytes Database Buffers 352321536 bytes Redo Buffers 7118848 bytes Database mounted. SQL> alter database archivelog; Database altered. SQL> alter database open; Database altered. SQL> select log_mode from v$database; LOG_MODE ------------ ARCHIVELOG
- 开启Supplemental Logging:
SQL> alter database add supplemental log data; Database altered. SQL> alter database add supplemental log data (primary key) columns; Database altered. SQL> select supplemental_log_data_min from v$database; SUPPLEMENTAL_LOG_DATA_MIN -------------------------- YES SQL> alter system switch logfile; System altered.
- 在任务中配置的数据库用户需要具有Oracle数据库的logminer权限,赋权命令如下:
- DWS数据库前置准备。
同步任务启动前,源表和目标表必须存在,且表结构保持一致。DWS表中“ads_last_update_date”取值为系统当前时间。
- ThirdKafka前置准备。
上层源支持opengauss和ogg,源端Kafka Topic可被MRS集群Kafka消费。
ThirdKafka不支持同步分布式Opengauss数据库数据到CDL。
- ClickHouse前置准备。
用户需要有操作ClickHouse的权限,相关操作请参见ClickHouse用户及权限管理。
- Opengauss数据库需要开启预写日志功能。
- 连接Opengauss数据库的用户需要具有逻辑复制权限。
- 不支持同步Opengauss间隔分区表。
- 源端Opengauss数据库中的表若不存在主键,则不支持delete该表的数据。
- 若源端Opengauss数据库存在delete数据操作,则需要开启全字段补全功能,命令如下:
- 修改数据库配置文件“postgresql.conf”(默认在Opengauss安装目录的data文件夹下)中的参数项“wal_level = logical”。
- 重启Opengauss数据库服务。
CDL同步任务支持的数据类型及映射关系
主要介绍CDL同步任务支持的数据类型,以及源端数据库数据类型跟Spark数据类型的映射关系。
|
PostgreSQL数据类型 |
Spark(Hudi)数据类型 |
|---|---|
|
int2 |
int |
|
int4 |
int |
|
int8 |
bigint |
|
numeric(p, s) |
decimal[p,s] |
|
bool |
boolean |
|
char |
string |
|
varchar |
string |
|
text |
string |
|
timestamptz |
timestamp |
|
timestamp |
timestamp |
|
date |
date |
|
json, jsonb |
string |
|
float4 |
float |
|
float8 |
double |
|
MySQL数据类型 |
Spark(Hudi)数据类型 |
|---|---|
|
int |
int |
|
integer |
int |
|
bigint |
bigint |
|
double |
double |
|
decimal[p,s] |
decimal[p,s] |
|
varchar |
string |
|
char |
string |
|
text |
string |
|
timestamp |
timestamp |
|
datetime |
timestamp |
|
date |
date |
|
json |
string |
|
float |
double |
|
Oracle数据类型 |
Spark(Hudi)数据类型 |
|---|---|
|
NUMBER[P,S] |
Decimal[P,S] |
|
NUMBER[P, 0] P->[1, 9] |
int |
|
NUMBER[P, 0] P->[10, 19] |
long |
|
FLOAT |
double |
|
BINARY DOUBLE |
double |
|
CHAR |
string |
|
VARCHAR |
string |
|
TIMESTAMP |
timestamp |
|
timestamp with time zone |
timestamp |
|
DATE |
timestamp |
|
Oracle数据类型 |
Spark(Hudi)数据类型 |
|---|---|
|
NUMBER(3),NUMBER(5) |
bigint |
|
INTEGER |
decimal |
|
NUMBER(20) |
decimal |
|
NUMBER |
decimal |
|
BINARY_DOUBLE |
double |
|
CHAR |
string |
|
VARCHAR |
string |
|
TIMESTAMP, DATETIME |
timestamp |
|
timestamp with time zone |
timestamp |
|
DATE |
timestamp |
|
Opengauss Json数据类型 |
Spark(Hudi)数据类型 |
|---|---|
|
int2 |
int |
|
int4 |
int |
|
int8 |
bigint |
|
numeric(p,s) |
decimal[p,s] |
|
bool |
boolean |
|
varchar |
string |
|
timestamp |
timestamp |
|
timestampz |
timestamp |
|
date |
date |
|
jsonb |
string |
|
json |
string |
|
float4 |
float |
|
float8 |
duble |
|
text |
string |
|
Oracle Json数据类型 |
Spark(Hudi)数据类型 |
|---|---|
|
number(p,s) |
decimal[p,s] |
|
binary double |
double |
|
char |
string |
|
varchar2 |
string |
|
nvarchar2 |
string |
|
timestamp |
timestamp |
|
timestamp with time zone |
timestamp |
|
date |
timestamp |
|
Oracle Avro数据类型 |
Spark(Hudi)数据类型 |
|---|---|
|
nuber[p,s] |
decimal[p,s] |
|
flaot(p) |
float |
|
binary_double |
double |
|
char(p) |
string |
|
varchar2(p) |
string |
|
timestamp(p) |
timestamp |
|
date |
timestamp |
|
Opengauss数据类型 |
Spark(Hudi)数据类型 |
|---|---|
|
int1 |
int |
|
int2 |
int |
|
int4 |
int |
|
int8 |
bigint |
|
numeric(p,s) |
decimal[p,s] |
|
bool |
boolean |
|
char |
string |
|
bpchar |
string |
|
nvarchar2 |
string |
|
text |
string |
|
date |
date |
|
timestamp |
timestamp |
|
timestampz |
timestamp |
|
json |
string |
|
jsonb |
string |
|
float4 |
float |
|
float8 |
double |
|
real |
float |
|
Spark(Hudi)数据类型 |
DWS数据类型 |
|---|---|
|
int |
int |
|
long |
bigint |
|
float |
double |
|
double |
double |
|
decimal[p,s] |
decimal[p,s] |
|
boolean |
boolean |
|
string |
varchar |
|
date |
date |
|
timestamp |
timestamp |
|
Spark(Hudi)数据类型 |
ClickHouse数据类型 |
|---|---|
|
int |
Int32 |
|
long |
Int64 (bigint) |
|
float |
Float32 (float) |
|
double |
Float64 (double) |
|
decimal[p,s] |
Decimal(P,S) |
|
boolean |
bool |
|
string |
String (LONGTEXT, MEDIUMTEXT, TINYTEXT, TEXT, LONGBLOB, MEDIUMBLOB, TINYBLOB, BLOB, VARCHAR, CHAR) |
|
date |
Date |
|
timestamp |
DateTime |
数据比较任务
数据比对即是对源端数据库中的数据和目标端Hive中的数据进行数据一致性校验,如果数据不一致,CDL可以尝试修复不一致的数据。相关操作请参见创建CDL数据比较任务作业。




