
更新时间:2024-11-29 GMT+08:00
Solr富文本索引
操作场景
Solr在webUI界面上支持富文本索引。针对存储在本地磁盘上的文本格式(例如:csv、xml、eml、html、txt、doc、pdf、xls、xlsx、jpg、png、tif等),可以在配置好“solrconfig.xml”后输入一定的索引参数进行索引建立。
前提条件
Solr服务工作正常,配置了支持富文本索引的requestHandler。
操作步骤
- 确认在“solrconfig.xml”中对富文本进行Handler配置。
<!-- Solr Cell Update Request Handler http://wiki.apache.org/solr/ExtractingRequestHandler --> <requestHandler name="/update/extract" startup="lazy" class="solr.extraction.ExtractingRequestHandler" > <lst name="defaults"> <str name="lowernames">true</str> <str name="uprefix">ignored_</str> <!-- capture link hrefs but ignore div attributes --> <str name="captureAttr">true</str> <str name="fmap.a">links</str> <str name="fmap.div">ignored_</str> </lst> </requestHandler>
- 按照下图所示的方式进行索引参数填写。
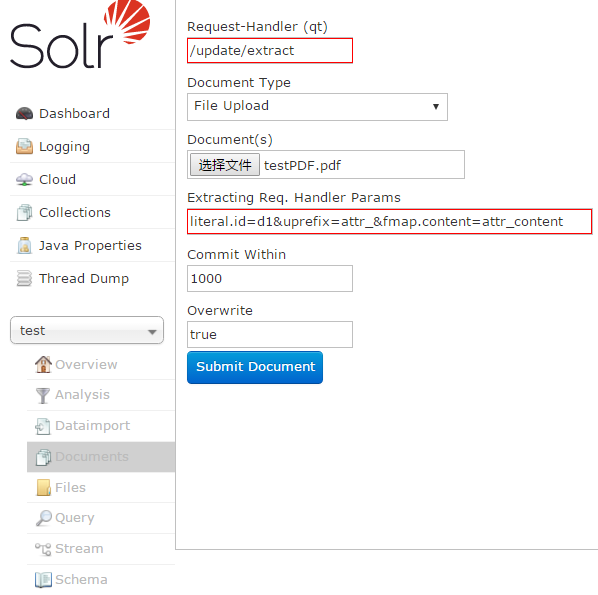

Handler参数:literal.id=d1&uprefix=attr_&fmap.content=attr_content
- literal.<fieldname>=<value>:表示给定某个field一个值;如果这个字段是multivalued的,那么该值也可以是multivalued类型的。
- uprefix=<prefix>:表示对所有在schema中没有定义的字段添加前缀prefix,这种方式在与动态字段定义结合使用时非常有用;例如,<dynamicField name="ignored_*" type="ignored"/>将会对所有被Tika解析出来的未知字段进行自动忽略。
- fmap.<source_field>=<target_field>:表示把一个字段映射到另一个字段;例如fmap.content=text将会把Tika解析出来的“content”字段自动的映射到“text”字段。
- 提交索引命令,在相应的collection下进行Query操作,可以查询到2中导入的文本索引信息。
RestAPI:
Request URL: https://ip:solr_port/solr/collName/update/extract?commitWithin=1000&boost=1.0&overwrite=true&wt=json&literal.id=d3&uprefix=attr_&fmap.content=attr_content Request Method:POST Request Headers: Accept:application/json, text/plain, */* Accept-Encoding:gzip, deflate, br Accept-Language:zh,en;q=0.8,zh-CN;q=0.6 Connection:keep-alive Content-Length:400378 Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryW45dtKs8K3BymOjP Request Payload ------WebKitFormBoundaryW45dtKs8K3BymOjP Content-Disposition: form-data; name="file"; filename="text.docx" Content-Type: application/vnd.openxmlformats-officedocument.wordprocessingml.document ------WebKitFormBoundaryW45dtKs8K3BymOjP--
父主题: Solr业务常见操作




